平顶山住房和城乡建设局网站c 微信网站开发
前言
相信大家在用Jenkins持续集成+ant自动构建+jmeter接口测试+pytest代码.xml文件转化+allure测试报告为一体的接口自动化测试构建过程中,都会遇到Jenkins里打开allure报告页面后空白显示无数据问题这一现象级问题,今天Darren洋就给大家分享一下如何讲讲allure测试报告生成逻辑及解决allure测试报告显示无数据这一问题过程。
一、Jenkins里配置jdk
在工具配置中配置好jdk安装包地址(我这里因为是window环境所以直接配置的本地jdk安装地址)。
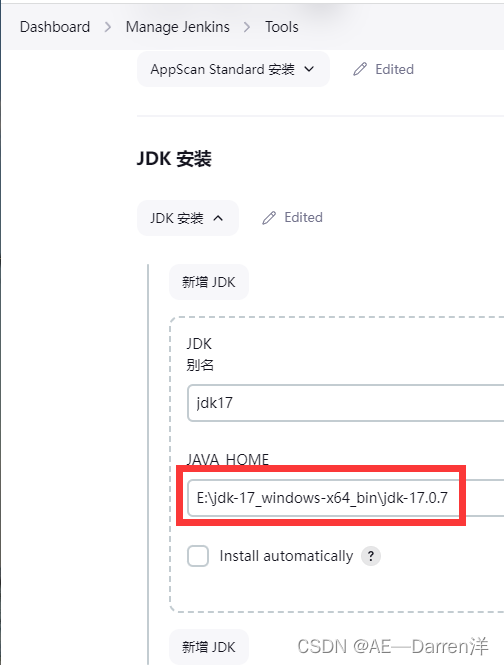
二、Jenkins里配置allure
(1)安装好配置插件
在Jenkins中安装好Allure Jenkins Plugin这一配置插件。

(2)配置allure安装包
在工具配置中配置好allure栏以及jdk栏中的安装包地址(我这里因为是window环境所以直接配置的本地地址)。这里本地要提前下载好allure的安装包哦!!!