dedecms网站模板下载python合适做网站吗
什么是tools
大模型是无所不能的,如果遇到无法处理的事情怎么办?大模型提供了Funcationcall机制来弥补这一问题,Funcationcall (tools)工具调用(也称为函数调用)是 AI 应用程序中的一种常见模式,允许模型与一组 API 或工具进行交互,从而增强其功能。简单来说,工具调用主要帮AI做两件事:
工具主要用于:
-
信息检索。AI本身的知识有限,但通过工具可用于从外部来源(例如数据库、Web 服务、文件系统或 Web 搜索引擎)检索信息。其目标是增强模型的知识,使其能够回答原本无法回答的问题。因此,它们可用于检索增强生成 (RAG) 场景。例如,可以使用工具检索给定位置的当前天气、检索最新新闻文章或查询数据库中的特定记录。
-
执行任务:此类别中的工具可用于在软件系统中执行任务,例如发送电子邮件、在数据库中创建新记录、提交表单或触发工作流。其目标是自动化原本需要人工干预或明确编程的任务。例如,可以使用工具为与聊天机器人交互的客户预订航班、在网页上填写表单,或在代码生成场景中基于自动化测试 (TDD) 实现 Java 类。
需要注意的是:虽然我们说AI"调用工具",但实际上AI只是告诉应用程序"我想做什么",真正的执行是由背后的程序完成的。AI永远接触不到实际的API——这种设计既安全又可靠。
Spring AI 提供了便捷的 API 来定义工具、解析来自模型的工具调用请求以及执行工具调用。以下部分概述了 Spring AI 中的工具调用功能,它的工作流程如下
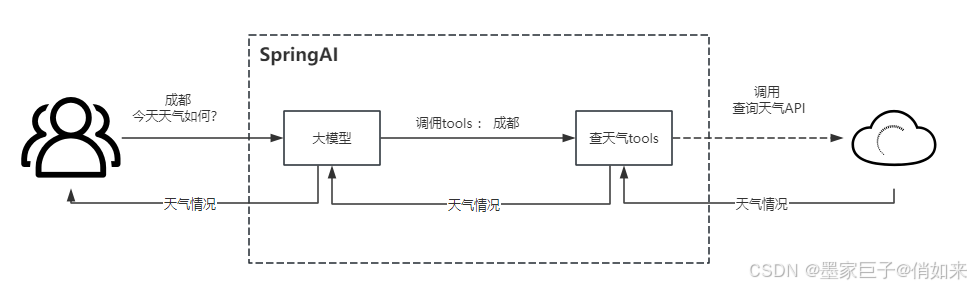
但是不是所有的模型都支持 FunctionCalling 目前支持Function Calling的模型有
- OpenAI系列:GPT-4 Turbo、GPT-3.5 Turbo
- Google Gemini:Gemini 1.5 Pro
- Anthropic Claude:Claude 3 Opus
- 开源模型:Llama 3(需配置工具调用插件)
- 国内模型:文心一言4.0、通义千问Max
定义工具
让我们看看如何在 Spring AI 中开始使用工具调用。我们来实现一个小案例:查询指定城市的天气情况,要实现天气查询那么必须先要找到一个合适的天气查询的API接口,天气查询我使用的是百度的天气查询接口,你需要百度开发平台 , 创建一个应用,申请一个key,地址:https://lbsyun.baidu.com/apiconsole/key 。 天气查询接口文档查看:https://lbsyun.baidu.com/faq/api?title=webapi/weather/base 。我使用的是国内天气查询
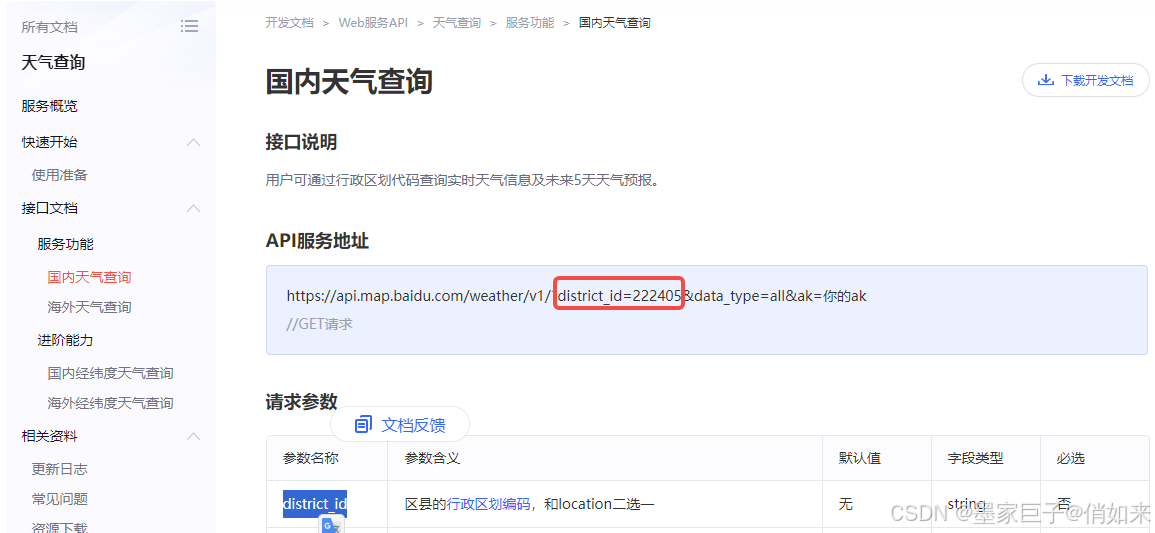
因为他需要通过城市的编码进行查询,所以我简单定义了一个Map把城市名和行政区编码映射起来。当我们向大模型提问的时候大模型会拿到消息中的城市,调用weather方法,方法中通过 城市拿到编码后,调用百度天气接口查询天气。
接着我们在配置类中定义一个Tools工具如下,我们通过WebClient 调用百度地图的API接口查询天气
@Component
@Slf4j
public class AgentTool {HashMap<String,Integer> code = new HashMap<>(){{put("成都",510100);}};@Tool(name = "查询该城市的天气")public String weather(@ToolParam(required = true,description = "城市") String city){String url = "https://api.map.baidu.com/weather/v1/?district_id="+code.get(city)+"&data_type=all&ak=xxxbZlQSEtuWKqvV4jx2XgeimzlDBsx";log.info("查询天气url = {}",url);WebClient client = WebClient.create();String response = client.get().uri(url).retrieve().bodyToMono(String.class).block();System.out.println(response);return response;}
}- 这里的HashMap是维护地址编码,大模型会把城市传入给我们,我们通过城市获取地址编码后传给天气查询接口
- ak= : 你需要去百度地图后台,申请一个自己的APIkey
因为要使用到http工具,我多用了一个 - @Tool(name = “查询该城市的天气”) : 为工具指定它的作用
- @ToolParam(required = true,description = “城市”) :工具方法的参数
配置ChatClient
现在我们有了查询天气的工具了,接着我们要把工具调用的能力指定给ChatClient,具体配置如下
@Beanpublic ChatClient weatherClient(OpenAiChatModel model, AgentTool agentTool){return ChatClient.builder(model)//通过提示词告诉大模型需要去调用tools查询天气.defaultSystem("调用tool为用户查询指定的城市的天气,并把城市city,天气weather以json格式输出")//日志打印的增强器.defaultAdvisors(new SimpleLoggerAdvisor())//指定工具.defaultTools(agentTool).build();}
我这里定义了一个weatherClient , 通过defaultSystem 系统提示词明确的告诉大模型需要调用工具查询天气,然后通过 defaultTools(agentTool) 来指定工具。
测试Tools调用
接下来我们编写controller,让它帮我们调用tools实现天气查询,代码如下
@RestController
@RequiredArgsConstructor
public class AgentController {private final ChatClient chatClient;private final ChatClient ollamaClient;private final ChatClient weatherClient;@RequestMapping(value = "/ai/chat/weather")public Weather weather(@RequestParam String prompt,@RequestParam String chatId){return weatherClient.prompt().user(prompt).advisors(p->p.param(ChatMemory.CONVERSATION_ID,chatId)).call().entity(Weather.class);}...
这里和之前有一个区别,就是我使用了call().entity(Weather.class)来返回结果,其实很简单就是让SpringAI把JSON结果转对象返回而已。Weather对象中我仅仅定义了city,weather两个String类型的字段。
测试效果如下:
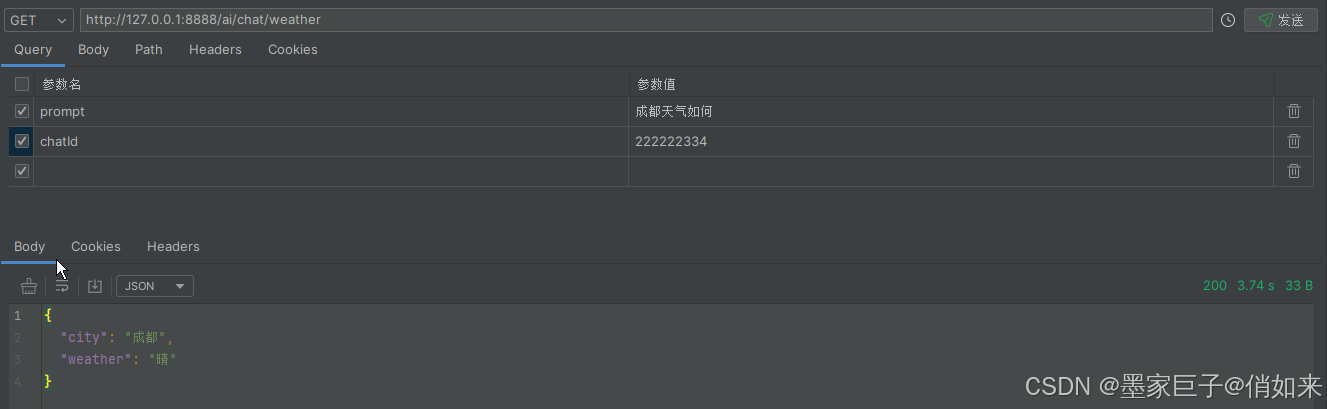
案例成功,这里不妨来大胆猜想一下,这里我们是查询天气,那么在实际的项目中我们可不可以让大模型帮我们去查询数据库呢?比如:挂号系统让大模型根据用户的电话号码查询挂号单,根据科室查询号源, 订票系统让大模型帮我们查询机票余量,根据用户信息实现自动订票等等。这样是不是就可以以对话的方式完成传统的CRUD业务流程呢。
总结
文章到这里就结束了,本文介绍了什么是tools, 以及它的作用和场景,并通过天气查询案例来演示了在SpingAI中tools的实际使用。如果文章对你有帮助就请点赞/关注/收藏吧,你的鼓励是我最大的动力哦!!!