海尔网站建设的优势服装厂做1688网站效果好不好
文章目录
- 一、Mysql日志管理
- 1.mysql日志
- 2.日志种类
- 3.日志的查询
- 4.配置日志文件
- 二、Mysql备份与分类
- 1.数据备份的重要性
一、Mysql日志管理
1.mysql日志
Mysql的日志默认保存位置为/usr/local/mysql/date,Mysql的日志配置文件为/etc/my.cnf,里面有一个【mysqld】项
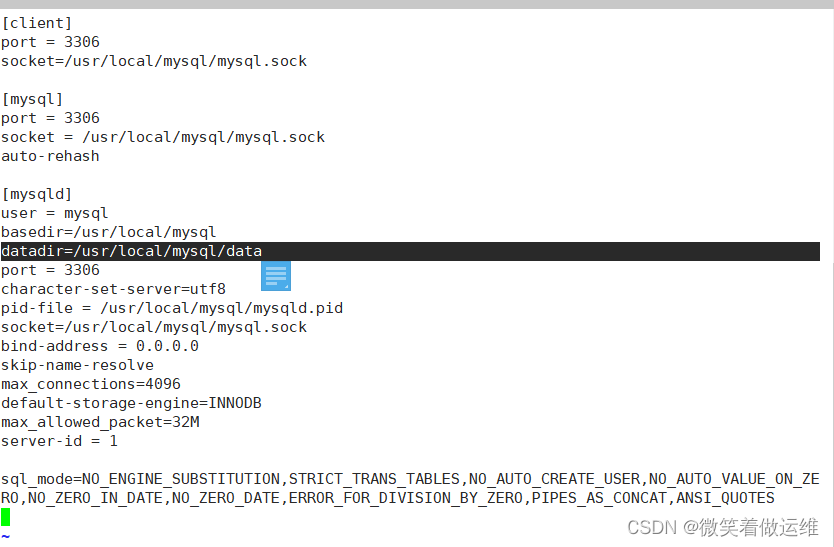
2.日志种类
错误日志
用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启
vim /etc/my.cnf
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
通用查询日志
用来记录MySQL的所有连接和语句,默认是关闭的
vim /etc/my.cnf
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
二进制日志
用来记录所有更新了数据或者已经潜在更新了数据的语句,记录了数据的更改,可用于数据恢复,默认已开启
vim /etc/my.cnf
#也可以 log_bin=mysql-bin
log-bin=mysql-bin
慢查询日志
用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,以便于优化,默认是关闭的
vim /etc/my.cnf
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5
3.日志的查询
#登入mysql
mysql -u root -p[密码]#查看通用查询日志是否开启
show variables like 'general%'; #查看二进制日志是否开启
show variables like 'log_bin%'; #查看慢查询日功能是否开启
show variables like '%slow%'; #查看慢查询时间设置
show variables like 'long_query_time'; #在数据库中设置开启慢查询的方法
set global slow_query_log=ON;
4.配置日志文件
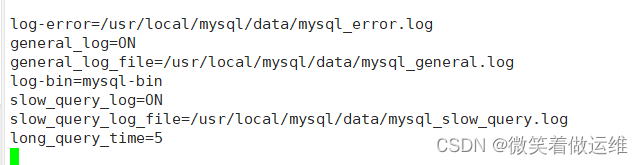
1. #修改my.cnf配置文件#错误日志
log-error=/usr/local/mysql/data/mysql_error.log
#通用查询日志
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
#二进制日志
log-bin=mysql-bin
#慢查询日志
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=52. #重新mysql服务
systemctl restart mysqld.service
#登入mysql
mysql -u root -p[密码]#查看通用查询日志是否开启
show variables like 'general%'; #查看二进制日志是否开启
show variables like 'log_bin%'; #查看慢查询日功能是否开启
show variables like '%slow%'; #查看慢查询时间设置
show variables like 'long_query_time'; #在数据库中设置开启慢查询的方法
set global slow_query_log=ON;


二、Mysql备份与分类
1.数据备份的重要性
备份数据的主要目的就是灾难恢复
在生产环境中,数据的安全性至关重要
任何数据的丢失都可能造成严重的后果
2、造成数据丢失的原因
程序错误
人为操作错误
运算错误
磁盘故障
灾难(地震、火灾)和盗窃
3、数据库备份的分类
3.1 从物理与逻辑的角度划分
①.物理备份:对数据库操作系统的物理文件(如数据文件、日志文件等)备份
物理备份的方法:
冷备份(脱机备份):是在关闭数据库的时候进行的
热备份(联机备份):数据库处于运行状态,依赖于数据库的日志文件
温备份:数据库锁定表格(不可写入但是可以读)的状态下进行备份操作
②.逻辑备份:对数据库逻辑组件(如:表等数据库对象)的备份
从数据库的备份策略角度划分
完全备份:每次只对数据库进行完整的备份
差异备份:备份自从上次完全备份之后修改的文件
增量备份:只有在上次完全备份或者增量备份后被修改的文件才会被备份
物理冷备与恢复
备份时数据库处于关闭状态,直接打包数据库文件
备份速度快,恢复时也是最简单的
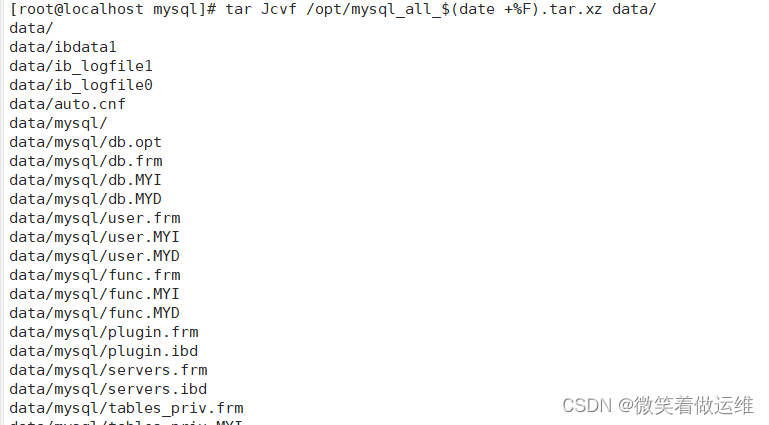
1. #关闭mysql,备份data目录
systemctl stop mysqld
yum -y install xz
cd /usr/local/mysql
#压缩备份data目录
tar Jcvf /opt/mysql_all_$(date +%F).tar.xz data/
2. #登录mysql,删除school库
systemctl start mysqld.service
mysql -u root -pabc123
show databases;
use wujian;
drop database wujian;
3. #解压之前备份的数据库data目录,不用删除原目录,会自动替换
cd /opt
ls
cd /usr/local/mysql
tar Jxvf /opt/mysql_all_2023-05-13.tar.xz -C ./
4. #重启服务查看被删除的库
删除wujian数据库


