建设机械网站平台网站推广外链
相信大家在做自动化测试过程中,都会用到自动化测试环境,目前最常见的就是通过容器化方式部署自动化测试环境,但对于一些测试小白,不是很会搭建持续集成环境,特别是从0-1的过程,需要自行搭建很多依赖环境,今天就给大家介绍一下如何在jenkins搭建allure,以及allure所依赖的环境。
一、安装JDK
1. 下载jdk
方式一:直接通过命令下载指定版本
方式二:在官方下载,传输到Linux系统
2. 解压jdk
tar -zxvf jdk-19_linux-x64_bin.tar.gz
3. 配置java环境变量
3-1 若是jenkins容器中无vim命令,需要安装vim
apt-get update
apt-get install vim
3-2 编辑配置文件,添加环境变量
vim /etc/profile

3-3 编辑后保存退出,使用如下命令
source /etc/profile
3-4 验证是否配置成功

二、安装allure
1. 解压allure
1-1 将文件从宿主机复制到容器内部,并解压
复制allure安装包
docker cp /var/allure-2.21.0.tgz jenkins:/usr/local/src
解压文件
tar -zxvf allure-2.21.0.tgz
1-2 赋予文件夹所有内容最高权限
chmod -R 777 allure # allure安装所在目录
2. 配置环境变量
2-1 配置方式和jdk类似,编辑环境变量,并保存
vim /etc/profile
# 编辑内容
export PATH=$PATH:/usr/local/src/allure/bin # allure的安装目录

2-2 使环境变量生效
source /etc/profile
2-3 验证是否配置成功

备注:若是遇到每次进入jenkins容器中,设置的环境变量没有生效,每次都需要执行source命令,可通过在配置文件添加如下命令,即可解决
# 编辑bashrc文件
vim ~/.bashrc
# 添加source命令,并保存
source /etc/profile
# 重启容器,即可解决该问题
docker restart jenkins
三、配置allure
1. 安装allure插件
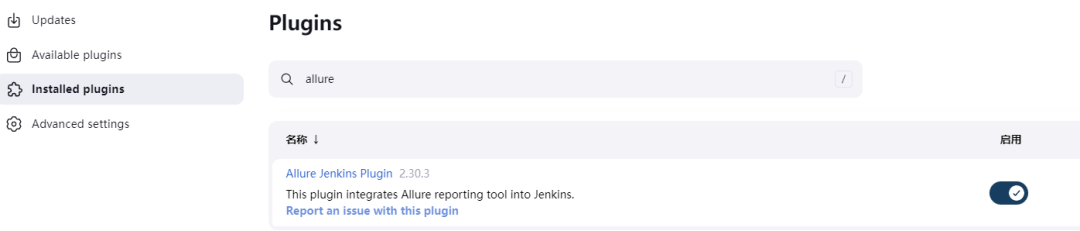
在jenkins的"系统管理"->"Plugins"中的"Available plugins"列表中搜索:allure,然后点击:install,安装后可以在"Installed plugins"中查看该插件,显示"启用"即为安装成功
2. 配置JDK环境
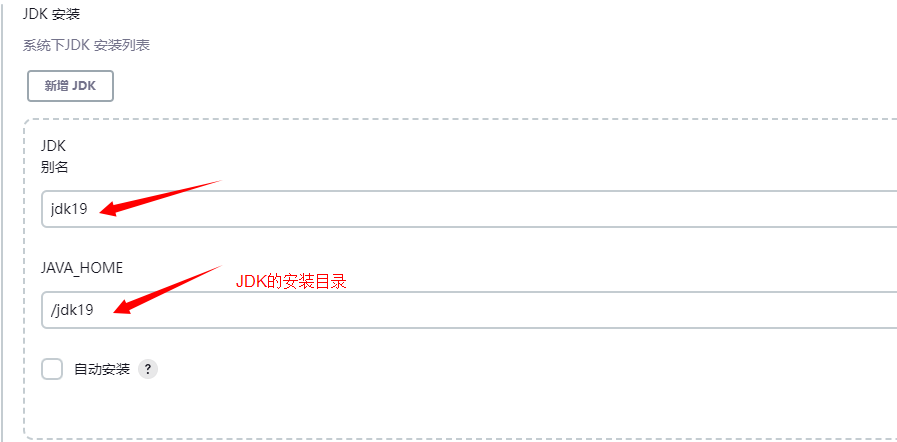
在jenkins的"系统管理"->"全局工具配置"中配置JDK
3. 配置allure环境
在jenkins的"系统管理"->"全局工具配置"中配置allure

4. 添加allure构建后操作
4-1 在项目的"配置"->“构建后操作"添加"Allure Report”

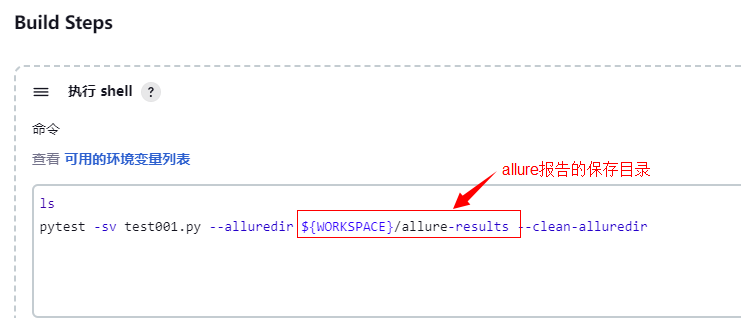
4-2 在"Build Steps"中添加allure报告文件的保存目录,必须和"构建后操作"中allure的Path目录一致
5. 实现效果
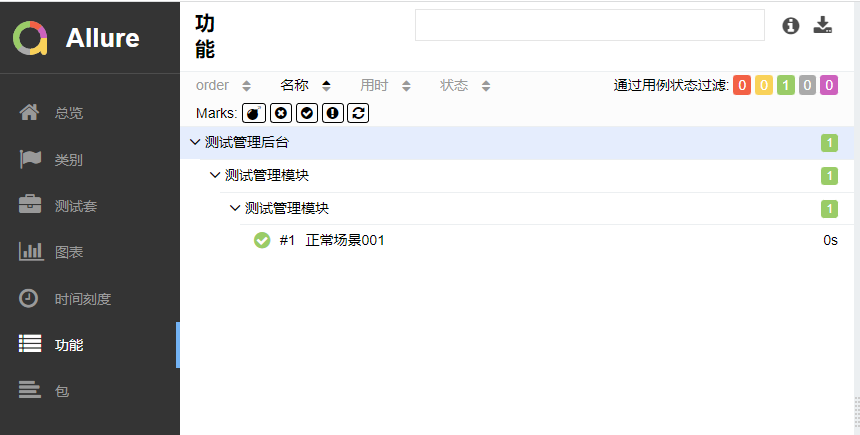
5-1 在项目工作区中点击“立即构建按钮”,然后即可查看生成的allure报告

6. 修改jenkins所在时区
说明:若是发现jenkins的时间和实际的时间不一致,大概率是时区的问题,所以需要修改jenkins容器中的时区
6-1. 使用root身份进入容器
docker exec -it -u root jenkins /bin/bash
6-2 查看容器的时区,结果发现时区是ETC/UTC

6-3 修改容器的时区为:Asia/Shanghai

6-4 退出容器内部,重启容器
docker restart jenkins
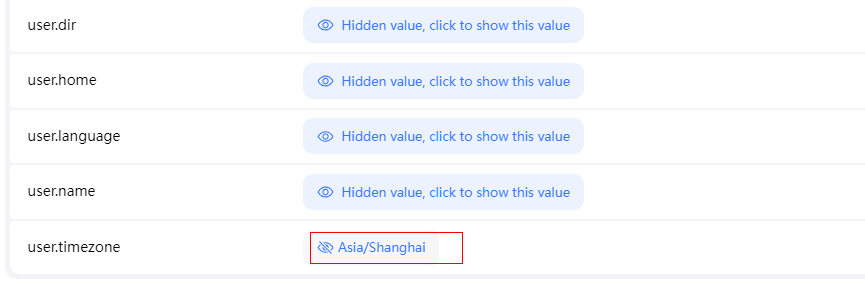
6-5 在jenkins系统管理->系统属性->user.timezone字段变为:Asia/Shanghai,即为成功
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
