PHP网站开发方向成都定制公交app
图扑软件明星产品 HT for Web 是一套纯国产化独立自主研发的 2D 和 3D 图形界面可视化引擎。HT for Web(以下简称 HT)图元的样式由其 Style 属性控制,并且不同类型图元的 Style 属性各不相同。为了方便查询和理解图元的 Style 属性,以及更加便捷地应用和理解每个属性的作用,图扑 HT 提供了风格手册。
风格手册可以帮助开发人员在样式设定过程中快速查找所需属性,并了解其用途和影响范围。通过风格手册,开发人员可以更加高效地调整图元的样式,减少查找和理解样式属性的工作量。
风格手册界面介绍
风格手册界面布局比较简单,可以分为工具栏、2D/3D 视图区域、属性树和属性面板四个部分。
工具栏中有四个按钮:
• 按钮一:切换到 2D 图纸。
• 按钮二:切换到 3D 场景。
• 按钮三:刷新图纸/场景。
• 按钮四:在新窗口中打开。
2D/3D 视图区域:用于展示图纸或者场景的内容。
属性树:属性树分为属性搜索框和属性树两个部分。
属性面板:分为“属性描述”和“获取属性”两个 Tab 内容,可以进行切换展示。

功能介绍
属性树
右侧的属性树可以分为属性检索和属性树两个部分。
1.属性检索支持属性名和属性的模糊搜索,为开发人员提供便捷的属性查询功能。

2.属性树按照特性进行分类显示,每一个属性都显示了四个内容:属性、属性名、属性值的类型和默认值。让开发人员能更加便捷地了解属性。为了使用上能更加方便,属性树还增加了双击复制属性的功能。

属性面板
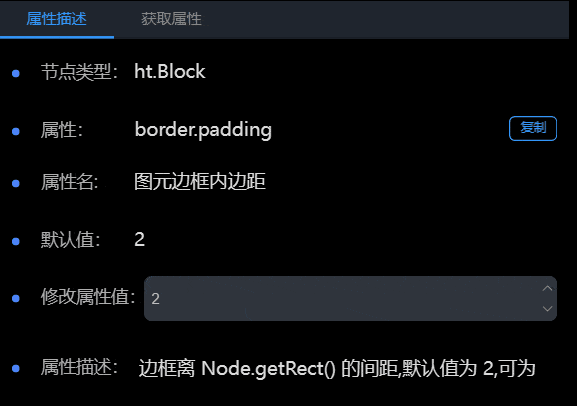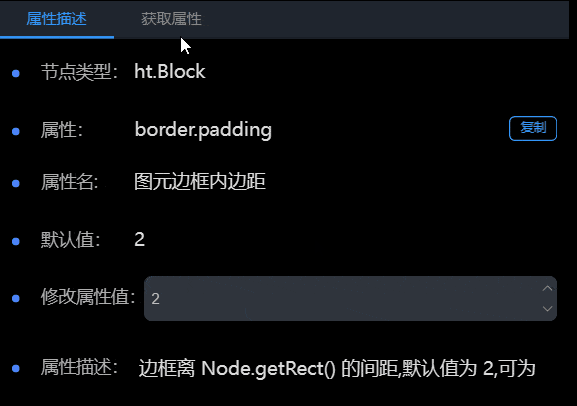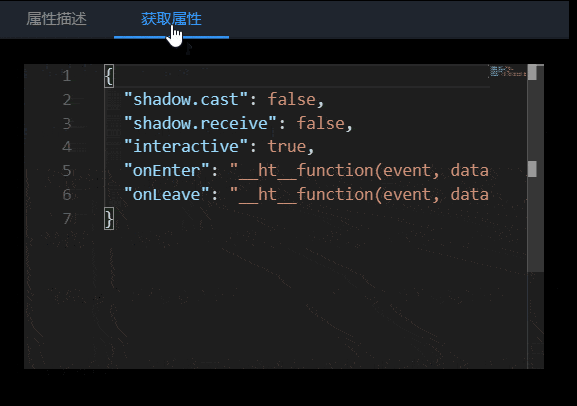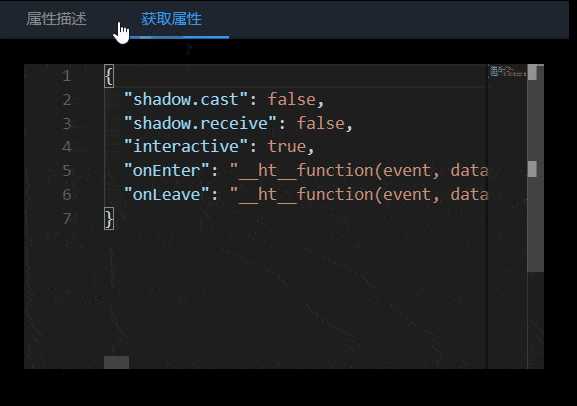
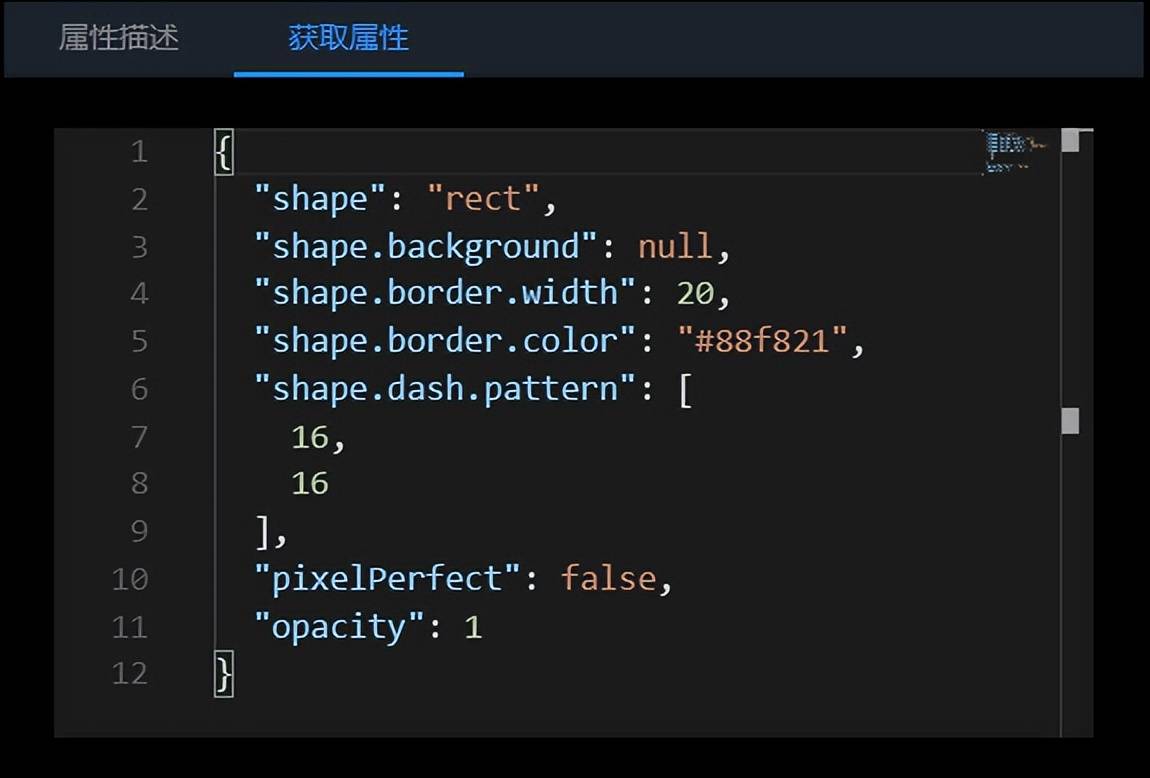
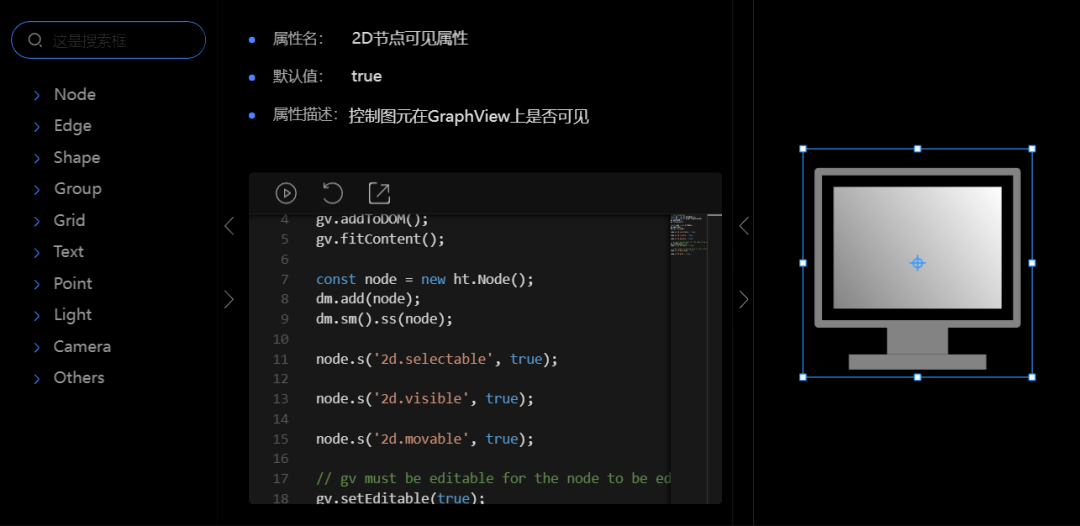
面板分为两个部分:属性描述和获取属性。其中属性描述 Tab 页分为:节点类型、属性、属性名、默认值、修改属性值和属性描述六个内容。在获取属性 Tab 中可以看到当前节点上设置的所有属性。
选中属性树某个属性,属性面板会自动弹出,显示当前选中属性的属性描述。点击 2D/3D 视图的空白区域时,属性面板就会自动收起。
属性描述
1.属性:属性描述的“属性”右侧有“复制”按钮,点击可以复制属性。

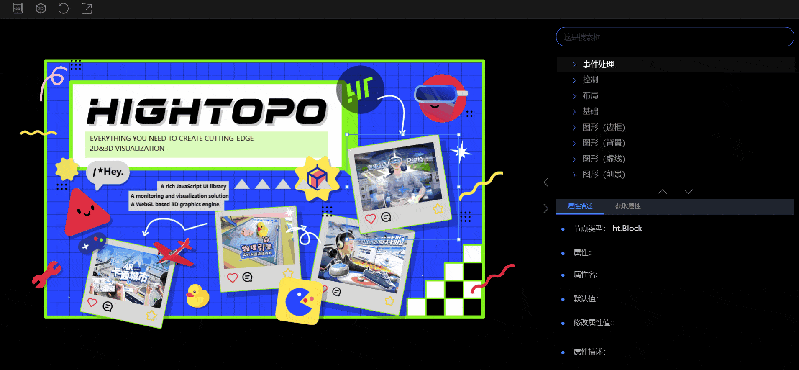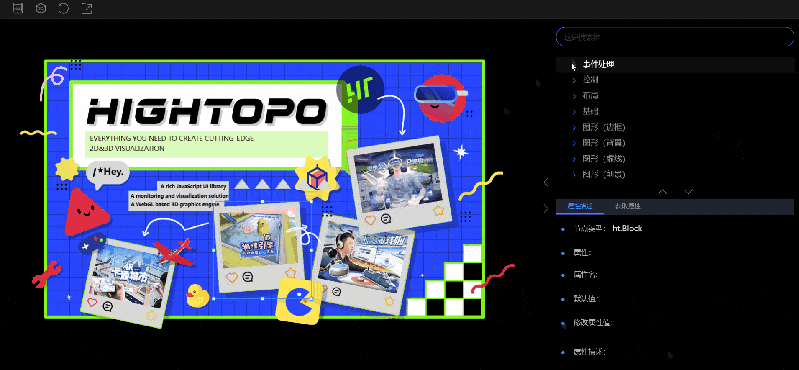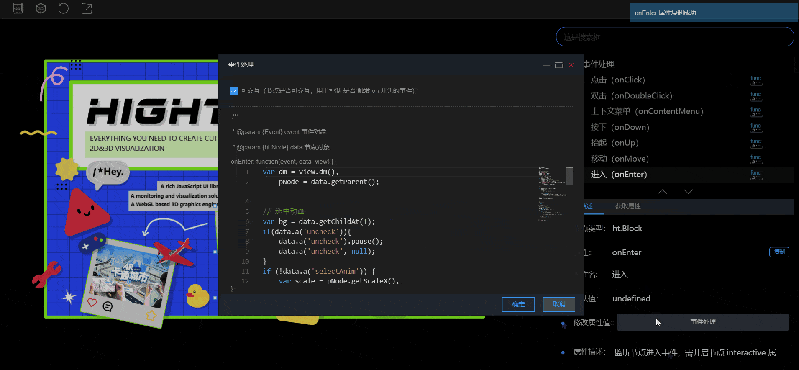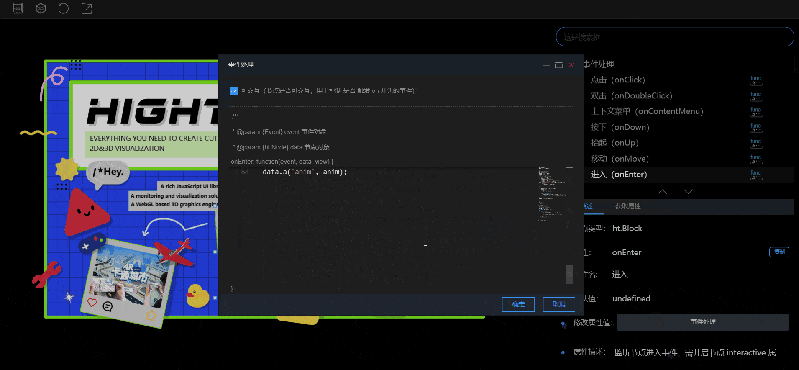
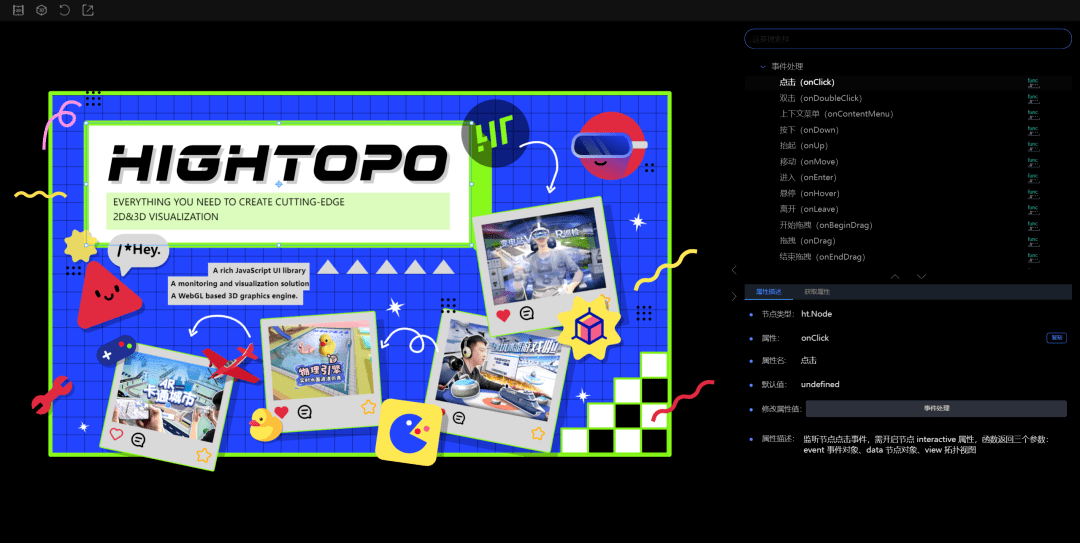
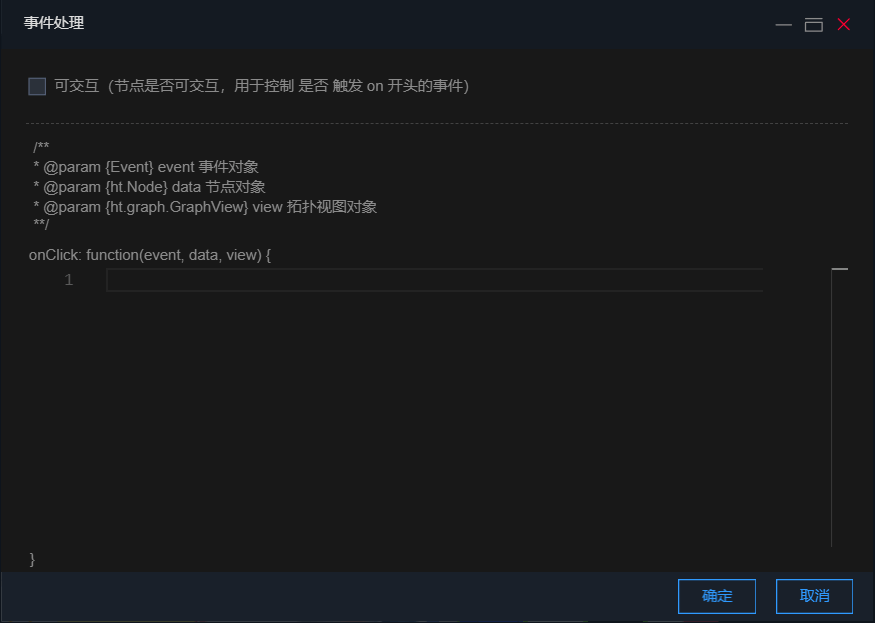
2.修改属性值:属性描述中有修改属性值的功能,会根据不同类型的数据,显示不同的编辑框。比较特殊的两种类型:函数类型(例如:onClick)和数组类型(例如:shape.dash.pattern),修改属性值的位置会显示按钮,点击按钮之后会弹出编辑框,需要在编辑框中进行设置。
- 如果选中的是事件处理类型下的属性(函数类型),“属性描述”中会显示事件处理按钮,点击按钮会弹出事件处理弹窗,在这个弹窗中可以编辑事件代码。
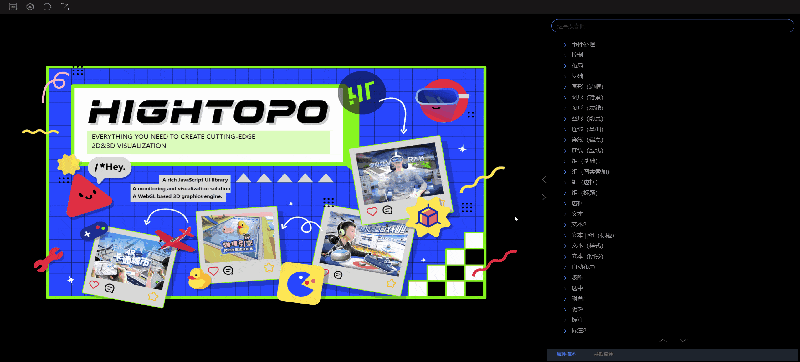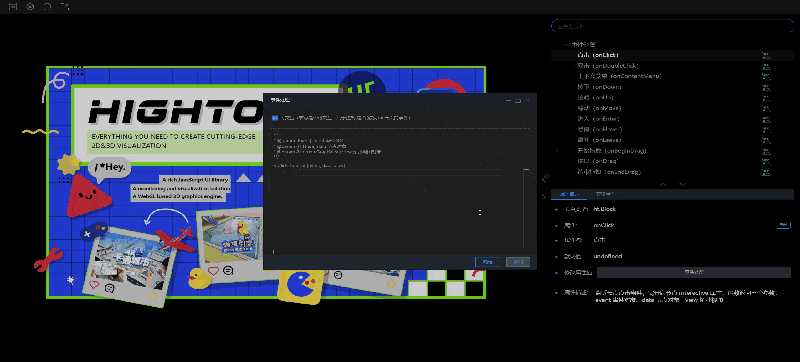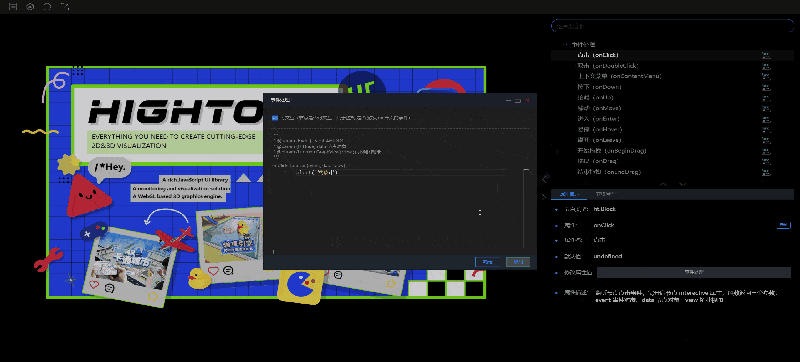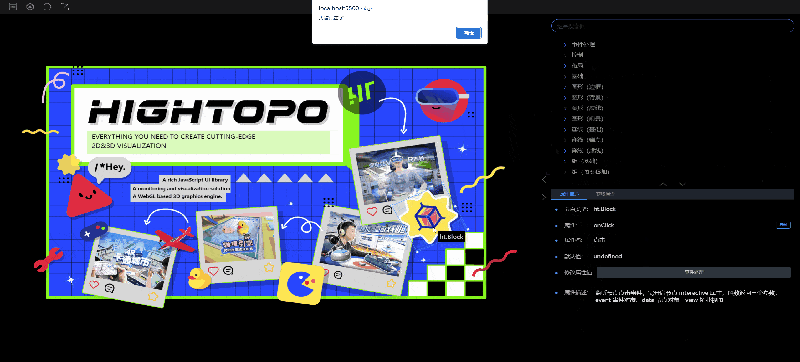
- 如果选中的属性的属性值类型为数组,“属性描述”中显示编辑按钮,点击按钮会出现编辑框,需要在这个弹窗中编辑数据。
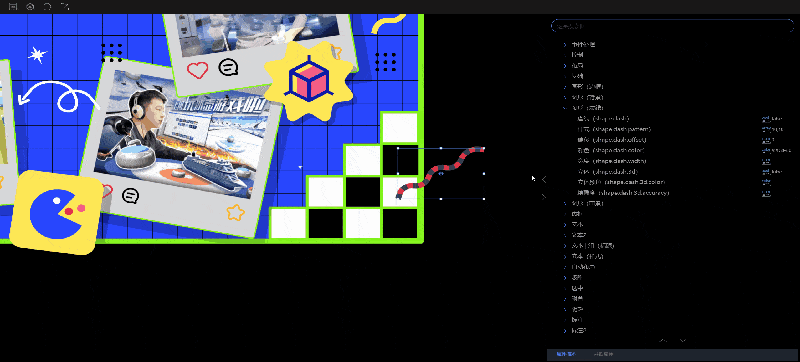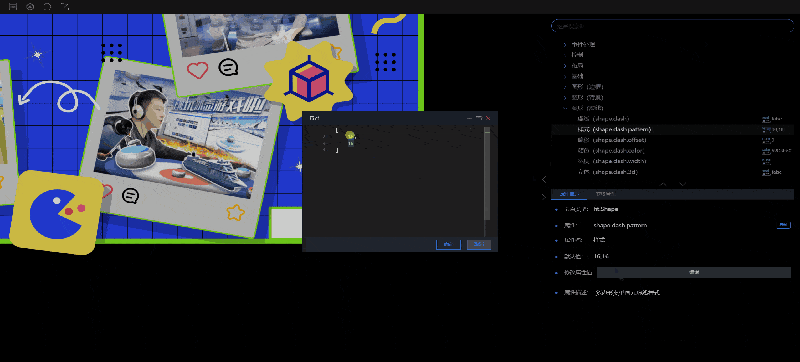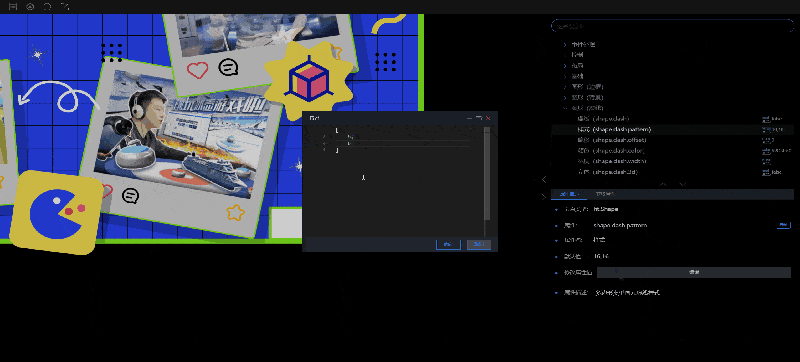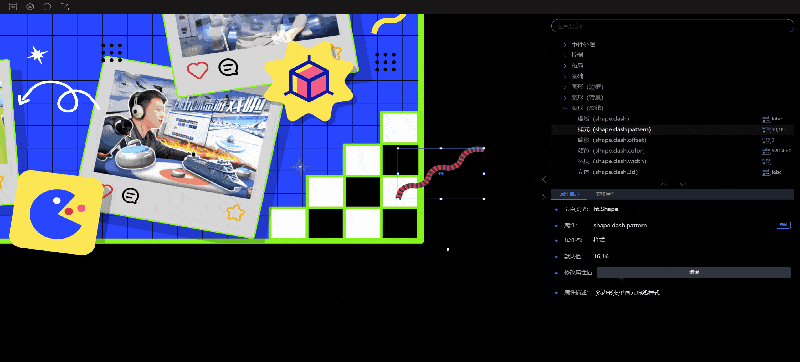
获取属性
风格手册的获取属性的功能,会实时获取节点上的属性,并显示出来。通过实时获取属性的功能,开发人员就可以快速查看当前节点的属性设置情况。
工具栏
1.2D/3D 切换按钮:为了提供更直观的了解属性效果,风格手册内置了 2D 图纸和 3D 场景,并提供了 2D/3D 切换按钮。用户可以通过点击切换按钮,方便地在场景和图纸之间切换,以便进行属性的操作和观察。

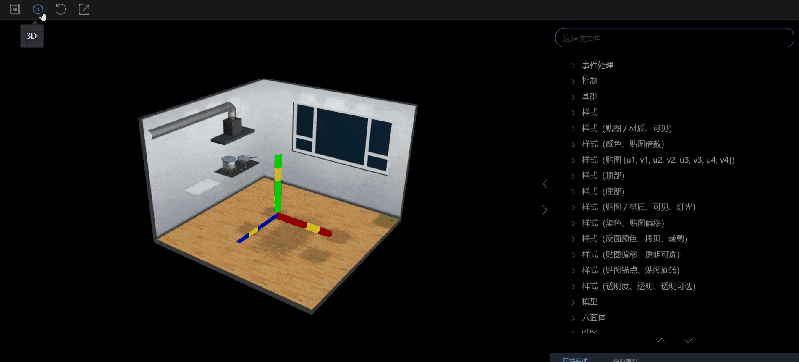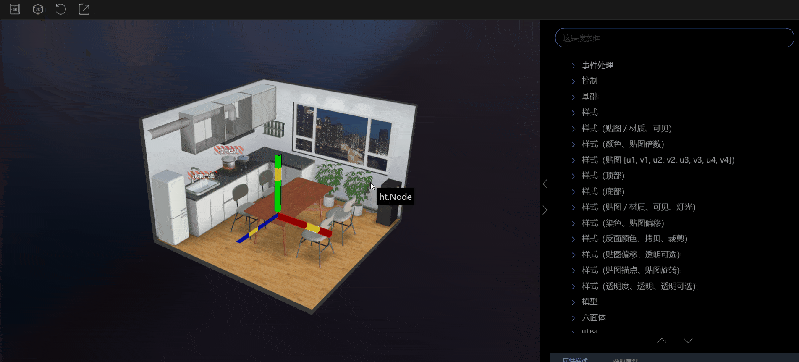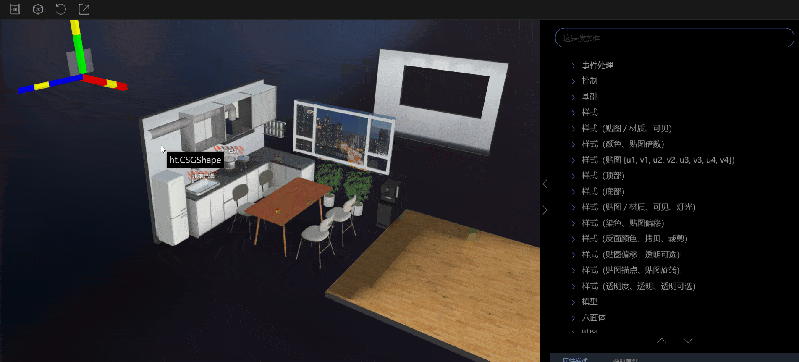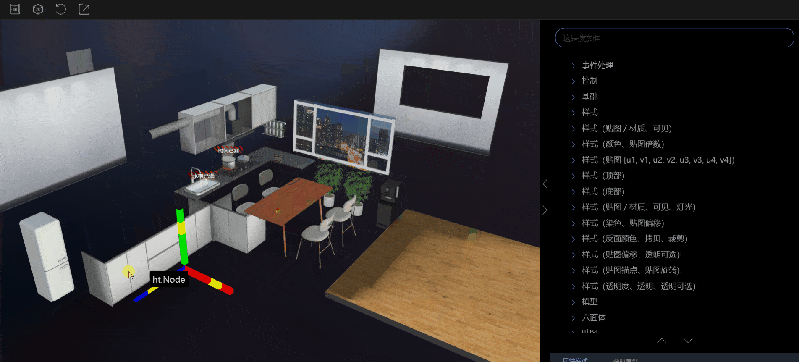
2.刷新视图:在视图区域对节点进行调整,或者在属性描述面板中修改属性值之后,需要恢复到初始状态时,可以点击刷新视图的按钮,视图就会恢复到初始状态。

3.在新窗口中打开:可以在新窗口中打开风格手册。
视图区域
视图区域分为 2D 图纸部分和 3D 场景部分。默认显示的是 2D 视图,可以通过工具栏中的按钮进行切换。用户可以直接对视图区域的内容进行操作,在属性描述->修改属性值中修改的内容也会实时地在视图区域生效,这让使用者能更加直观地了解到设置属性的不同属性值产生的效果。
风格手册在 2D 视图上内置了很多动画效果,可以鼠标移入(onEnter)/ 点击(onClick)进行查看,大部分的动画代码都是可以在相应属性的事件处理弹窗中查看的。使用者可以打开弹窗参考其中的代码,也可以对弹窗中的代码进行调试查看。
便捷分享
为了满足用户分享风格手册并希望能默认选中指定节点的需求,风格手册增加了一个便捷的分享功能。通过该功能,用户可以生成一个带有节点选中信息的链接,将该链接分享给其他人。当被分享者打开该链接时,风格手册会自动选中指定的节点。
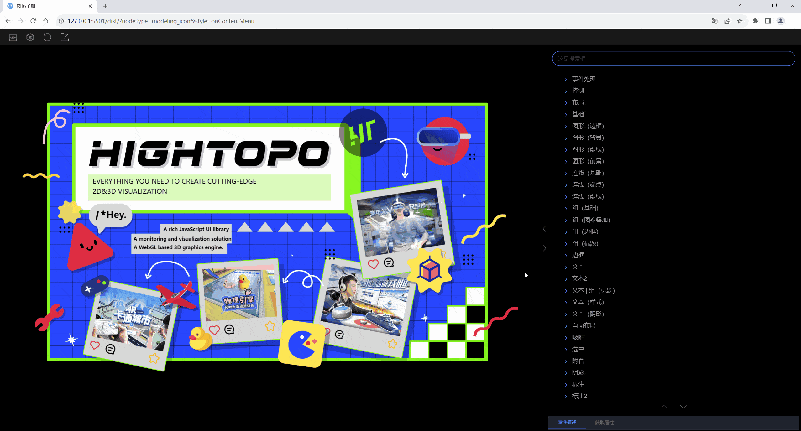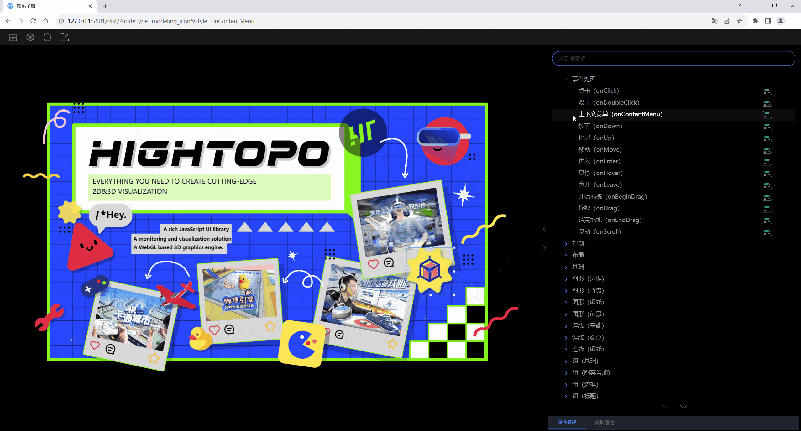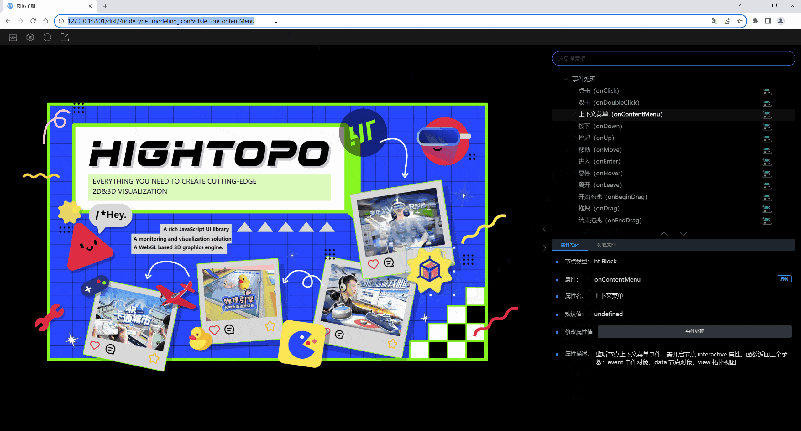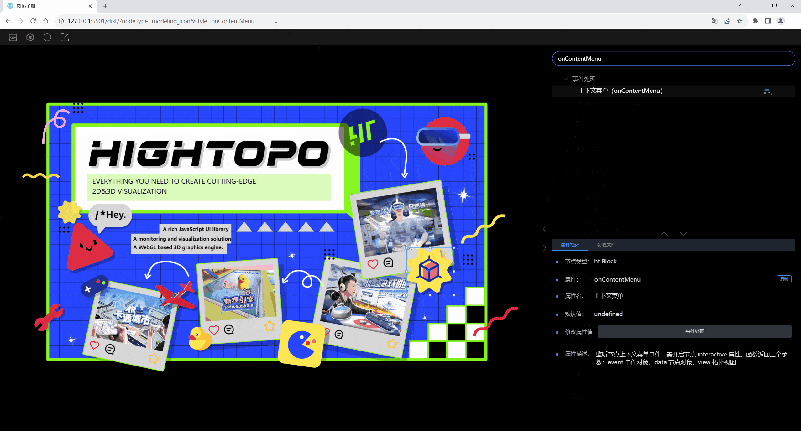
右侧属性树中选择属性之后,会在 Url 上加上三个参数:属性 Style、视图 View、选中节点类型 nodeType。可以将此链接分享出去,打开的时候就会根据 Url 参数切换视图、选择节点和过滤选中属性。
新旧版本对比
布局变化
新旧版本的风格手册在布局上变化非常大,共有的部分有:属性树、属性检索、属性描述的内容。
新版本的风格手册着重于用户的交互体验,去掉了代码编辑器区域,选择内置 2D 图纸和 3D 场景,并且在布局上给视图内容提供了较大的区域。这样的设计,让使用者能够更直观地观察和操作 2D 图纸和 3D 场景,同时不需要使用者在代码中创建节点和调整属性。
旧版本的风格手册则侧重于代码编辑,更大的区域用于展示代码编辑区域和代码运行区域的内容。这样的布局设计让使用者更灵活地进行编辑和运行代码。
操作使用
新版本在使用上更低代码化。先在图纸/场景上选择节点,之后在右侧属性树选择要调整的属性,接着在右下角属性描述就可以直接修改属性值的内容。修改属性值之后【图纸/场景】上会立即生效。

旧版本的使用流程:选择节点类型 -> 选择属性之后,在中间代码编辑区域会显示示例代码,右侧会显示示例代码运行的效果。如果需要调整属性样式,需要在代码编辑区域内调整,调整之后点击运行可在右侧查看效果。
属性树
1.新旧版本风格手册的属性树的结构上有比较大的区别。
旧版本属性树分为两个层级:节点类型,属性。新版本在选中节点的时候,就对属性树进行了过滤(在没有选中节点的情况下,会显示所有属性),所以没有节点类型的层级,并且对属性进行了分类,第一层级显示的是属性树的分类,这样在查找属性上会更加便捷。
在新版本的风格手册中,对属性树进行了更新和改进,不仅显示了属性本身,还展示了属性名、属性值的数据类型和默认值。这样的设计使得属性树更加完整,提供了更丰富的属性信息供用户查看。
2.图扑 HT 有很多类型的节点都是继承于父类的,例如:ht.Text 是继承于 ht.Node 的。旧版本风格手册的属性树只会显示当前节点类型上的属性,并不会显示父类的属性。新版本上解决了这一问题,选择节点之后右侧属性树会显示当前这个节点所支持的所有属性。
3.新版本的属性树为了在使用上更加方便,增加了双击复制属性的功能。
4.旧版本的属性搜索框支持属性的模糊搜索,新版本的属性搜索框在旧版本的基础上增加了属性名的模糊搜索。
属性信息
旧版本的属性描述在中间上面的位置,内容有属性名、默认值和属性描述。新版本的在此基础上增加了属性节点类型、修改属性值、属性复制的内容,显示的内容更加全面,让使用者能更加深入地了解到每个属性。
新版本还增加了修改属性值的功能,会根据不同类型的数据,显示不同的编辑框。还设计了专门针对于函数类型(例如:onClick) 和数组类型(例如:shape.dash.pattern)的编辑弹窗。

图扑软件 HT for Web 可实现在 Web 浏览器中创建和展示高性能的交互式 3D 可视化解决方案,允许用户创建、编辑、渲染和导出三维模型,适用于各种工业互联网领域。HT 使用 HTML5 现代 Web 技术,无需安装任何插件或附加软件,即可在各种 Web 浏览器中运行。并提供了丰富的功能和工具,包括模型加载、材质编辑、动画制作、光照渲染、碰撞检测等,可以满足复杂的 3D 可视化、数字孪生应用需求。