兰溪做网站中企动力做的网站后台怎么登录
目录
💥1 概述
📚2 运行结果
🎉3 参考文献
👨💻4 Matlab代码
💥1 概述
A*(念做:A Star)算法是一种很常用的路径查找和图形遍历算法。它有较好的性能和准确度。本文使用 A* 搜索算法来优化无线传感器节点网络的平均电池寿命。
📚2 运行结果
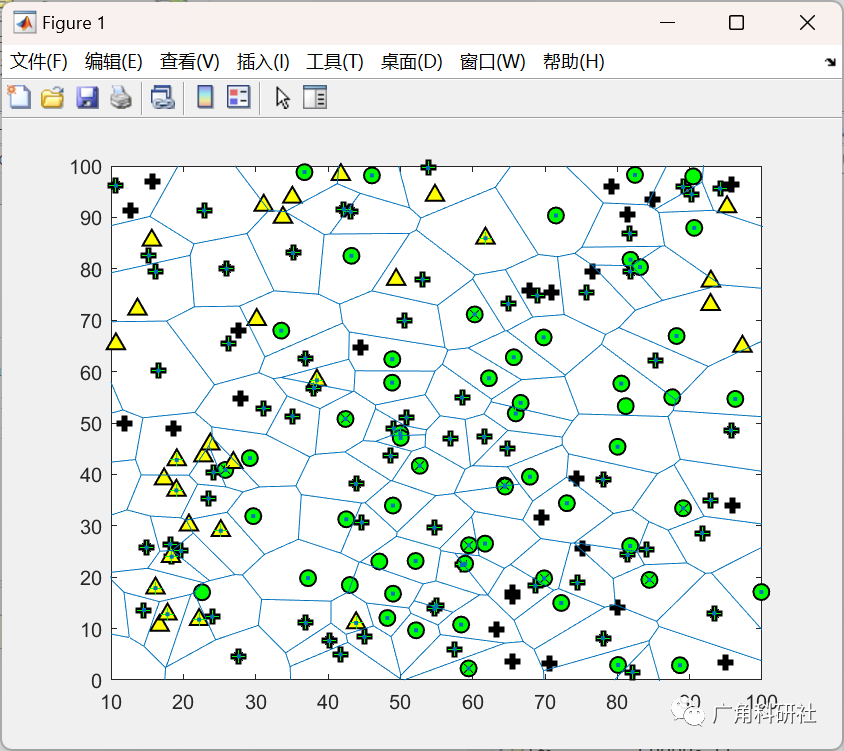
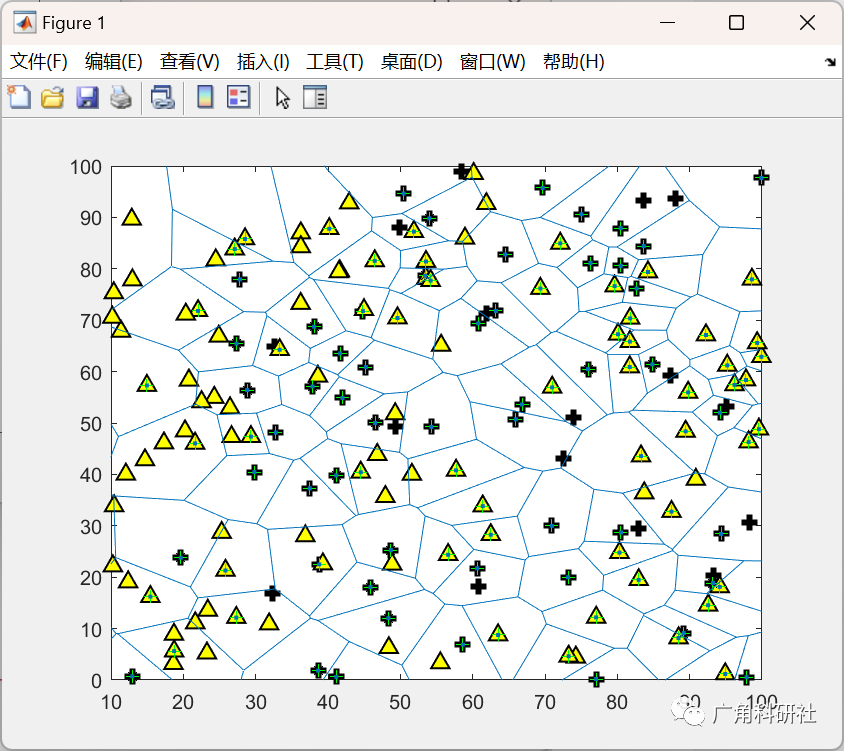

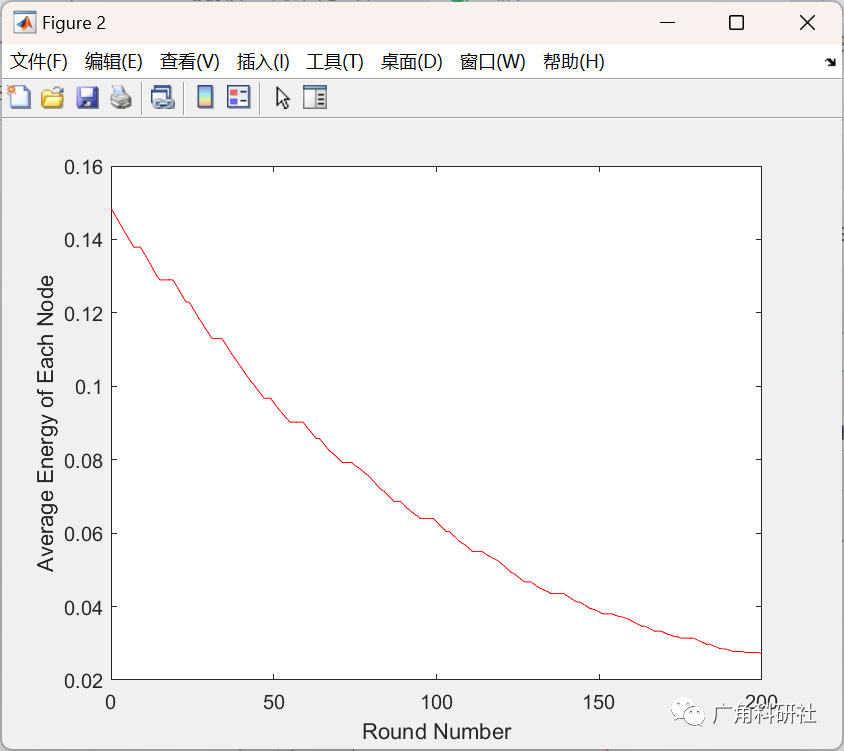
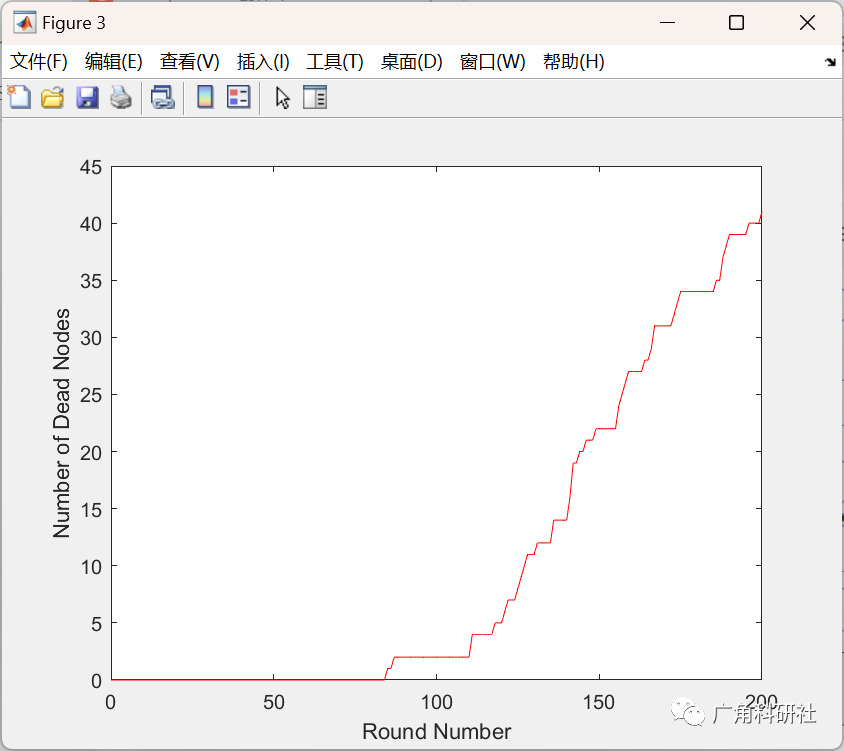
主函数部分代码:
close all;
clear;
clc;
%-------------------------------
%Number of Nodes in the fieldn=200;
%n=input('Enter the number of nodes in the space : ');
%Energy Model (all values in Joules)
%Initial Energy
Eo=0.1;
%Eo=input('Enter the initial energy of sensor nJ : ');
%Field Dimensions - x and y maximum (in meters)
% xm=input('Enter x value for area plot : ');
% ym=input('Enter y value for area plot : ');
xm=100;
ym=100;
%x and y Coordinates of the Sink
sink.x=1.5*xm;
sink.y=0.5*ym;
%Optimal Election Probability of a node
%to become cluster head
p=0.2;
%Eelec=Etx=Erx
ETX=50*0.000000001;
ERX=50*0.000000001;
%Transmit Amplifier types
Efs=10*0.000000000001;
Emp=0.0013*0.000000000001;
%Data Aggregation Energy
EDA=5*0.000000001;
%Values for Hetereogeneity
%Percentage of nodes than are advanced
m=0.5;
%\alpha
a=1;
%maximum number of rounds
%rmax=input('enter the number of iterations you want to run : ');
rmax=200;
%------------------
%Computation of do
do=sqrt(Efs/Emp);
%Creation of the random Sensor Network
figure(1);
hold off;
for i=1:1:nS(i).xd=rand(1,1)*xm;XR(i)=S(i).xd;S(i).yd=rand(1,1)*ym;YR(i)=S(i).yd;S(i).G=0;%initially there are no cluster heads only nodesS(i).type='N';temp_rnd0=i;%Random Election of Normal Nodesif (temp_rnd0>=m*n+1) S(i).E=Eo;S(i).ENERGY=0;plot(S(i).xd,S(i).yd,'o-r');hold on;end%Random Election of Advanced Nodesif (temp_rnd0<m*n+1) S(i).E=Eo*(1+a);S(i).ENERGY=1;plot(S(i).xd,S(i).yd,'+');hold on;end
end
S(n+1).xd=sink.x;
S(n+1).yd=sink.y;
plot(S(n+1).xd,S(n+1).yd,'o', 'MarkerSize', 12, 'MarkerFaceColor', 'r');
figure(1);
% figure(1)
% plot(o1,o2,'^','LineWidth',1, 'MarkerEdgeColor','k', 'MarkerFaceColor','y', 'MarkerSize',12);
% hold on
%First Iteration
%counter for CHs
countCHs=0;
%counter for CHs per round
rcountCHs=0;
cluster=1;
countCHs;
rcountCHs=rcountCHs+countCHs;
flag_first_dead=0;
for r=0:1:rmaxr;
%Operation for epochif(mod(r, round(1/p) )==0)for i=1:1:nS(i).G=0;S(i).cl=0;endend
🎉3 参考文献
[1]梁艺凡,谭丽,冯挺.A~*进路搜索算法的研究与实现[J].铁道标准设计,2013,No.613(02):117-119+127.
部分理论引用网络文献,若有侵权联系博主删除。