旅游网站制作方案南昌是哪个省
问题
在使用jmeter过程中,本机的内存等配置不足,启动较多的线程时,可以采用分布式运行。
在分布式运行的时候,jmeter会自动将脚本从master主机发送到remote主机上,所以不需要考虑将脚本拷贝到remote主机。但是jmeter不会发送脚本中引用的数据文件,如果脚本中使用了csv数据文件元件,此时就需要考手动将csv文件备份到remote主机上。
但是由于remote主机的目录结构可能和master主机上并不相同,甚至remote主机的操作系统也不一致,此时如何设置csv文件的路径呢?
解决方法
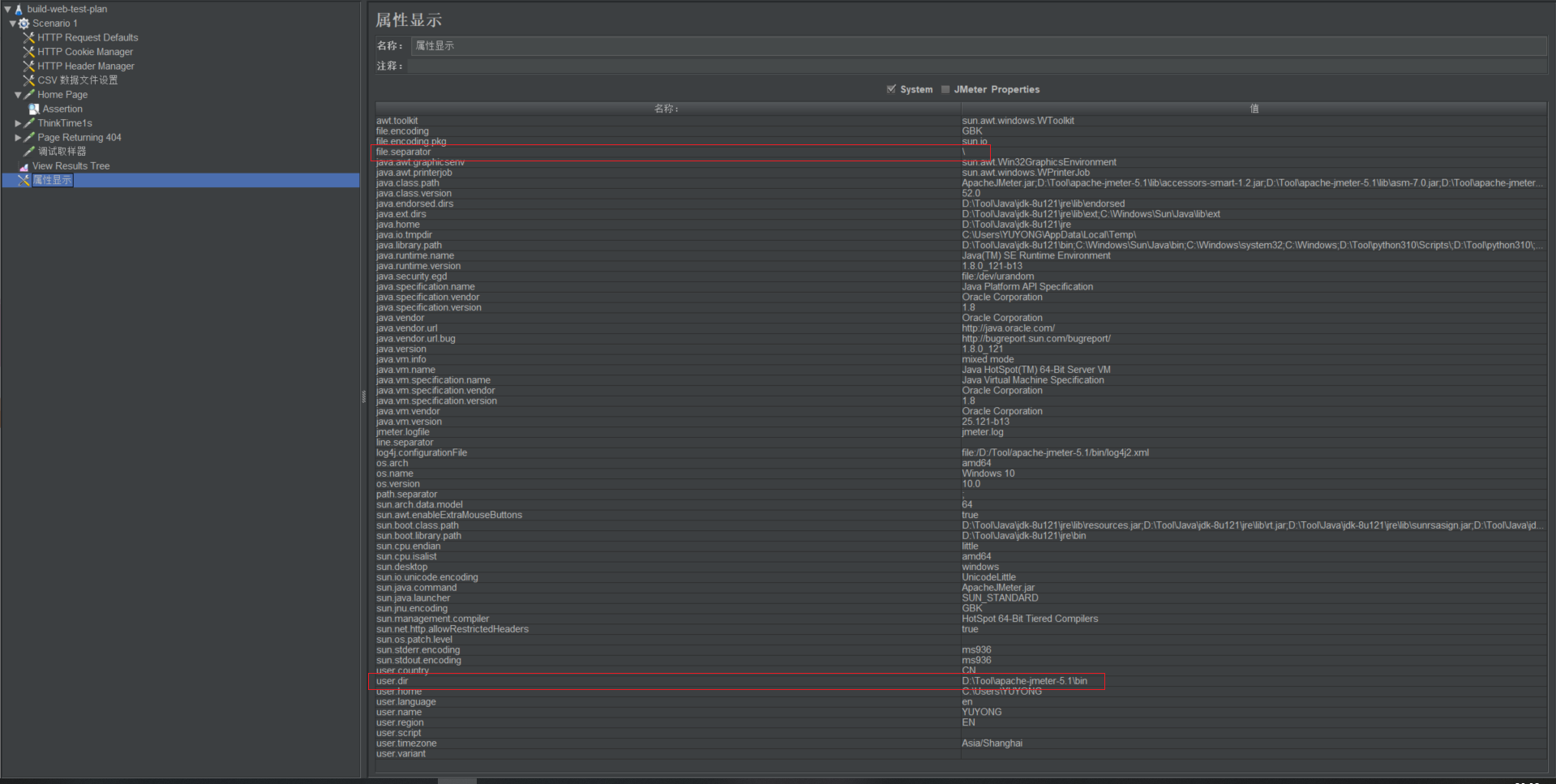
- jmeter中有一个 __P() 函数,可以获取jmeter的系统属性。
- 右键测试计划:添加 -> 非测试元件 -> 属性显示,可以勾选“system”显示jmeter的系统属性。系统属性中有一个 user.dir 是当前jmeter程序的bin目录的路径;系统属性中 file.separator 是当前jmeter所在系统的文件路径的分隔符。
- 将csv文件拷贝到每个remote主机的jmeter bin目录下,就可以通过引用上面两个系统变量来引用csv文件。csv文件的路径可以如下:${__P(user.dir)}${__P(file.separator)}test.csv
- 如果觉得作为测试数据的csv文件放到bin目录下不太合适,也可以在jmeter的根目录下创建一个专门存放测试数据的目录,如:data,此时引用csv的路径可以使用相对路径来引用:${__P(user.dir)}${__P(file.separator)}../data${__P(file.separator)}test.csv
2023最新Jmeter接口测试从入门到精通(全套项目实战教程)