泉州网站建设科技公司网站301重定向代码
整体思路:
第一步解BL锁
第二步线刷包
第三步magisk开启超级用户权限
第四步magisk安装Lsposed模块等等扩展使用
第一步
参考
给小米/红米手机root(工具基本都是官方的)——magisk篇_小米专用root工具官方-CSDN博客
成功如下:
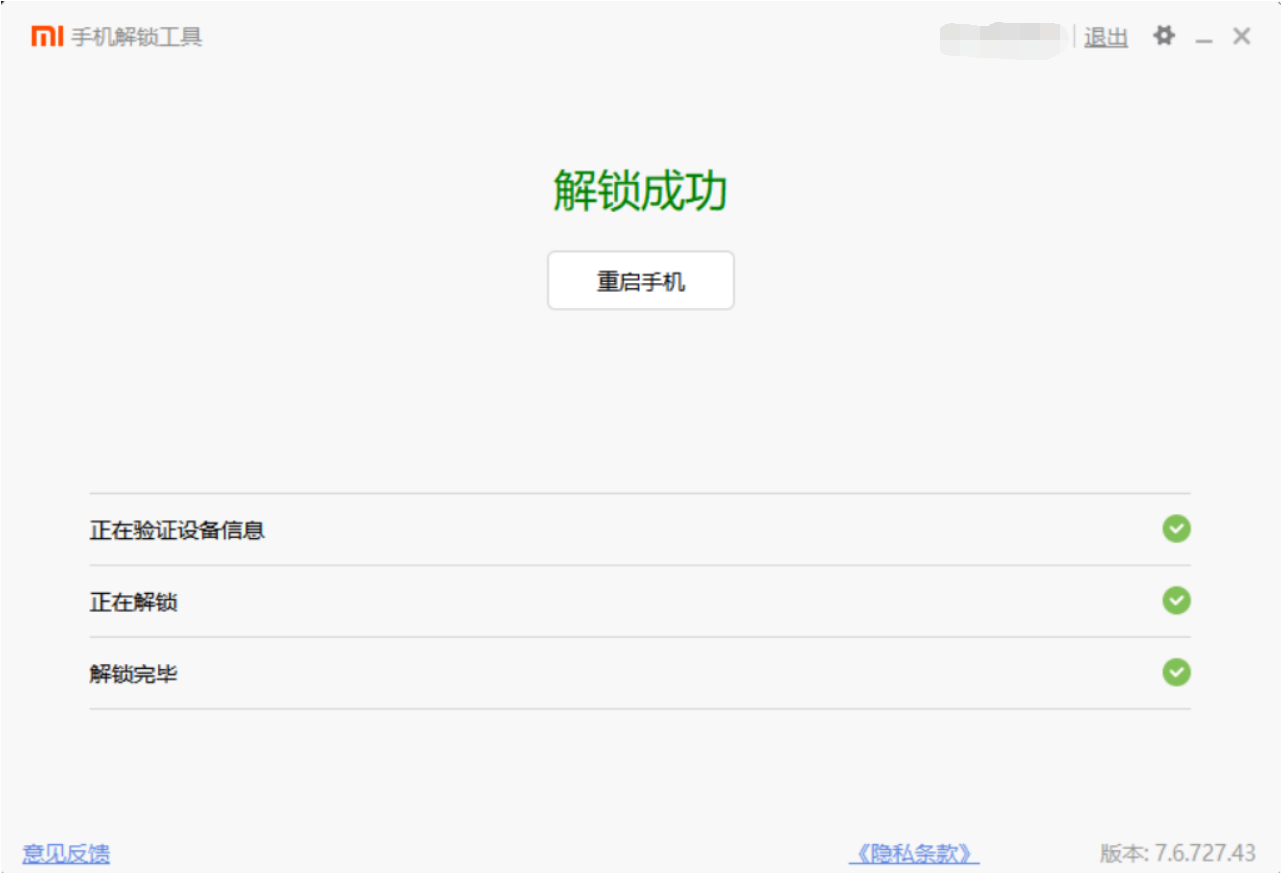

第二步
参考
XiaomiROM.com - 小米 ROM | MIUI、澎湃OS(HyperOS)线刷包, 卡刷包的最新及历史版本下载
HyperOS丨MIUI 下载速度慢?解除限速教程 - Magisk中文网 (magiskcn.com)
下载官方小米刷机工具 MiFlash,含小米刷机教程步骤 | XiaomiROM.com
报错参考
玩机搞机---小米刷机工具平台刷写报错对症解决方法_missmatching image and device-CSDN博客
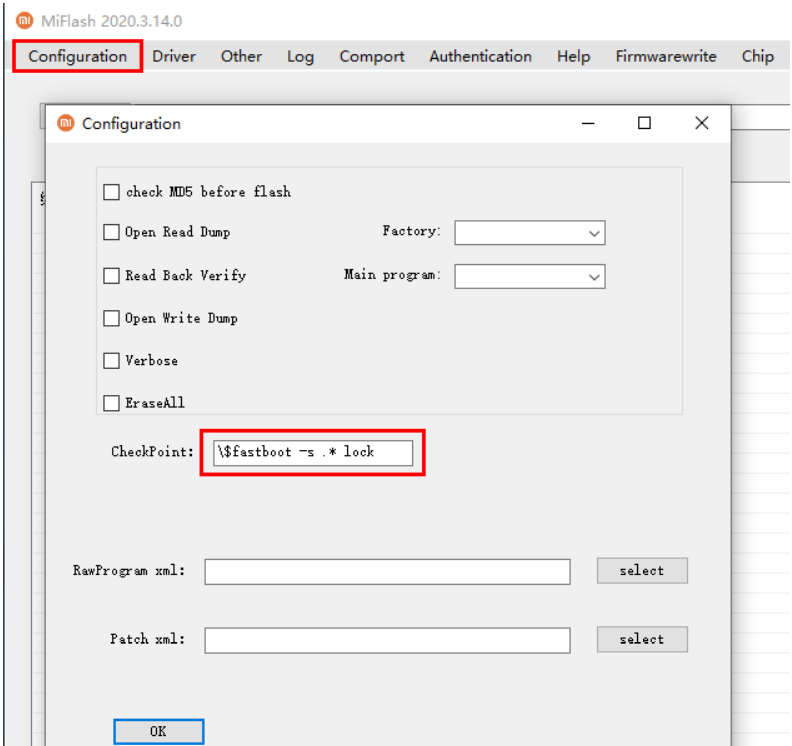
成功如下:
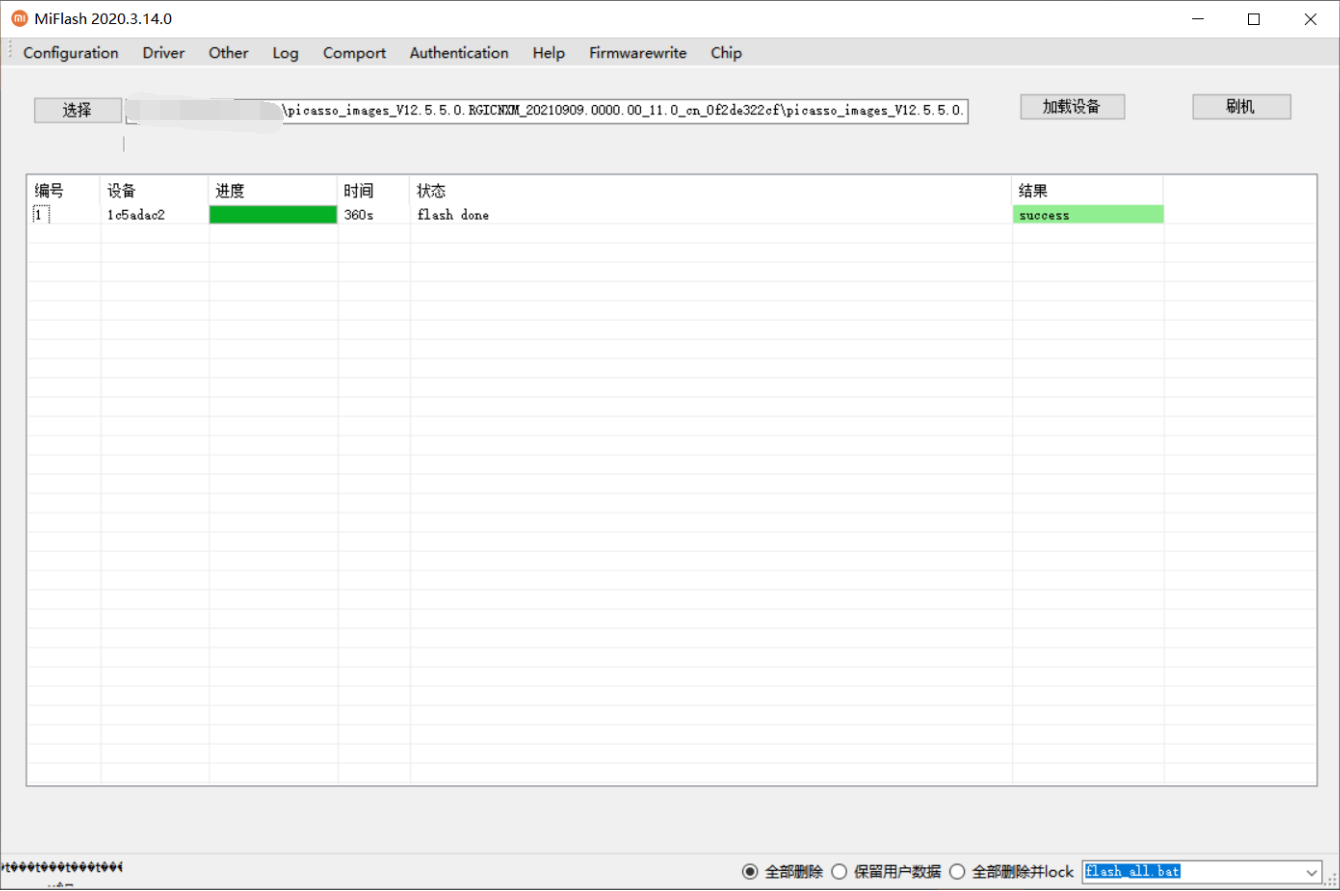
第三步
参考
线刷面具Magisk教程,实现root自由_哔哩哔哩_bilibili
小米手机Root教程(线刷) - 知乎 (zhihu.com)(里面可以下载那个“platform-tools”)
成功如下:
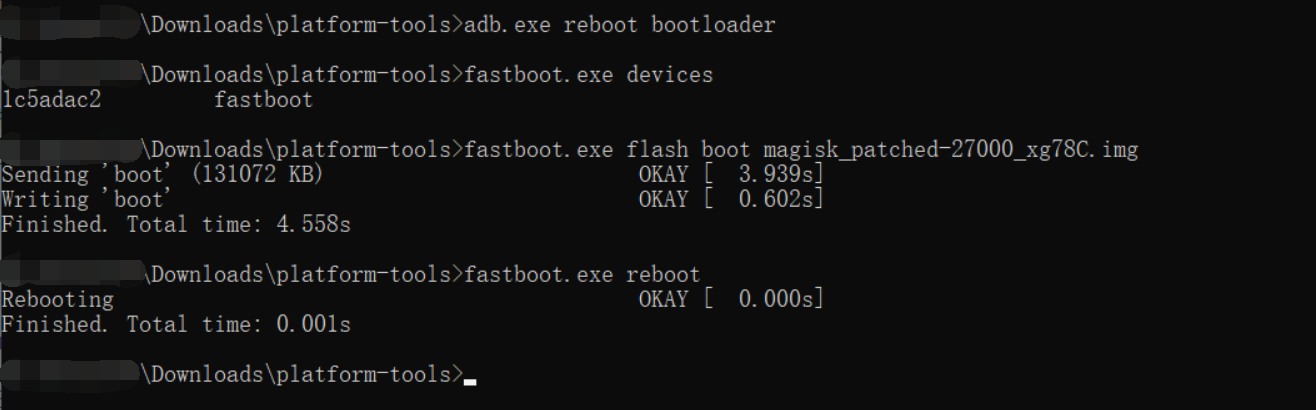
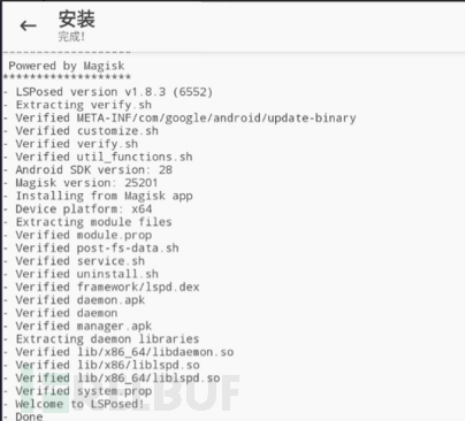
第四步
参考
配合Magisk之LSPosed安装 - FreeBuf网络安全行业门户
成功如下:
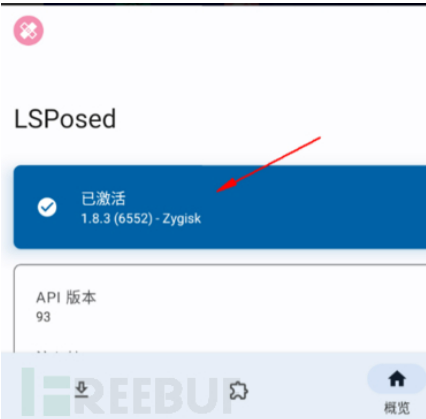
扩展
如果有些APP有ROOT检测可以使用Magisk隐藏ROOT权限来绕过
参考
Shamiko模块 - 配合Magisk+LSPosed隐藏ROOT - 知乎 (zhihu.com)
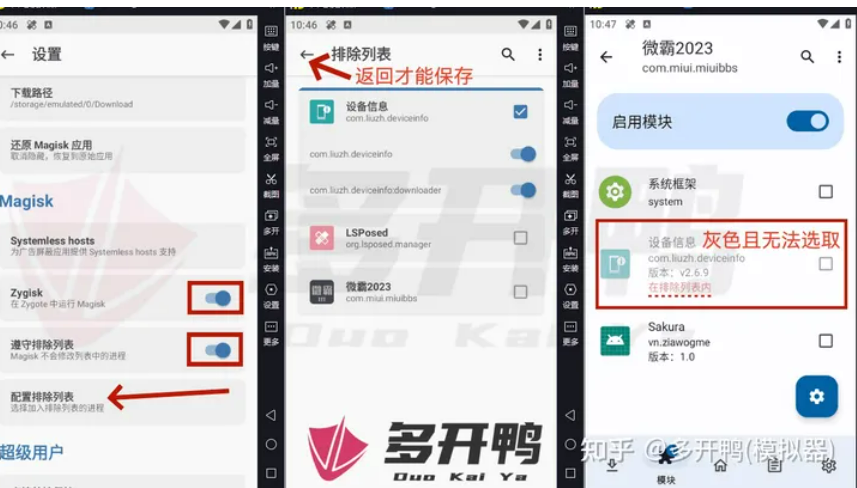
还有很多模块(例如SSL证书等)自行按需使用