外国人做的关于中国的视频网站无锡网站建设价格低
题目描述:小宁发现了一个网页,但却一直输不对密码。(Flag格式为 Cyberpeace{xxxxxxxxx} )
打开链接:

然后我们会发现不管我们输入什么密码,发现是都是这样的报错

1. 先用bp抓包看看,可以抓到这样的一串js脚本

看不懂没关系,我们试着将这串代码拷贝下来,运行下,将最后的密码打印出来,我们在return pass之前加一条打印语句将结果打印出来
function dechiffre(pass_enc){var pass = "70,65,85,88,32,80,65,83,83,87,79,82,68,32,72,65,72,65";var tab = pass_enc.split(',');var tab2 = pass.split(',');var i,j,k,l=0,m,n,o,p = "";i = 0;j = tab.length;k = j + (l) + (n=0);n = tab2.length;for(i = (o=0); i < (k = j = n); i++ ){o = tab[i-l];p += String.fromCharCode((o = tab2[i]));//console.log(p);if(i == 5)break;}for(i = (o=0); i < (k = j = n); i++ ){o = tab[i-l];if(i > 5 && i < k-1)p += String.fromCharCode((o = tab2[i]));}p += String.fromCharCode(tab2[17]);pass = p;console.log(pass);return pass;
}String["fromCharCode"](dechiffre("\x35\x35\x2c\x35\x36\x2c\x35\x34\x2c\x37\x39\x2c\x31\x31\x35\x2c\x36\x39\x2c\x31\x31\x34\x2c\x31\x31\x36\x2c\x31\x30\x37\x2c\x34\x39\x2c\x35\x30"));执行该脚本,结果为FAUX PASSWORD HAHA,看到没有,刚好就是报错信息 ,所以,无论我们输入什么密码,都会打印这个
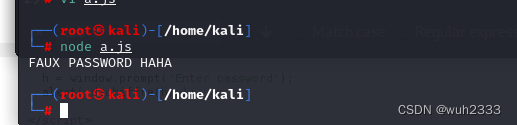
2. 找到flag
既然没有正确的密码,那么我们注意js代码中有一串代码好像没有用到过,这大概率就是真正的flag了,不过需要进行转换
String["fromCharCode"](dechiffre("\x35\x35\x2c\x35\x36\x2c\x35\x34\x2c\x37\x39\x2c\x31\x31\x35\x2c\x36\x39\x2c\x31\x31\x34\x2c\x31\x31\x36\x2c\x31\x30\x37\x2c\x34\x39\x2c\x35\x30"));我们首先将16进制转成10进制,通过以下代码进行处理
function decode(str){return str.replace(/\\x(\w{2})/g,function(_,$1){ return String.fromCharCode(parseInt($1,16)) });}a = decode("\x35\x35\x2c\x35\x36\x2c\x35\x34\x2c\x37\x39\x2c\x31\x31\x35\x2c\x36\x39\x2c\x31\x31\x34\x2c\x31\x31\x36\x2c\x31\x30\x37\x2c\x34\x39\x2c\x35\x30")console.log(a)
得到结果为:55,56,54,79,115,69,114,116,107,49,50

最后再将这串字符根据ASCII码转成字符即可(可参考假密码的解密方式)

执行该代码,得到flag为:786OsErtk12

总结:这道题主要考察的是js的语法,以及进制,字符转换,难度还是有些的,这三种综合在一起,可能思路上不太容易想到正确的方法,而且对编程能力也有一定的要求。
PS:个人认为这道题找flag没有逻辑性(代码看半天才发现根本没有正确的密码)