图片点开是网站怎么做互联网方案设计
1,新建国际化多语言文件
在resources目录下新建 messages.properties + 其他语言的文件

编辑messages.properties文件,下方从text切换到Resource Bundle ,即可对照着编辑多语言文件
(如果没有找到Resource Bundle,先在settings->plugins中安装Resource Bundle Editor)
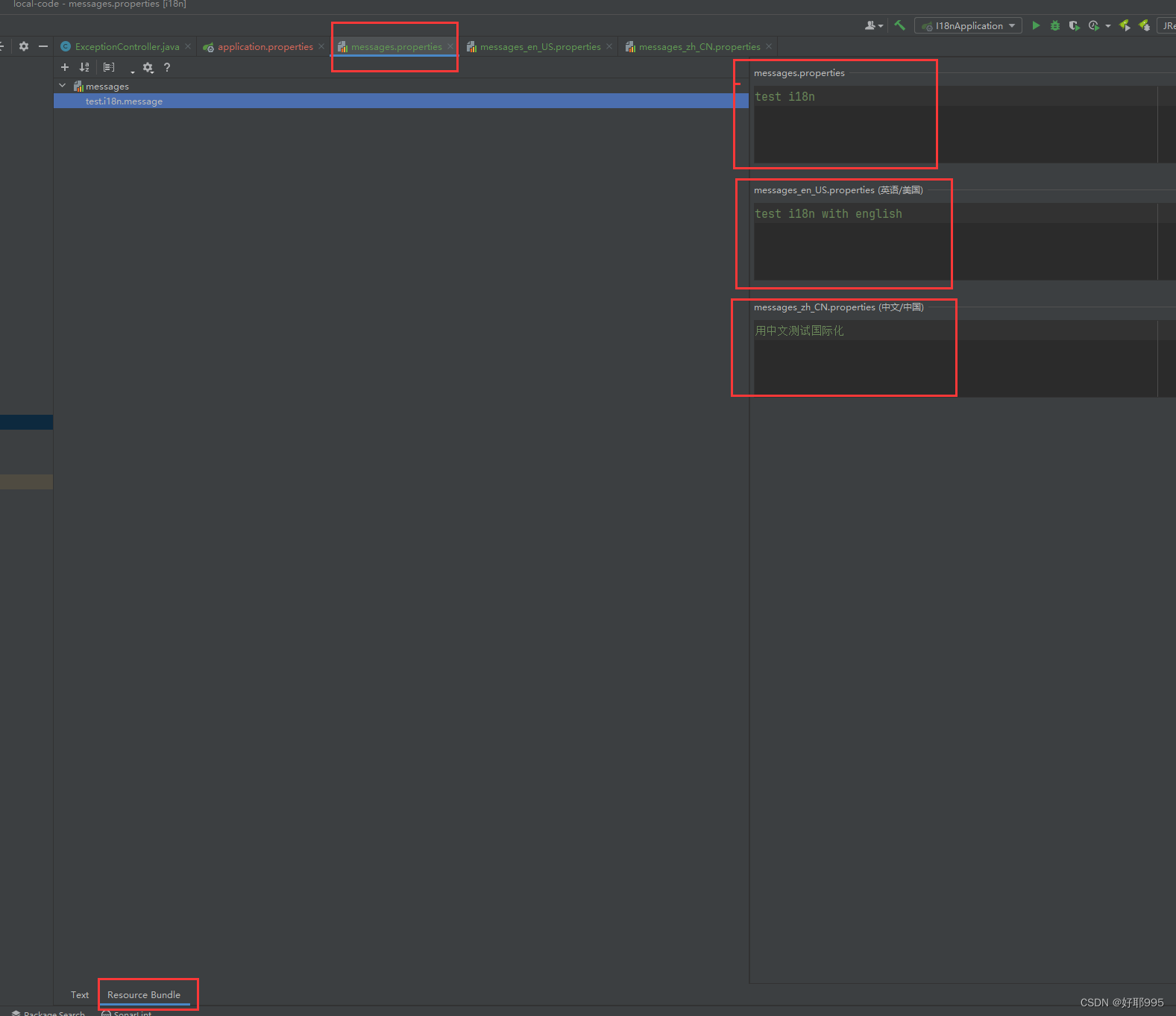
2,配置文件添加配置
spring.messages.always-use-message-format=false
是否始终应用 MessageFormat 规则,甚至分析没有参数的消息。
默认是false
spring.messages.basename=messages
以逗号分隔的基名列表(实质上是完全限定的类路径位置),每个基名都遵循 ResourceBundle 约定,对基于斜杠的位置提供了宽松的支持。如果它不包含包限定符(例如“org. mypackage”),则将从类路径根目录解析它。
默认是messages,所以第一步中文件为messages.properties,也可根据实际定义其他名字。
spring.messages.cache-duration=1000
加载的资源包文件缓存持续时间。如果未设置,捆绑包将永久缓存。如果未指定持续时间后缀,则将使用秒。
默认是null。
spring.messages.encoding=utf-8
消息包编码。
默认是UTF-8
spring.messages.fallback-to-system-locale=true
如果未找到特定区域设置的文件,是否回退到系统区域设置。如果关闭此功能,则唯一的回退将是默认文件(例如,basename “messages”的“messages. properties”)。
默认是true
spring.messages.use-code-as-default-message=false
是否使用消息代码作为默认消息,而不是抛出“NoSuchMessageException”。建议仅在开发期间使用。
默认是false。
第一步中我们定义了一个参数叫test.i18n.message,如果我们使用的时候取名test.i18n.message123,只要是多语言文件中未定义的key,则该参数设置为false时,会报错。设置为true时,不会报错,由于找不到对应的key,则不替换该多语言字符。
3,设置上下文语言环境
在web请求中,两个地方会根据header中的参数设置语言环境:
org.springframework.web.filter.RequestContextFilter#initContextHolders
org.springframework.web.servlet.FrameworkServlet#initContextHolders
解析request中locale的地方:
org.apache.catalina.connector.Request#parseLocales
如果请求头中为携带语言参数的header为accept-language,则框架已自动帮我们做了解析,不用我们再写额外代码。
注意:参考了多个大公司国际化,没有公司将国际化相关的数据用accept-language传递(accept-language本身记录的是浏览器(我用的谷歌浏览器)的语言环境,可能是可以作为其他的业务数据,类似于收集用户数据等),而是存放在cookie中。
所以我们要定义一个参数,将国际化相关的数据存放在cookie中,请求后端时将该参数添加到header(单独定义一个header参数,或者将整个cookie传输)中传递到后端。
假设这里是单独定义了一个header参数:test-lang。
框架解析多语言环境时,使用的accept-language,所以我们要重写解析的方法,替换为我们自定义的header参数:test-lang。
新建一个request的包装类,在filter中包装原request,重写解析语言环境的方法。
import org.apache.tomcat.util.http.parser.AcceptLanguage;import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import java.io.IOException;
import java.io.StringReader;
import java.util.*;/*** @Description i18n 国际化包装请求* @DATE 2024/4/6 22:45**/
public class I18nWrapperRequest extends HttpServletRequestWrapper {public I18nWrapperRequest(HttpServletRequest request) {super(request);}/*** Parse locales.*/protected boolean localesParsed = false;/*** The preferred Locales associated with this Request.*/protected final ArrayList<Locale> locales = new ArrayList<>();/*** The default Locale if none are specified.*/protected static final Locale defaultLocale = Locale.getDefault();@Overridepublic Locale getLocale() {if (!localesParsed) {parseLocales();}if (locales.size() > 0) {return locales.get(0);}return defaultLocale;}@Overridepublic Enumeration<Locale> getLocales() {if (!localesParsed) {parseLocales();}if (locales.size() > 0) {return Collections.enumeration(locales);}ArrayList<Locale> results = new ArrayList<>();results.add(defaultLocale);return Collections.enumeration(results);}/*** Parse request locales.*/protected void parseLocales() {localesParsed = true;// Store the accumulated languages that have been requested in// a local collection, sorted by the quality value (so we can// add Locales in descending order). The values will be ArrayLists// containing the corresponding Locales to be addedTreeMap<Double, ArrayList<Locale>> locales = new TreeMap<>();Enumeration<String> values = ((HttpServletRequest) getRequest()).getHeaders("test-lang");while (values.hasMoreElements()) {String value = values.nextElement();parseLocalesHeader(value, locales);}// Process the quality values in highest->lowest order (due to// negating the Double value when creating the key)for (ArrayList<Locale> list : locales.values()) {for (Locale locale : list) {addLocale(locale);}}}/*** Parse accept-language header value.** @param value the header value* @param locales the map that will hold the result*/protected void parseLocalesHeader(String value, TreeMap<Double, ArrayList<Locale>> locales) {List<AcceptLanguage> acceptLanguages;try {acceptLanguages = AcceptLanguage.parse(new StringReader(value));} catch (IOException e) {// Mal-formed headers are ignore. Do the same in the unlikely event// of an IOException.return;}for (AcceptLanguage acceptLanguage : acceptLanguages) {// Add a new Locale to the list of Locales for this quality levelDouble key = Double.valueOf(-acceptLanguage.getQuality()); // Reverse the orderlocales.computeIfAbsent(key, k -> new ArrayList<>()).add(acceptLanguage.getLocale());}}/*** Add a Locale to the set of preferred Locales for this Request. The first added Locale will be the first one* returned by getLocales().** @param locale The new preferred Locale*/public void addLocale(Locale locale) {locales.add(locale);}}
import org.springframework.core.Ordered;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import org.springframework.web.filter.OncePerRequestFilter;import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;/*** @Description 国际化过滤器* @DATE 2024/4/6 23:00**/
@WebFilter("/**")
@Component
@Order(value = Ordered.HIGHEST_PRECEDENCE)
public class I18nFilter extends OncePerRequestFilter {@Overrideprotected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {filterChain.doFilter(new I18nWrapperRequest(request), response);}
}
4,返回多语言
目前是在报错信息中需要返回多语言,报错分为两种:
1)手动抛出异常信息
2)validation框架抛出异常信息
首先,我们需要