个人网站需要哪些内容做网站要多大空间
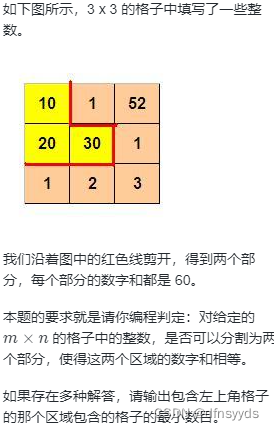
剪格子是一道dfs入门题。
我先写了个dfs寻找路径的模板,没有按题上要求输出。当我确定我的思路没错时,一直运行不出正确结果。然后我挨个和以前写的代码对比,查了两个小时才发现,是命名风格的问题。
我今天写的代码如下:
#include<iostream>
#include<vector>
#include<string>
using namespace std;// 必须从11开始
// 出口bool vis[4][4];
int g[4][4];
int res = 0;
int sum = 0;
int n, m;
int dirs[4][2] = { {1, 0}, {-1, 0},{0, 1},{0, -1}};
// 如何去重
void dfs(int i, int j, int cnt)
{// 出口 等于一半 必然没加全if (cnt * 2 == sum){res++;return;}if (cnt * 2 > sum)return;vis[i][j] = true;// 两个方向:限制好dfs别出界for (int i = 0; i < 4; i++){int nx = i + dirs[i][0];int ny = j + dirs[i][1];if (nx >= 1 && nx <= n && ny >= 1 && ny <= m && !vis[nx][ny]){dfs(nx, ny, cnt + g[nx][ny]);}}vis[i][j] = false;
}int main()
{cin >> m>>n;for (int i = 1; i <= n; i++)for (int j = 1; j <= m; j++){cin >> g[i][j];sum += g[i][j];}dfs(1, 1, g[1][1]);cout << sum<<endl;cout << res;return 0;
}----挨个注释查了半天发现是4个方向取值不一致,但是我看了半个小时方向变量dirs的赋值没有错,后来通过出输出发现这个代码的遍历路径和下面不一样,最后终于发现原来是命名问题,参数使用了i,j,dirs的取值也用了i,变量命名冲突了。for内的i本该是外圈的i+for内i指向的德尔塔方向,但是这里的i由于较近取值原则,都使用了for的i,所以最后输出错了。所以我将函数参数改为x和y。用x、y也更符合坐标命名的风格。我开始编写代码没有注意,随手用了i、j。所以函数参数千万别用i、j、函数参数千万别用i、j、函数参数千万别用i、j。因为但凡有for循环,就会冲突。
同时我也知道了我今天做的另外一道路径dfs题为什么一直出错了,因为函数传参也用了i、j。
下篇博客我会写那道题
#include<iostream>
#include<vector>
#include<string>
using namespace std;// 必须从11开始
// 出口bool vis[4][4];
int g[4][4];
int res = 0;
int sum = 0;
int n, m;
int dirs[4][2] = { {1, 0}, {-1, 0},{0, 1},{0, -1}};
// 如何去重
void dfs(int x, int y, int cnt)
{// 出口 等于一半 必然没加全if (cnt * 2 == sum){res++;return;}if (cnt * 2 > sum)return;vis[x][y] = true;// 两个方向:限制好dfs别出界for (int i = 0; i < 4; i++){int nx = x + dirs[i][0];int ny = y + dirs[i][1];if (nx >= 1 && nx <= n && ny >= 1 && ny <= m && !vis[nx][ny]){dfs(nx, ny, cnt + g[nx][ny]);}}vis[x][y] = false;
}int main()
{cin >> m>>n;for (int i = 1; i <= n; i++)for (int j = 1; j <= m; j++){cin >> g[i][j];sum += g[i][j];}dfs(1, 1, g[1][1]);cout << sum<<endl;cout << res;return 0;
}
(其它做题习惯:dfs路径遍历方向用一个二维dirs[4][2]存储即可)
最后,再按题目要求改为题目要求的内容。
(该题不考虑去重:因为固定从顶部剪,且有回溯做标记,且回溯只标记当前dfs来的位置)
这里又他码的不小心错了,dfs参数中count、cnt差点用混了,编程处处要小心啊。
#include<iostream>
#include<vector>
#include<string>
using namespace std;// 必须从11开始
// 出口bool vis[11][11];
int g[11][11];
int res = 0;
int sum = 0;
int n, m;
int dirs[4][2] = { {1, 0}, {-1, 0},{0, 1},{0, -1}};
int ans = INT32_MAX;
// 不去重:因为固定从顶部剪,且有回溯做标记,且回溯只标记当前dfs来的位置
// cnt:目前累加和、count:选了几个格
void dfs(int x, int y, int cnt, int count)
{// 出口 等于一半 必然没加全if (cnt * 2 == sum){//if(ans > count)ans = min(ans, count);return;}if (cnt * 2 > sum)return;vis[x][y] = true;// 两个方向:限制好dfs别出界for (int i = 0; i < 4; i++){int nx = x + dirs[i][0];int ny = y + dirs[i][1];if (nx >= 1 && nx <= n && ny >= 1 && ny <= m && !vis[nx][ny]){dfs(nx, ny, cnt + g[nx][ny], count+1);}}vis[x][y] = false;
}int main()
{cin >> m>>n;for (int i = 1; i <= n; i++)for (int j = 1; j <= m; j++){cin >> g[i][j];sum += g[i][j];}// dfs(1, 1, g[1][1], 1);cout << ans;return 0;
}
最后是成果通过: