手机怎么网站模板即墨网站建设哪家好
Gradio Dataframe sort 问题
- 1. 问题描述
- 2. 解决办法(临时)
1. 问题描述
使用 Gradio Dataframe 显示表格数据时,默认每个列名右边会有个 sort icon,点击这个 sort icon 后,会按照该列进行升序或者降序排序。
问题点是,如果对表格的数据进行更新后,这个排序不会刷新。
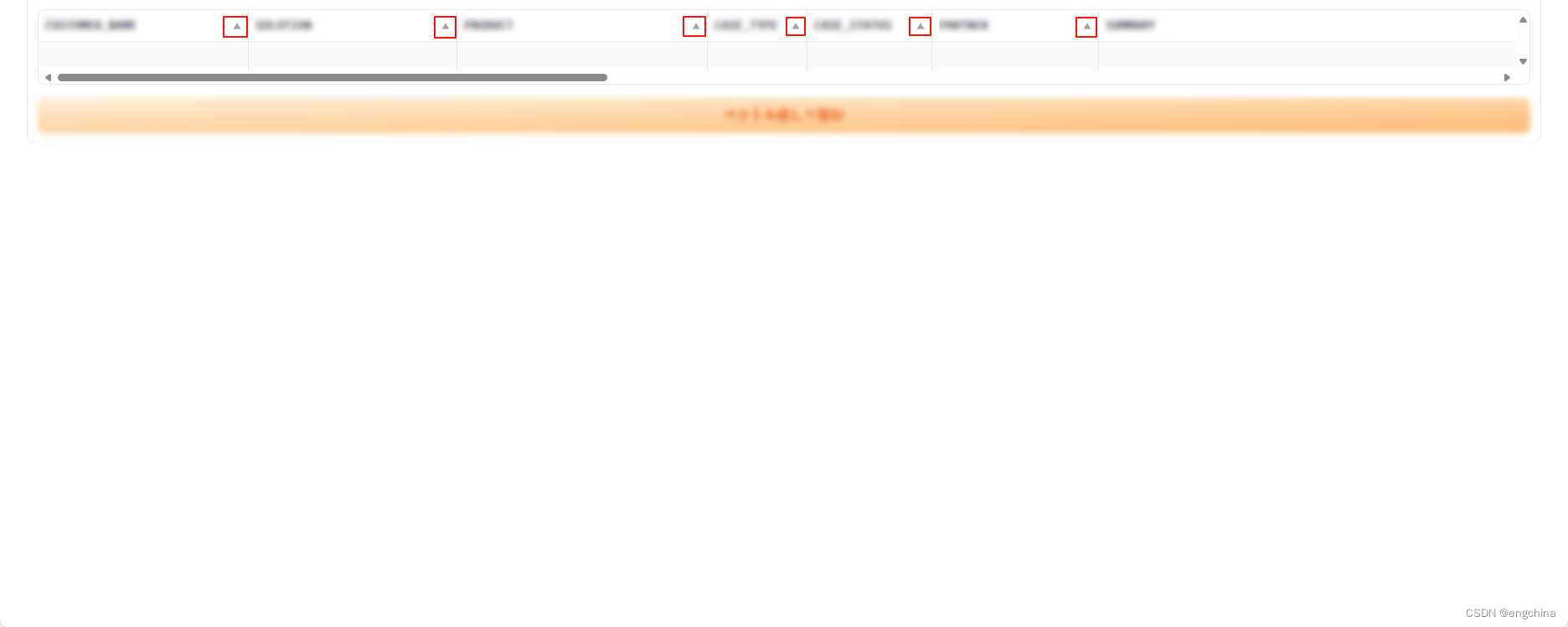
2. 解决办法(临时)
参考github issue的一个临时方案,禁用这个排序功能。

示例代码如下,
custom_css = \
"""
/* Hide sort buttons at gr.DataFrame */
.sort-button {display: none !important;
}
"""with gr.Blocks(..., css=custom_css) as demo:
refer: https://github.com/gradio-app/gradio/issues/5230
完结!