兰州电商平台网站建设石景山网站建设服务
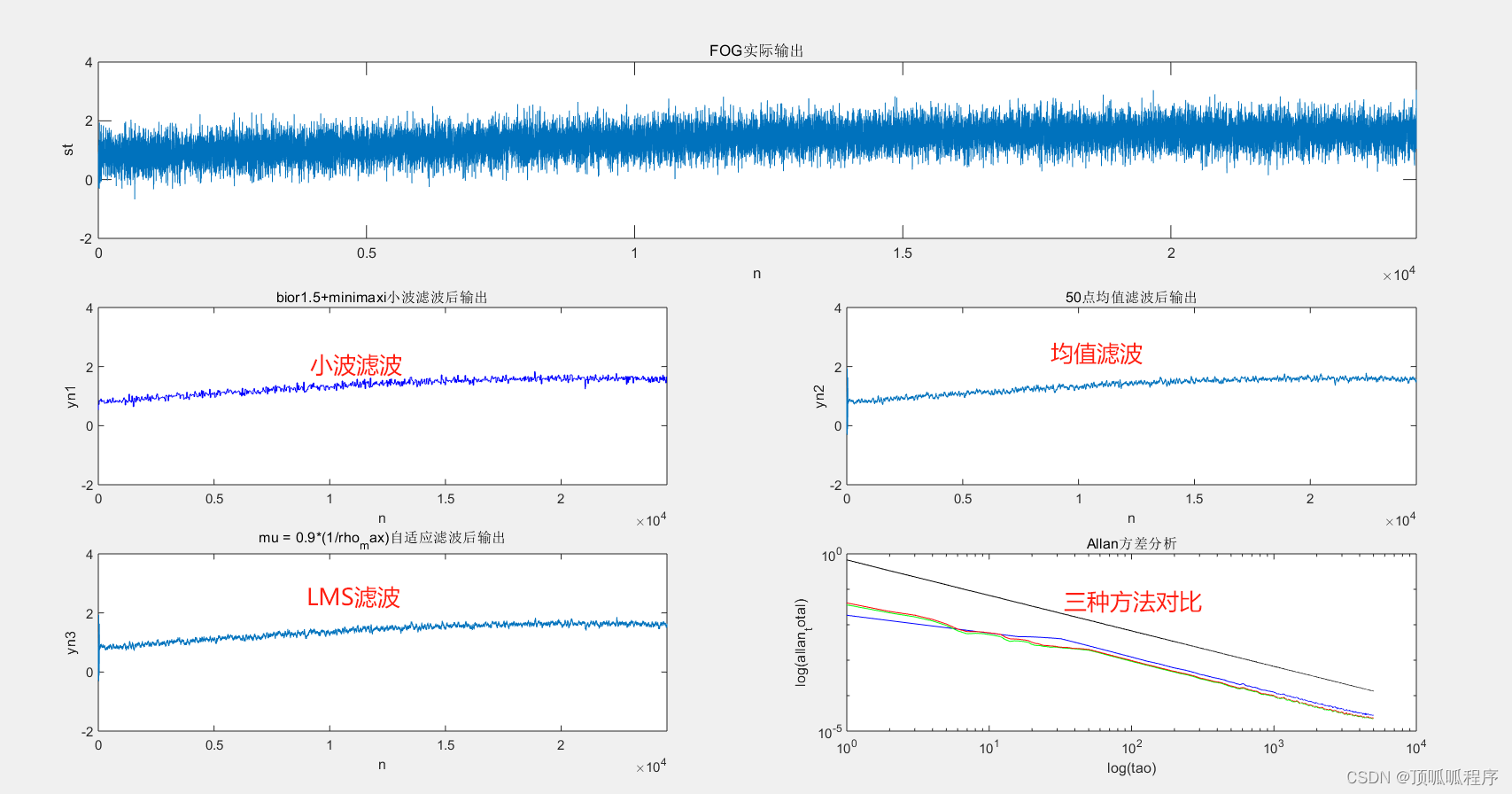
基于Matlab的光纤陀螺随机噪声和信号,利用固定步长和可调步长的LMS自适应滤波、最小二乘法、滑动均值三种方法进行降噪处理,最后用阿兰方差评价降噪效果。程序已调通,可直接运行。
156 信号处理 自适应滤波 降噪效果评估 (xiaohongshu.com)
基于Matlab的光纤陀螺随机噪声和信号,利用固定步长和可调步长的LMS自适应滤波、最小二乘法、滑动均值三种方法进行降噪处理,最后用阿兰方差评价降噪效果。程序已调通,可直接运行。
156 信号处理 自适应滤波 降噪效果评估 (xiaohongshu.com)