购物网站建设app开发t型网站域名和版面
结束后面试官加了VX,并询问方便二面的时间,一直还没回复,拖着拖着给忘啦...
面试题
1、自我介绍
2、你在团队里头负责哪一块,这个物流开放平台流量多大
3、为什么今年3月份被从物流开放团队转到了finance财务部门,感觉二者业务跨度挺大的
4、用go多长时间了,聊聊对GMP的理解
5、Channel的底层实现,以及作用有哪些?项目中哪里用到了channel吗?Channel什么情况下会出现死锁,有遇到过吗?
6、下面这段代码会输出什么?
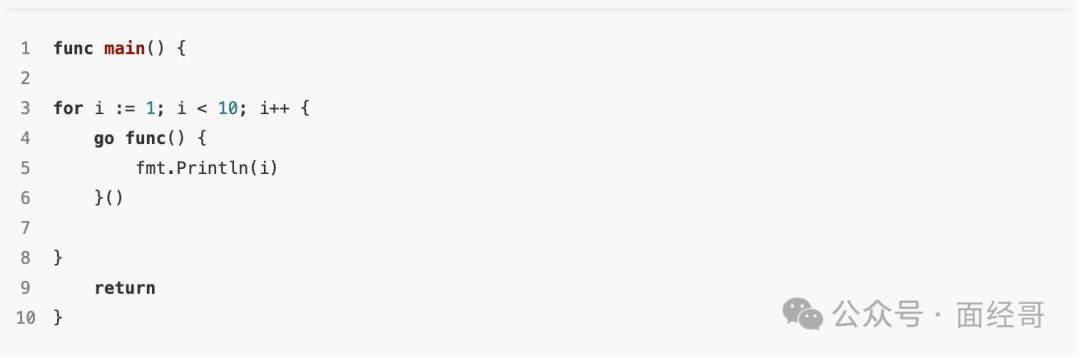
怎么解决这个问题呢,讲讲多种思路?
7、MySQL的索引了解吗?讲讲索引失效的场景?联合索引用得多吗?
where a in (1,2,3) and b > 3 and c = 3 order by d,建一个合适的联合索引
8、对MySQL的log了解多少?redolog和undolog的作用分别是什么?
binlog了解吗?
9、消息队列用过吗
10、Redis的数据类型用过哪些?ZSet的底层数据结构了解吗?Redis持久化了解吗?RDB执行过程会阻塞主线程吗?
11、目前的薪资以及期望薪资
12、为什么要跳槽?