张家界市网站建设设计国外 平面设计网站
这是一份面向直播新手的企业直播说明教程,字数较多,完整看完,可能会需要求10分钟,建议您可以【收藏】,如果本文章对您有帮助,就帮助【点个赞】吧~~~
阿酷TONY / 2023-5-12 / 原创文章 / 长沙 /
文章目录
第1部分.直播硬件设备
├─A.电脑硬件推荐配置
└─B.选配硬件第2部分.直播网络环境
第3部分.直播设备连接
├─A.双机位摄像机视频直播场景
└─B.单机位摄像机视频直播场景
第4部分.摄像机设备/摄像机采集画面直播
├─直播形式1:常见的拍摄画面直播
├─直播形式2:绿幕扣图形式直播
└─直播形式3:MR直播(混合现实直播)形式直播
第5部分.导播台(简易软件导播台)第6部分.企业直播观看权限设定
├─A.白名单观看(企业常用)
├─B.登记观看(企业常用)
├─C.验证码观看
├─D.付费观看(不常用)
└─E.自定义授权
第7部分.直播数据报表
├─A.评估直播效果(场次观看人次)
├─B.评估营销效果
├─C.收集用户反馈
└─D.改进直播策略
第1部分.直播硬件设备
A.电脑硬件推荐配置
系统:win7系统以上,macOS 10.13.6以上
显卡:独立2G显卡或以上,例如,NVIDIA GeForce或AMD Radeon系列的显卡。
CPU:Intel i5或i7系列,或者AMD Ryzen 5或7系列。这将有助于处理直播流、编码和其他任务。
内存:推荐8G以上;对于较复杂的直播任务,如高清视频或多任务处理,16GB或更多的内存将更好;较低码率时也可以考虑4G或以上。
拍摄:外置摄像头,摄像机+采集卡。比较建议选择一台高清摄像机或者使用高像素的手机、平板电脑或电脑内置摄像头。确保摄像设备的画质清晰、稳定。
B.选配硬件
收音:小蜜蜂,耳机麦克风,专业麦克风。比较建议使用一个高质量的麦克风,确保声音的清晰度和准确度。您可以选择有线或无线麦克风,具体根据您的需求和预算来决定。
外放:耳机,外置扬声器。
现场:绿色、红色、蓝色幕布
网络:网线,有线网络或WI-FI,4G网络聚合器。确保您有高速、可靠的网络连接,以避免直播过程中出现延迟或断连的问题。您可以使用有线网络连接或者Wi-Fi,但要确保信号稳定。
硬件导tt
照明:为了获得良好的视频效果,确保场地有足够的光线。您可以使用室内灯光或专业摄影灯来提供适当的照明。脚架和支架:为了确保摄像机的稳定性,您可能需要使用脚架或支架来固定摄像设备。这将有助于提供更稳定、清晰的视频。
其他辅助设备:根据您的直播需求,您还可以考虑其他辅助设备,如显示器、音频混音器、信号转换器等。
部分设备配图

▲图1 / 摄像机设备(点击以上小图可以看高清大图)

▲图2 / 拍摄设备(点击以上小图可以看高清大图)
第2部分.直播网络环境
建议使用有线网络。若使用WIFI或手机网络,需确保直播场地内信号稳定。
直播受上行带宽影响,建议上行带宽8-10Mbps或以上。
带宽测试地址:http://www.speedtest.cn
测试方法:
打开网页,选择就近的节点,若已是当地节点,则默认即可。
点击开始测试。
测试结束后查看「上传」带宽,若上传带宽不足8-10Mbps,请更换更稳定、带宽更大的网络,避免影响正常直播。
多次测试得到的平均数据更准确 。
第3部分.直播设备连接
下图是双机位直播、单机位直播的接线示意图,图上是以保利威采集卡为例的接线示意,当然采集卡也可以换成其他牌子,接线方式是一样的。
阿酷TONY提一下的是:摄像机一般都有SDI和HDMI两种信号接口,采集卡就要接到这接口中,来获取信号。
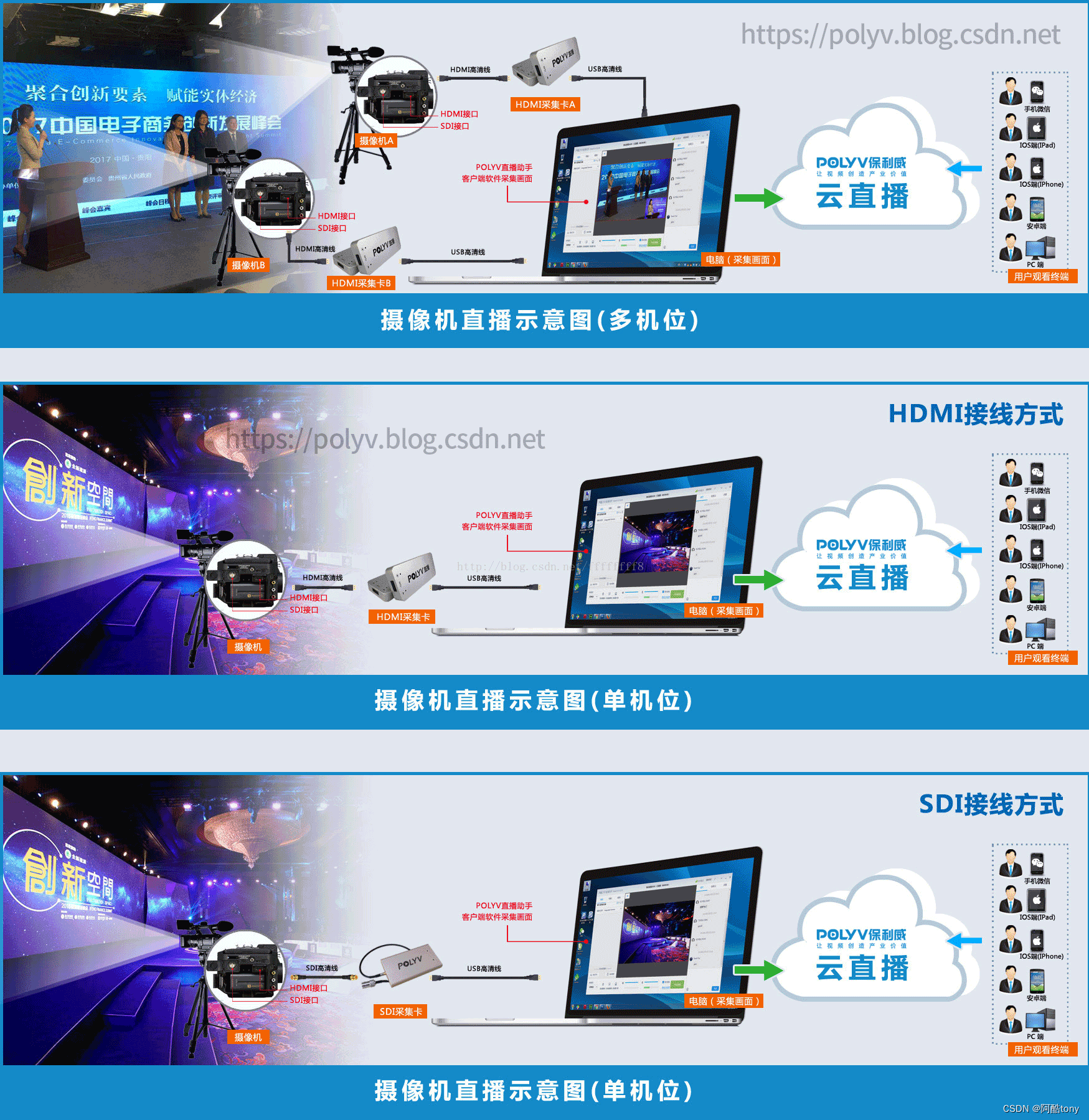
▲图3 / 双机位直播、单机位直播的接线示意图(点击以上小图可以看高清大图)
A.双机位摄像机视频直播场景
主要是那种带画中画直播效果的,一个主画面(例如会场全景、PPT演示屏取景等等),另一个小画面(例如取景主持人、演讲嘉宾等等);
在这样的情况下,就要在现场布两个甚至两个以上的摄像机设备。
B.单机位摄像机视频直播场景
这种是最常见的,通常只要求取一个画面,就OK。
本图适用于各种场景直播,可以是基于第三方保利威直播云平台,也可以基于阿里云、腾讯云等来做,当然也可以基于自己的流媒体直播环境。
第4部分.摄像机设备/摄像机采集画面直播

▲ 图4 / 摄像机设备(点击以上小图可以看高清大图)
摄像机拍摄使用方面,其实并不复杂,摄像机后面有SDI或HDMI输出口,这两种接口都比较常用,如上面图3接入设备,就可以了。
A直播形式:常见的拍摄画面直播

▲ 图5 / 峰会论坛类直播(点击以上小图可以看高清大图)

▲ 图6 / 峰会论坛类直播(点击以上小图可以看高清大图)
B直播形式:绿幕扣图形式直播

▲ 图7 / 绿幕舞台背景摄像机采集画面
▲ 图8 / 直播绿幕抠图后直播间直播的实际效果
C直播形式:MR直播(混合现实直播)形式直播
什么是MR直播,有兴趣的朋友可以看一下这个视频《普通虚拟直播与MR虚拟直播有什么区别?》:https://live.csdn.net/v/296549
MR技术可以根据不同的应用场景和需求进行定制,因此MR直播可以为不同类型的活动提供不同的虚拟场景。

▲ 图9 / 直播实例 / MR直播间(数据图表搬进场景中)

▲ 图10 / MR企业直播炫酷效果(背景效果)
第5部分.导播台
导播台是直播中的重要设备,导播台可以帮助您控制直播画面的切换和转场效果。主要用于控制直播中的各个元素,如画面切换、字幕滚动、音效播放等。

▲ 图11 / 企业直播(导播台)
第6部分.企业直播观看权限设定
A.白名单观看
只允许特定的用户观看直播,比如企业内部员工、特定学员。处于白名单里的用户输入正确的验证后,可以直接观看直播,也可以理解为设置VIP会员用户。
具体设置是这样的,首先,下载白名单模板表格,输入会员名单信息,导入到后台,保存就可以了。这里需要注意一下,导入的模板必须是从这里下载的。点击查看白名单可以查看当前名单信息。这种方式的优势包括:
安全性。通过限制观看权限,可以防止未经授权的用户或恶意用户访问直播内容。
保密性。对于敏感或机密的企业直播,白名单观看可以确保只有授权人员能够访问,减少信息泄露的风险。
精确控制。您可以根据需要选择特定的用户或IP地址,确保直播只对特定的受众开放,例如内部员工、合作伙伴或特定客户。
B.登记观看
要求观看者在观看直播之前进行登记或提供一些个人信息。这种方式的优势包括:
客户关系管理。通过要求观看者提供个人信息,您可以建立更好的客户关系,并收集有关观众的数据用于后续跟进。
个性化体验。基于观看者的登记信息,您可以提供更加个性化的观看体验,例如发送相关资料或提供定制化的内容。
C.验证码观看
要求观看者输入有效的验证码才能观看直播。这种方式的优势包括:
确保观看者的身份。通过验证码验证,您可以确保只有授权的观看者才能访问直播内容。
防止分享和盗播。使用验证码可以防止未经授权的人员分享直播链接或盗播直播内容,确保直播内容的安全性和独家性。
D.自定义授权
打开直播观看页时,直播系统会调用客户系统的验证接口,客户自定义验证逻辑,验证通过后才能打开直播观看页面,进行观看。
第7部分.直播数据报表
企业直播结束后,可根据对应直播数据做直播的分析:
评估直播效果
通过数据分析,可以评估直播的表现和效果。您可以分析观众的观看时长、观看人数、互动参与等指标,了解直播的受欢迎程度和参与度。这有助于评估您的直播策略和内容的有效性,并为未来的直播提供改进的方向。
评估营销效果
如果您的企业直播是为了营销目的,数据分析可以帮助您评估直播对品牌知名度、销售转化率或其他营销目标的影响。您可以分析参与者的行为、转化率和销售数据等,以了解直播对业务的实际影响。
收集用户反馈
通过数据分析,可以了解观众的反馈和意见。您可以分析观众留言、问答环节、投票等数据,以了解他们的兴趣、关注点和意见。这可以帮助您更好地了解受众需求,并在未来的直播中做出改进。
改进直播策略
通过对数据的分析,您可以发现直播中的强项和改进点。例如,您可以分析观众的观看习惯和偏好,了解哪些内容或互动方式更受欢迎。这可以帮助您优化直播内容、时间安排、互动形式等,提供更符合观众需求的直播体验。
决策依据和报告
直播数据分析可以为企业提供决策依据和报告。您可以使用数据分析的结果来支持决策,例如选择直播平台、确定直播频次、调整投入预算等。同时,您还可以将数据分析的结果制作成报告,用于内部分享、管理层汇报或客户沟通。
MR虚拟直播
- MR直播实例(混合现实直播)高品质企业直播
- 企业年会直播来个虚拟舞台场景如何?
- MR直播(混合现实直播)做一场高品质企业培训
- MR场景直播-帮助企业高效开展更有意思的员工培训
- 企业多会场视频直播(主会场、分会场直播)实例效果
- 虚拟直播(虚拟场景直播)要怎么做?
无延迟直播
- 无延时直播/超低延时直播画面同步性测试(实测组图)
- 搞定企业视频直播:硬件设备、直播网络环境和设备连接说明
- 无延时/无延迟视频直播实例效果案例
- OBS无延迟视频直播完整教程(组图)
- 毫秒级超低延时直播产品实测(PRTC直播/webRTC直播)
视频加密与安全
- 企业培训视频如何防止被下载和盗用?
- 在线教育机构视频加密防下载和防盗用的方法有哪些可以借鉴
- 上新:视频加密功能增加防录屏(随机水印)功能
- 两种实现视频倍速播放的方法(视频播放器倍速1.5x/2x)
- 教育培训机构教学课程内容视频加密是如何做的?
在线导播台
- 在线导播台(网页导播台)混流效果
- OBS Studio导播台多画面使用实测
- 软件导播台多画面切换支持多人连麦实测(实测组图)