做外贸网站需要什么卡营销网站建设 公司
Visualizing Attention in Transformers | Generative AI (medium.com)
一、说明
在本文中,我们将探讨可视化变压器架构核心区别特征的最流行的工具之一:注意力机制。继续阅读以了解有关BertViz的更多信息,以及如何将此注意力可视化工具整合到Comet的NLP和MLOps工作流程中。
请随时按照此处的完整代码教程进行操作,或者,如果您迫不及待,请在此处查看最终项目。
二、系统介绍
近年来,变压器被描述为NLP最重要的技术发展,但它们的工艺在很大程度上仍然不透明。这是一个问题,因为随着我们继续取得重大的机器学习进步,我们不能总是解释如何或为什么 - 这可能导致未检测到的模型偏差,模型崩溃以及其他道德和可重复性问题等问题。特别是随着模型更频繁地部署到医疗保健、法律、金融和安全等敏感领域,模型可解释性至关重要。
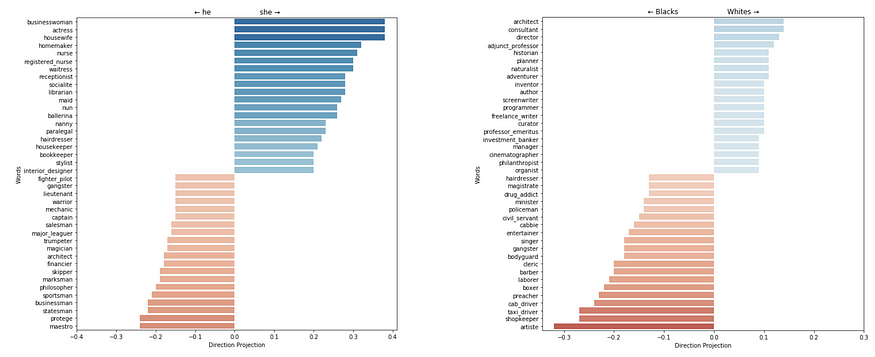
跨专业的性别和种族预测,由Word2Vec计算。这些习得的偏差可能会产生各种负面后果,具体取决于这种模型的应用。图片来自Simon Warchal的NLP嵌入中的偏见。
2.1 什么是BertViz?
BertViz是一个开源工具,可以在多个尺度上可视化转换器模型的注意力机制,包括模型级、注意力头级和神经元级。但BertViz并不新鲜。事实上,BertViz的早期版本早在2017年就已经存在。
那么,为什么我们还在谈论BertViz呢?
BertViz是一个领域的可解释性工具(NLP),否则它是众所周知的不透明的。而且,尽管它的名字,BertViz不仅在BERT上工作。BertViz API支持许多转换器语言模型,包括GPT系列模型,T5和大多数HuggingFace模型。

尽管它的名字,BertViz支持各种各样的模型。在左侧,我们使用仅编码器模型可视化问答任务,在右侧,我们使用仅解码器模型的文本生成任务。作者的动图。
近年来,随着变压器架构越来越主导机器学习领域,它们也重新引发了关于人工智能可解释性和透明度的古老但重要的辩论。因此,虽然BertViz可能并不新鲜,但它作为人工智能领域的可解释性工具的应用现在比以往任何时候都更加重要。
2.2 但首先,变压器
为了解释BertViz,它有助于对变压器和自我关注有一个基本的了解。如果您已经熟悉这些概念,请随时跳到我们开始编码的部分。
我们不会在这里讨论变压器的细节,因为这有点超出本文的范围,但我们将介绍一些基础知识。我还鼓励您查看本文末尾的其他资源。
2.3 在开始(NLP的史前时代)
那么,计算机究竟是如何“学习”自然语言的呢?简而言之,他们不能——至少不能直接。计算机只能理解和处理数值数据,因此NLP的第一步是将句子分解为“标记”,这些“标记”被分配了数值。驱动NLP的问题就变成了“我们如何才能准确地将语言和通信过程简化为计算?
一些最早的NLP模型包括前馈神经网络,如多层感知器(MLP)甚至CNN,它们今天更普遍地用于计算机视觉。这些模型适用于一些简单的分类任务(如情感分析),但有一个主要缺点:它们的前馈性质意味着在每个时间点,网络只看到一个单词作为其输入。想象一下,试图预测句子中“the”后面的单词。有多少种可能性?

如果没有太多上下文,下一个单词预测可能会变得非常困难。作者的图形。
为了解决这个问题,递归神经网络(RNN)和长短期记忆网络(LSTMs,如Seq2Seq)允许反馈或周期。这意味着每个计算都由前一个计算通知,从而允许更多的上下文。
然而,这种背景仍然有限。如果输入序列很长,则模型在到达序列末尾时往往会忘记序列的开头。此外,它们的顺序性质不允许并行化,使它们效率极低。众所周知,RNN也遭受了梯度爆炸的影响。
三、变压器简介
转换器是序列模型,它放弃了RNN和LSTM的顺序结构,并采用完全基于注意力的方法。转换器最初是为文本处理而开发的,是当今所有最先进的NLP神经网络的核心,但它们也可以用于图像,视频,音频或几乎任何其他顺序数据。
变压器与以前的NLP模型的关键区别在于注意力机制,正如《注意力就是你需要的一切》论文中所普及的那样。这允许并行化,这意味着更快的训练和优化的性能。注意力还允许比重复更大的上下文,这意味着转换器可以制作更连贯、相关和更复杂的输出。
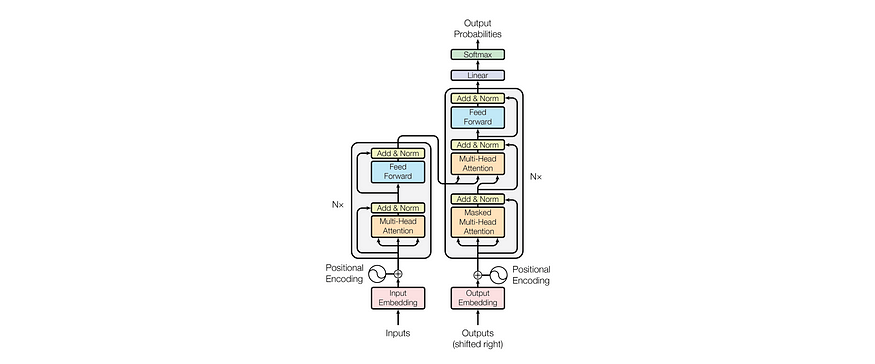
原始的变压器架构,如2017年使他们成名的论文所示,注意力是你所需要的。
变压器由编码器和解码器组成,我们可以用它们执行的任务取决于我们是使用这些组件中的一个还是两个。NLP 的一些常见转换器任务包括文本分类、命名实体识别、问答、文本摘要、填空、下一个单词预测、翻译和文本生成。
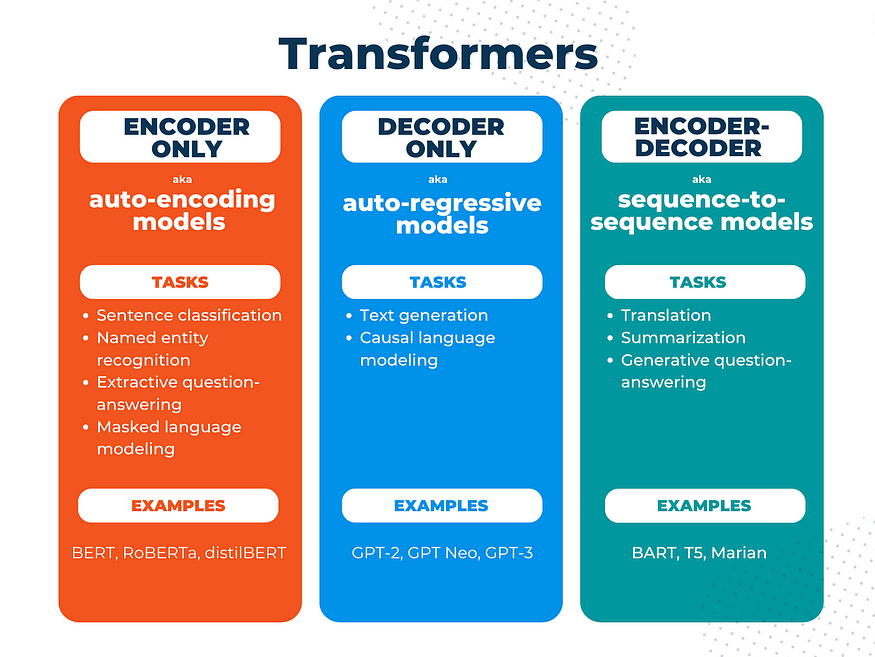
变压器由编码器和解码器组成,我们可以用它们执行的任务取决于我们是使用这些组件中的一个还是两个。请注意,还有一些不使用变压器的“序列到序列”模型。作者的图形。
四、变压器如何适应更大的NLP模型生态系统?
您可能听说过像ChatGPT或LLaMA这样的大型语言模型(LLM)。转换器架构是LLM的基本构建块,LLM对大量未标记的数据使用自我监督学习。这些模型有时也被称为“基础模型”,因为它们倾向于很好地推广到广泛的任务,并且在某些情况下也可用于更具体的微调。BERT是这类模型的一个例子。
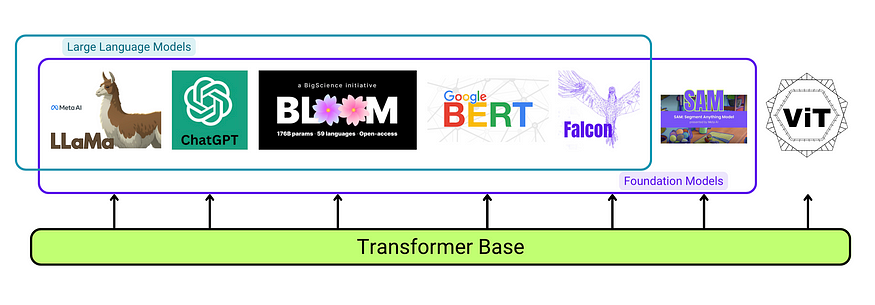
并非所有LLM或基础模型都使用变压器,但它们通常都使用变压器。并非所有的基础模型都是LLM,但它们通常是LLM。并非所有变压器都是LLM或FM。重要的一点是,所有变压器型号都需要注意。作者的图形。
这是很多信息,但这里重要的一点是,变压器模型(以及所有基于变压器的基础LLM)的关键区别特征是自我注意的概念,我们将在下面讨论。
五、注意力机制
一般来说,注意力描述了模型注意句子(或图像或任何其他顺序输入)的重要部分的能力。它通过根据输入要素的重要性及其在序列中的位置为其分配权重来实现此目的。
请记住,注意力是通过并行化来提高以前的NLP模型(如RNN和LSTM)性能的概念。但注意力不仅仅是优化。它在拓宽语言模型在处理和生成语言时能够考虑的上下文方面也起着关键作用。这使模型能够以更长的顺序生成上下文适当且连贯的文本。

在此示例中,GPT-2 以单词“害怕”结束输入序列。模型如何知道“它”是什么?通过检查注意力头,我们学习了将“它”与“动物”(而不是例如“街道”)相关联的模型。图片由作者提供。
如果我们将变压器分解为“通信”阶段和“计算”阶段,注意力将代表“通信”阶段。在另一个类比中,注意力很像搜索检索问题,给定一个查询 q,我们希望找到与 q 最相似的键集 k 并返回相应的值 v。
- 查询:我在寻找什么?
- 钥匙:我有什么东西?
- 价值:我将传达哪些内容?
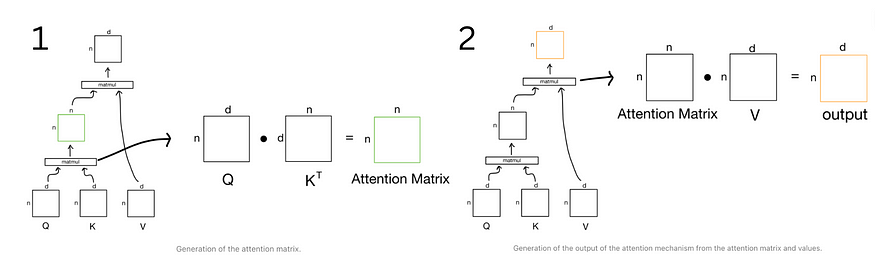
注意力计算的可视化。图片来自Erik Storrs。
六、注意力的类型
自我注意是指每个节点从该单个节点生成键、查询和值的事实。多头注意只是与不同的初始化权重并行多次应用的自我注意。交叉注意意味着查询仍从给定的解码器节点生成,但键和值作为编码器中节点的函数生成。
这是对变压器架构的过于简化的总结,我们已经掩盖了很多细节(如位置编码、段编码和注意力掩码)。有关更多信息,请查看下面的其他资源。
6.1 在 BertViz 之前可视化注意力
转换器本质上不是可解释的,但已经有很多尝试为基于注意力的模型贡献事后可解释性工具。
以前可视化注意力的尝试通常过于复杂,并且不能很好地转化为非技术受众。它们也可能因项目和用例而异。
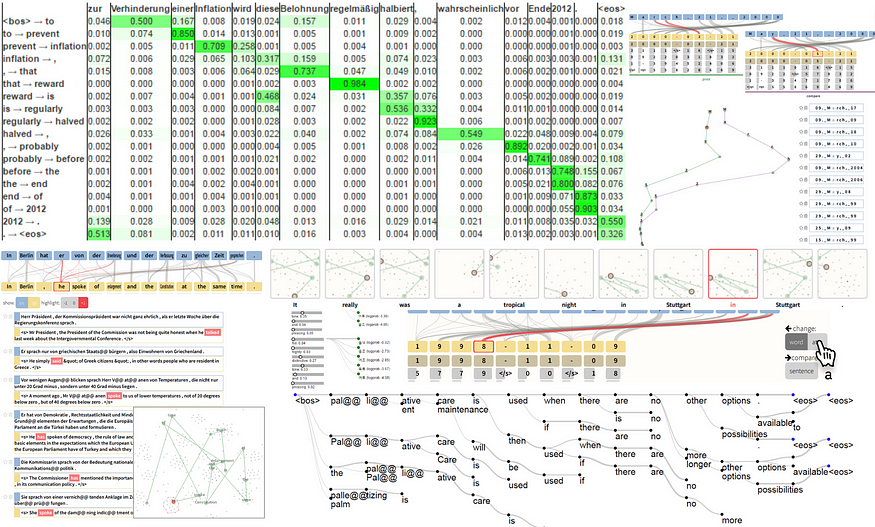
以前可视化注意力的尝试没有标准化,而且经常过于混乱。图形由作者编译自基于注意力的神经机器翻译的交互式可视化和操作(2017)和序列到序列模型的可视化调试工具(2018)。
一些解释注意力行为的成功尝试包括注意力矩阵热图和二分图表示,这两种方法今天仍在使用。但这些方法也有一些重大限制。
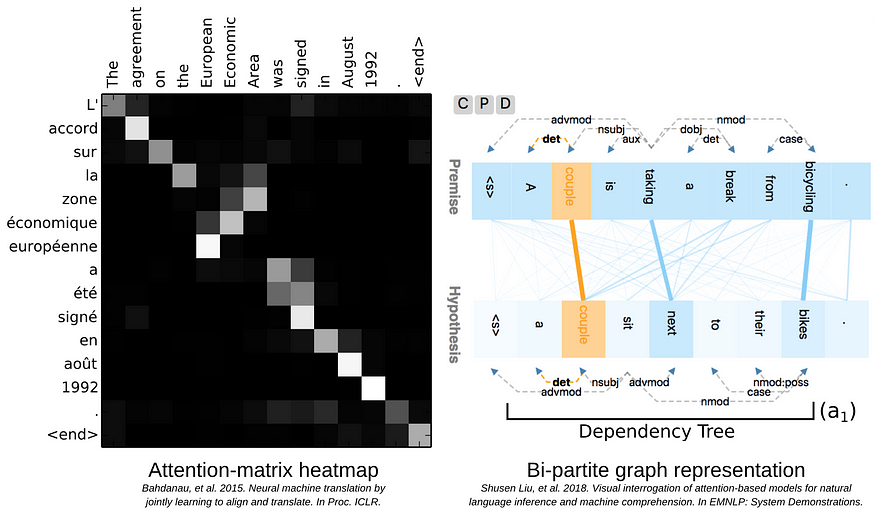
注意力矩阵热图(左)向我们表明,该模型不是逐字翻译,而是考虑词序的更大上下文。但它缺少注意力机制的许多细节。
BertViz最终因其能够说明自我注意的低级,细粒度细节而广受欢迎,同时仍然保持非常简单和直观的使用。

BertViz最终因其能够说明自我注意的低级,细粒度细节而广受欢迎,同时仍然保持非常简单和直观的使用。作者动图
这是一个漂亮、干净的可视化。但是,我们实际上在看什么?
6.2 BertViz如何打破这一切
BertViz在多个局部尺度上可视化注意力机制:神经元水平,注意力头部水平和模型水平。下面我们将分解这意味着什么,从最低、最精细的级别开始,然后向上发展。
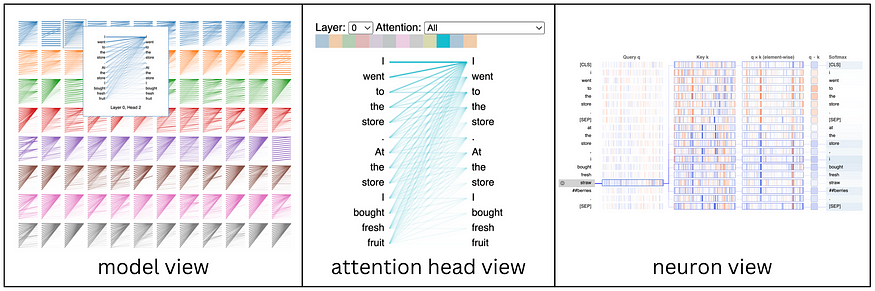
BertViz 在多个尺度上可视化注意力,包括模型级别、注意力头部级别和神经元层。作者的图形。
七、用彗星Comet可视化 BertViz
我们将BertViz图记录到实验跟踪工具Comet上,以便稍后比较我们的结果。要开始使用 Comet,请在此处创建一个免费帐户,获取您的 API 密钥,然后运行以下代码:
import comet_ml
comet_ml.init(api_key='<YOUR-API-KEY>')
experiment = comet_ml.Experiment()我们只需三行代码即可设置 Comet。
在彗星中可视化注意力将有助于我们通过显示模型如何关注输入的不同部分来解释模型的决策。在本教程中,我们将使用这些可视化来比较和剖析几个预训练 LLM 的性能。但这些可视化也可以在微调期间用于调试目的。
要将 BertViz 添加到您的仪表板,请导航到 Comet 的公共面板并选择“变压器模型查看器”或“变形金刚注意力头查看器”。
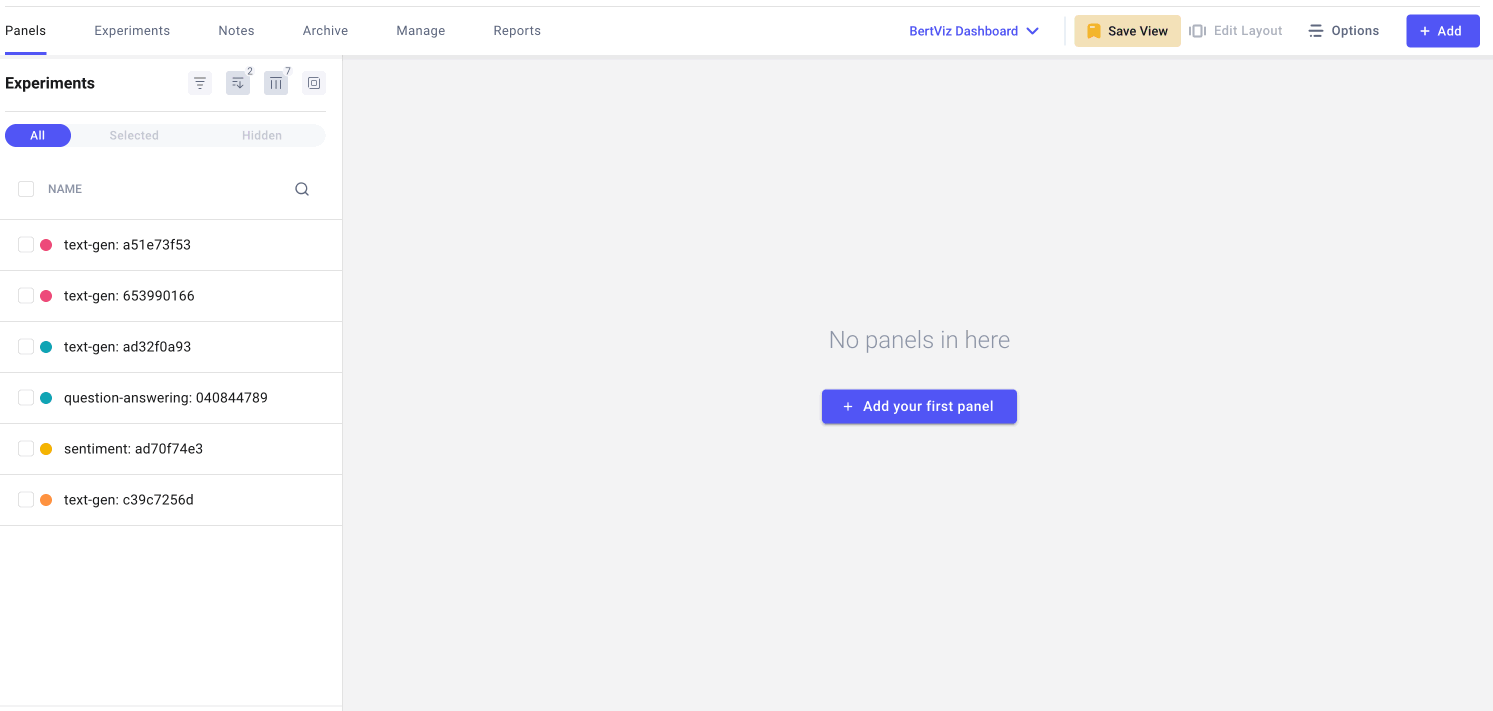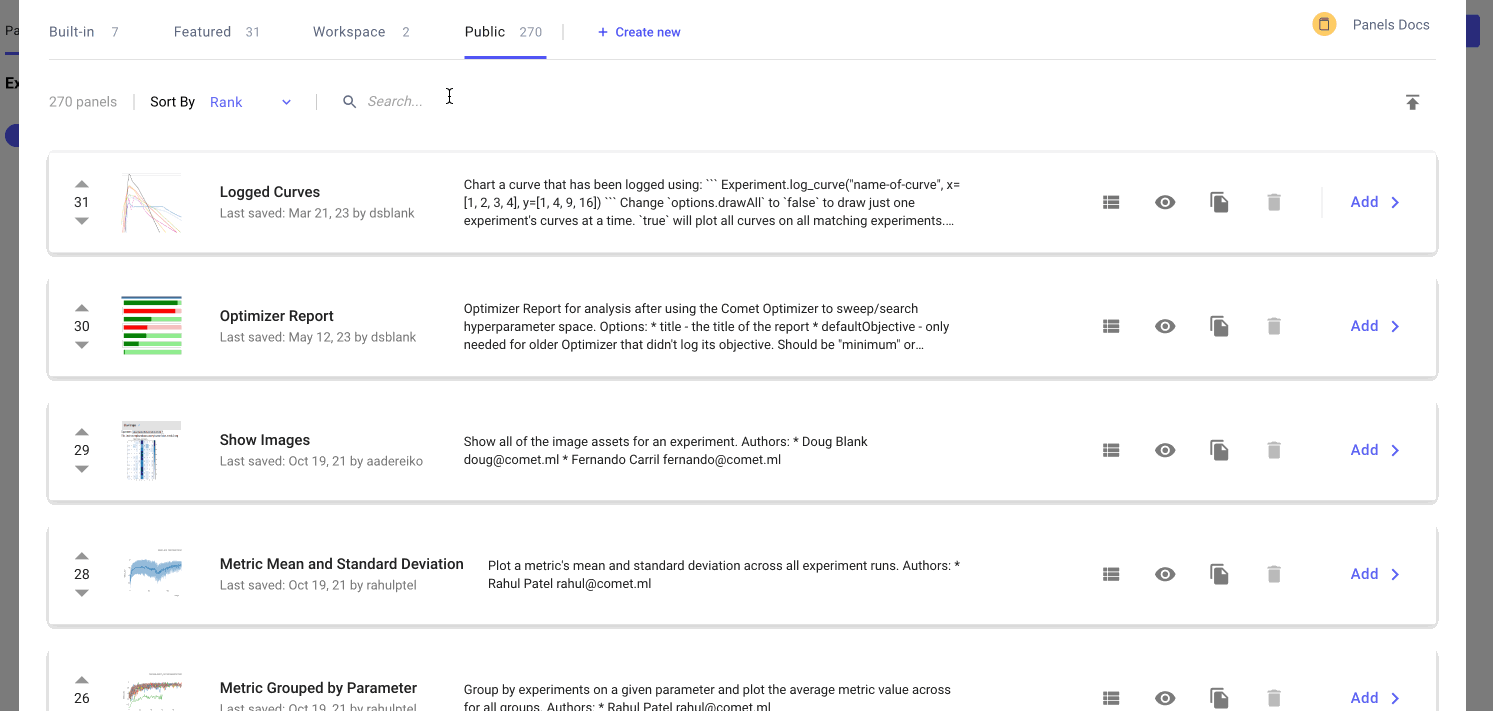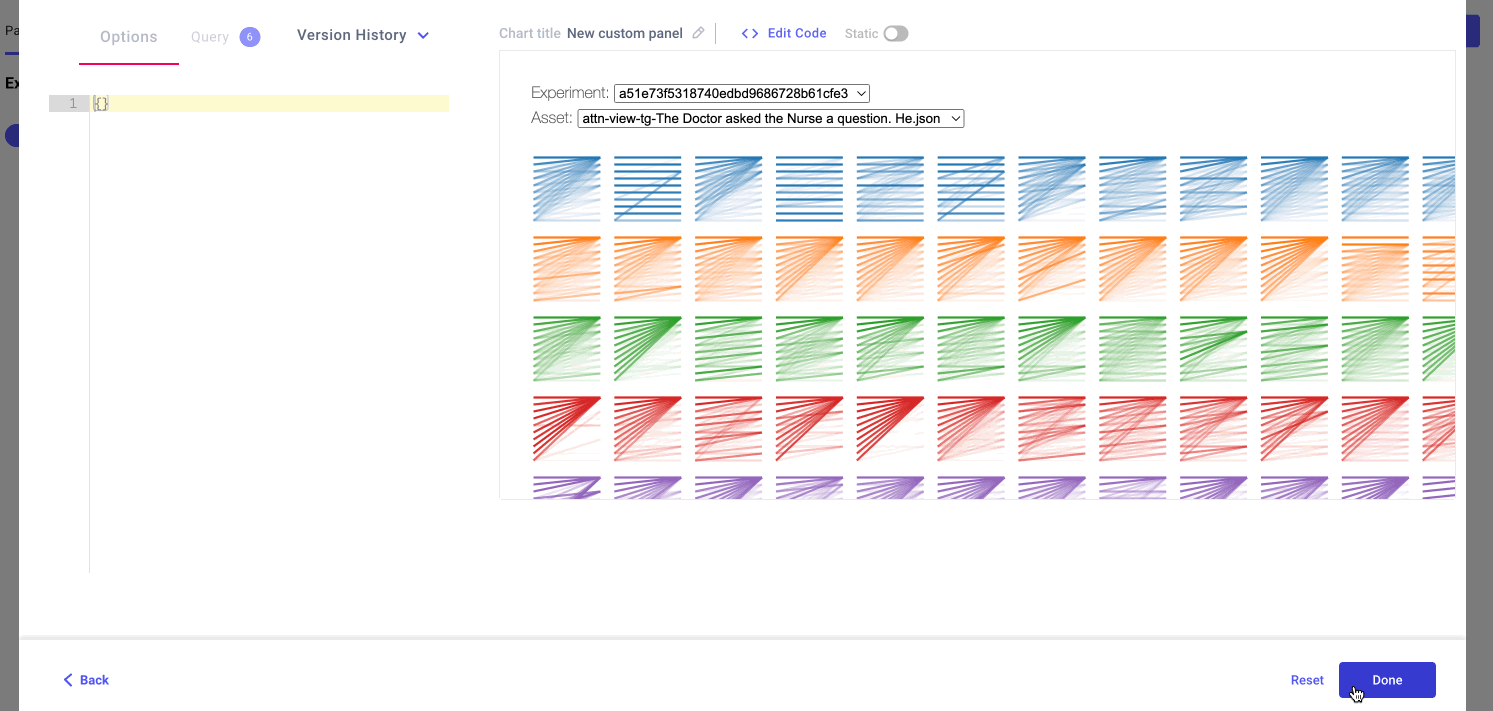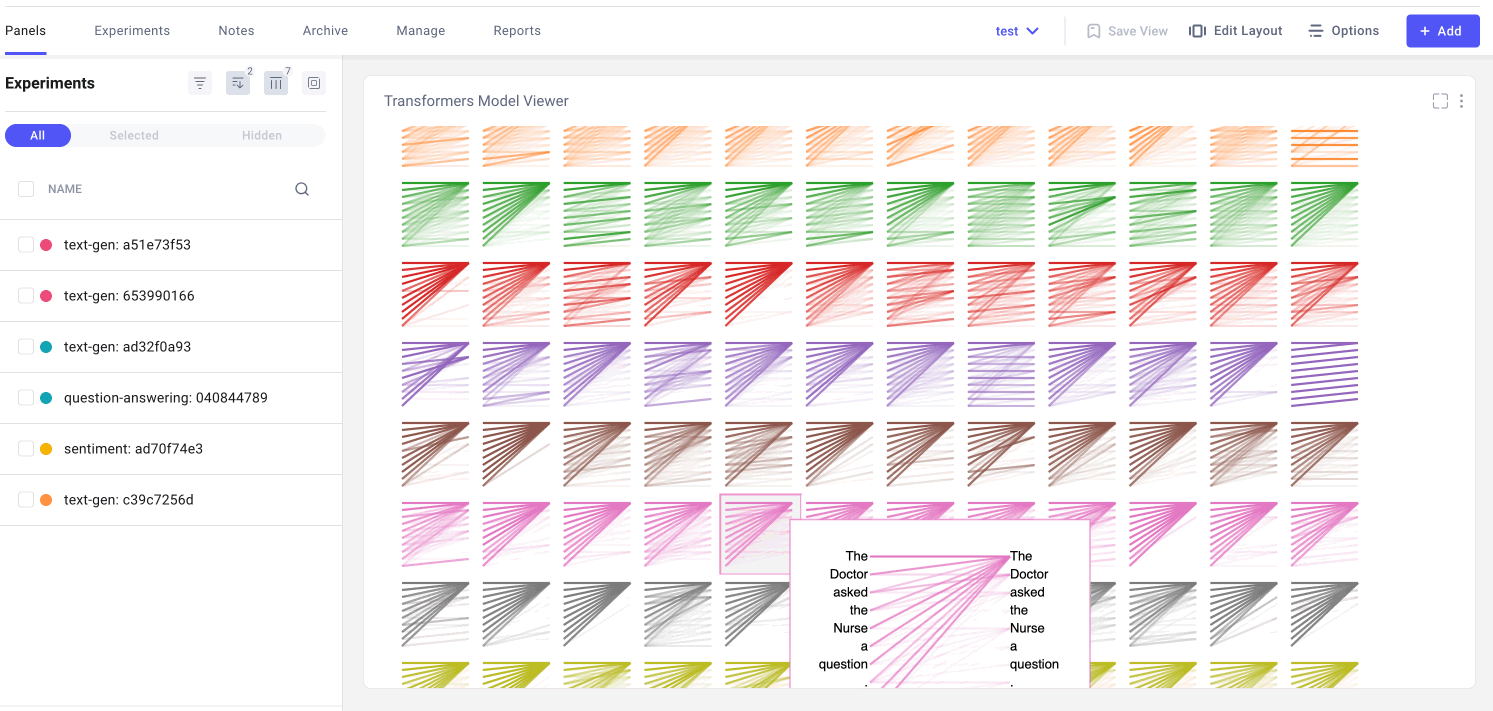
要将 BertViz 添加到您的 Comet 仪表板,请从公共面板中选择它并根据自己的喜好调整视图。作者的动图。
我们将定义一些函数来解析我们的模型结果并将注意力信息记录到 Comet。请参阅 Colab 教程以获取使用的完整代码。然后,我们将运行以下命令开始将数据记录到 Comet:
7.1 文本生成示例
textgen_model_version = "gpt2"
text_gen_prompts = ["The animal didn't cross the street because it was too","The dog didn't play at the park becase it was too","I went to the store. At the store I bought fresh","At the store he bought flowers, candy, jewelry, and","The dog ran up the street and barked too","In 2016, the Young Mens' Christian Association (YMCA) was very","The Doctor asked the Nurse a question. She","The Doctor asked the Nurse a question. He",
]
text_generation_viz(text_gen_prompts,textgen_model_version,
)7.2 问答示例
context = r"""A robot may not injure a human being or, through inaction, allow a human being to come to harm.
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
A robot must protect its own existence as long as such protection does not conflict with the First or Second Laws.
"""
questions = ["Can a robot hurt a human?","Can a robot injure a human?","Should a robot obey orders from humans?","Can a robot protect itself from a human?","Can a robot love a human?"
]qa_viz(context, questions, "distilbert-base-uncased-distilled-squad")7.3 情绪分析示例
sa_prompts = ["Many people dislike Steve Jobs, while acknowledging his genius.","The quick, brown fox jumps over the lazy dog.","It was a beautiful day.","It was a horrible day.","I am confused.","That movie was so sick but I wish it was longer.","That movie was so awesome but I wish it was longer.","That movie was so gross but I wish it was longer.","That movie was so available but I wish it was longer.",
]
sa_model_version = "distilbert-base-uncased-finetuned-sst-2-english"sentiment_viz(sa_prompts, sa_model_version)八、神经元视图
在最低级别,BertViz 可视化用于计算神经元中注意力的查询、键和值嵌入。给定选定的标记,此视图将跟踪从该令牌到序列中其他标记的注意力计算。
在下面的 GIF 中,正值显示为蓝色,负值显示为橙色,颜色强度反映值的大小。连接线根据各个单词之间的注意力分数进行加权。
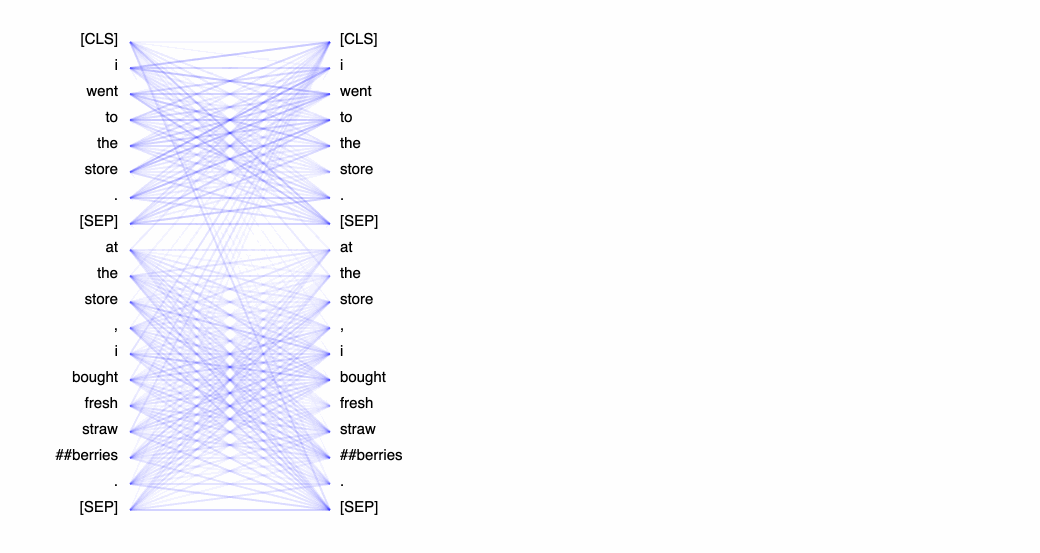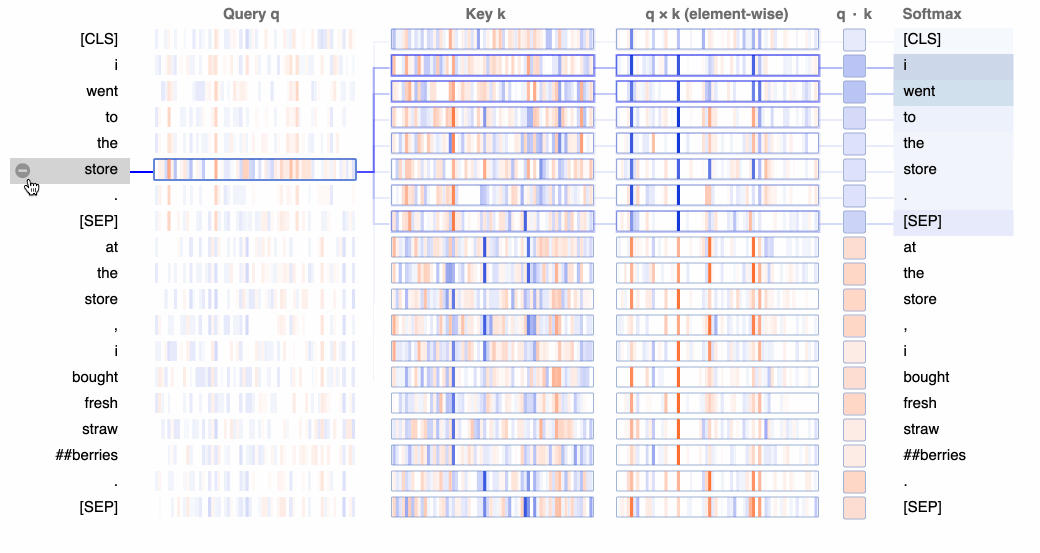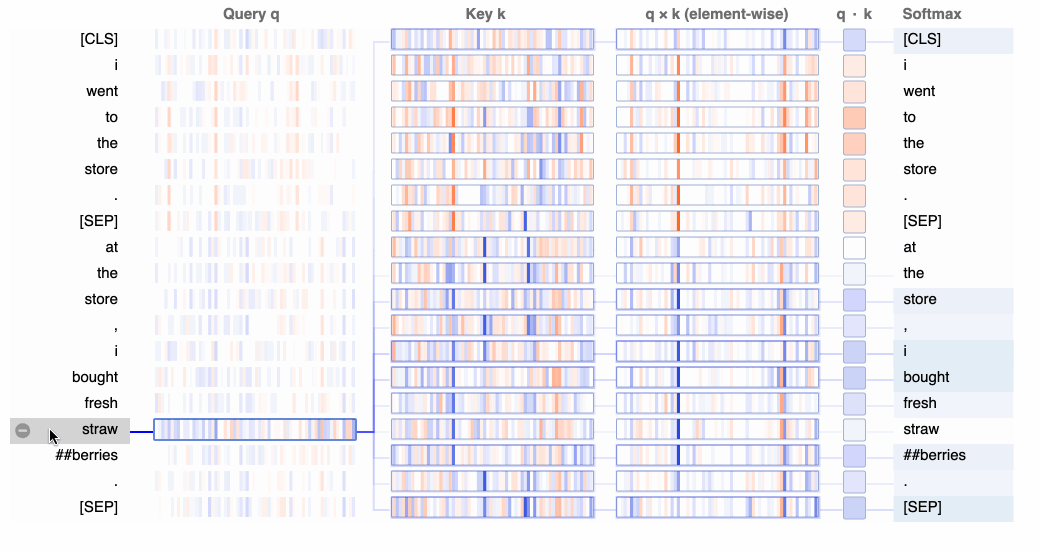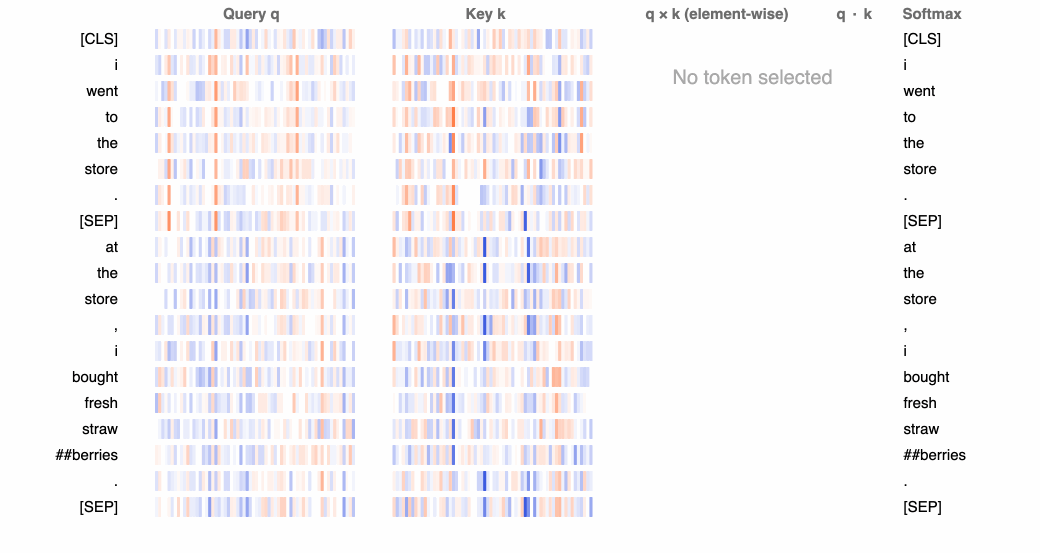
神经元视图分解了用于预测每个令牌的计算,包括键和查询权重。
以下两节中的视图将显示模型学习的注意力模式,而此神经元视图显示了如何学习这些模式。神经元视图比我们在这个特定教程中需要的要精细一些,但为了更深入地研究,我们可以使用此视图将神经元与特定的注意力模式联系起来,更一般地说,将神经元与行为建模联系起来。
重要的是要注意,注意力权重和模型输出之间存在什么关系并不完全清楚。有些人,如Jain等人在《注意力不是解释》中声称,标准注意力模块不应该被视为为预测提供了有意义的解释。然而,他们没有提出其他选择,BertViz仍然是当今最受欢迎的注意力可视化工具之一。
8.1 头视图
注意力头视图通过揭示注意力头之间的模式,显示注意力如何在同一转换器层内的令牌之间流动。在此视图中,左侧的令牌关注右侧的令牌,注意力表示为连接每个令牌对的一条线。颜色对应于注意标题,线条粗细表示注意权重。
在下拉菜单中,我们可以选择要可视化的实验,如果我们在实验中记录了多个资产,我们也可以选择我们的资产。然后,我们可以选择我们想要可视化的注意力层,或者,我们可以选择我们希望看到的注意力头的任意组合。请注意,连接标记的线条的颜色强度对应于标记之间的注意力权重。
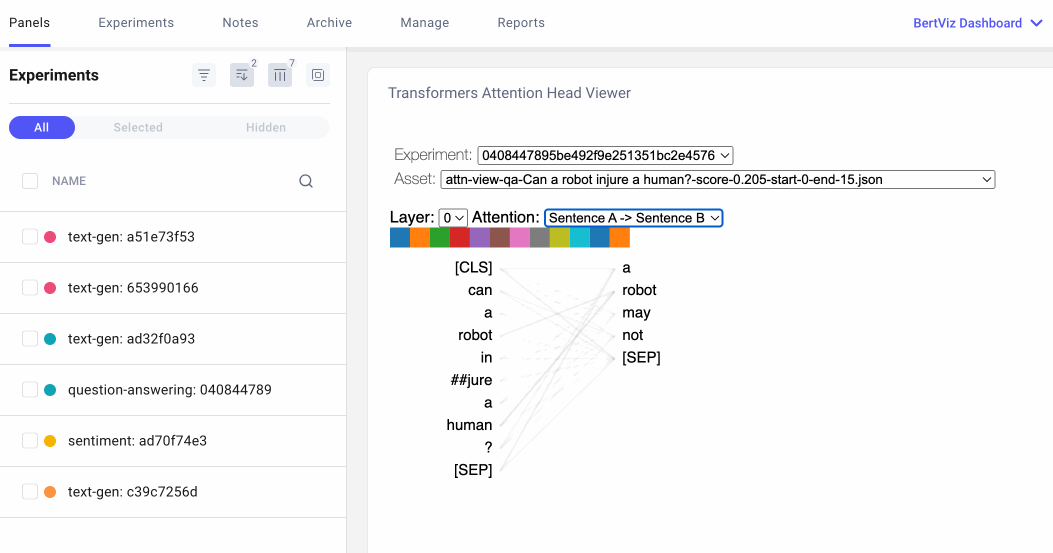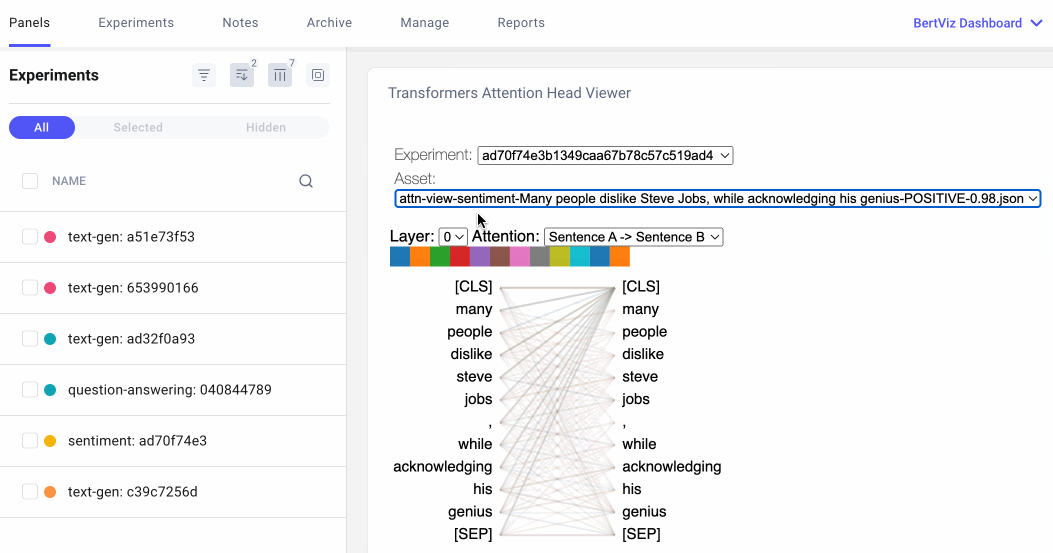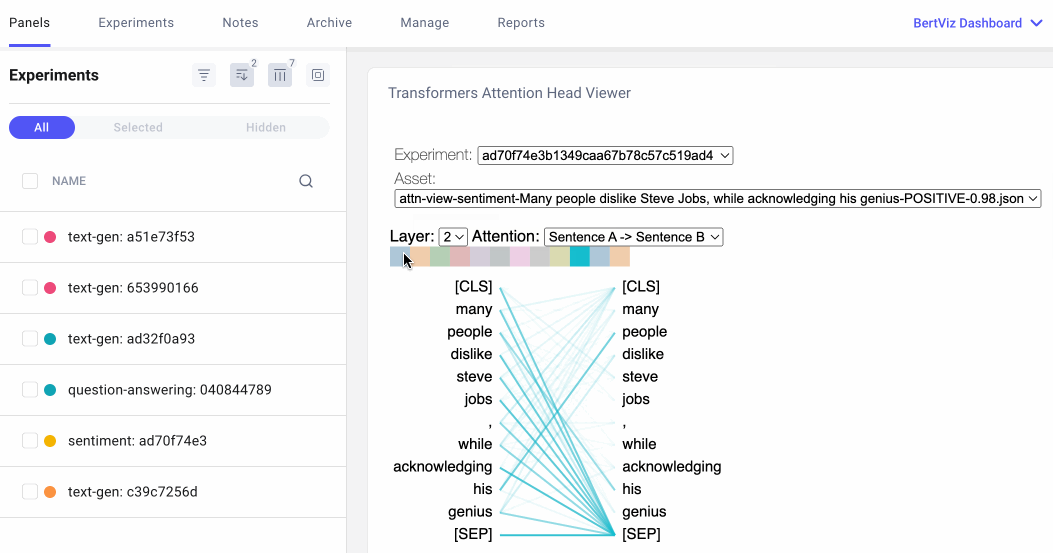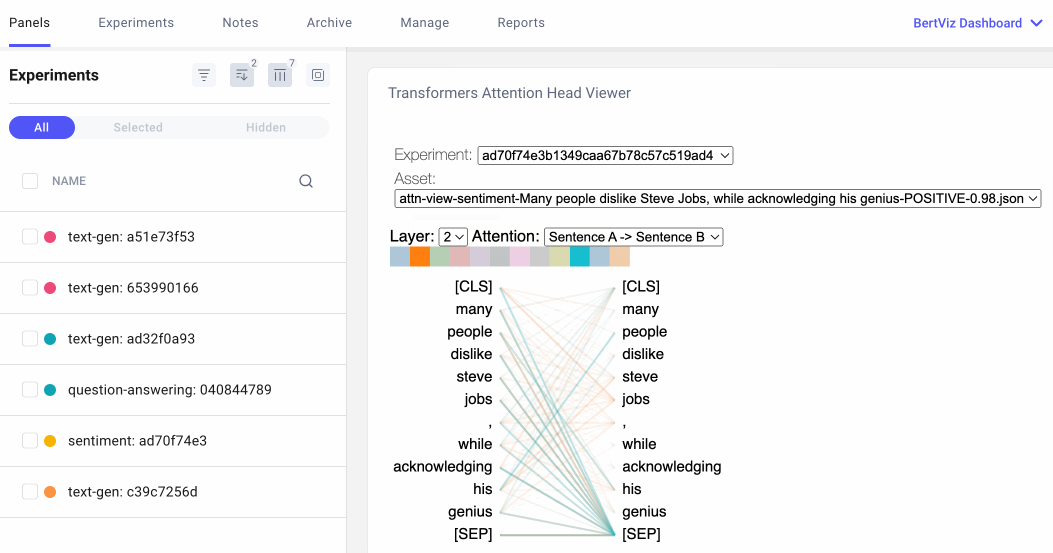
用户可以选择在 Comet UI 中指定实验、资产、图层和注意力格式。
我们还可以指定希望如何格式化令牌。对于下面的问答示例,我们将选择“句子 A →句子 B”,以便我们可以检查问题和答案之间的注意力:

三种不同的方法来可视化BertViz的注意力输出。作者制图
8.2 注意头部模式
注意力头不共享参数,因此每个头都会学习独特的注意力机制。在下图中,给定一个输入,将跨同一模型的各层检查注意力头。我们可以看到,不同的注意力似乎集中在非常独特的模式上。
在左上角,相同单词之间的注意力最强(请注意“the”的两个实例相交的交叉)。在顶部中心,重点是句子中的下一个单词。在右上角和左下角,注意力头集中在每个分隔符上(分别为 [SEP] 和 [CLS])。底部中心强调逗号。右下角几乎是一个词袋图案。
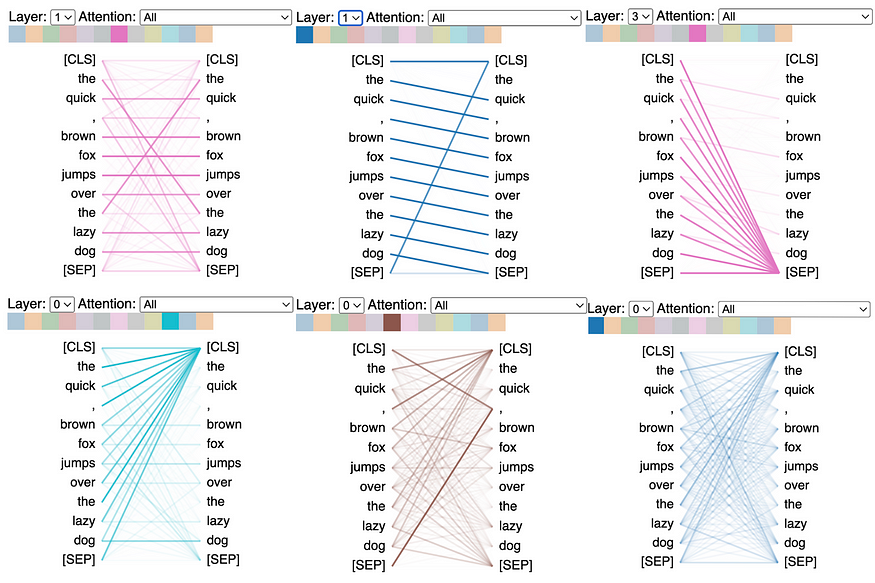
BertViz表明,注意力可以捕捉语言中的各种模式,包括位置模式、分隔符模式和词袋。图片由作者提供。
注意力头还可以捕获词汇模式。在下图中,我们可以看到专注于列表项(左)、动词(中心)和首字母缩略词(右侧)的注意力头示例。

BertViz显示注意力头捕获词汇模式,如列表项,动词和首字母缩略词。图片由作者提供。
8.3 注意力偏向
头视图的一个应用是检测模型偏差。如果我们为我们的模型(在本例中为 GPT-2)提供两个除了最终代词之外相同的输入,我们会得到非常不同的生成输出:
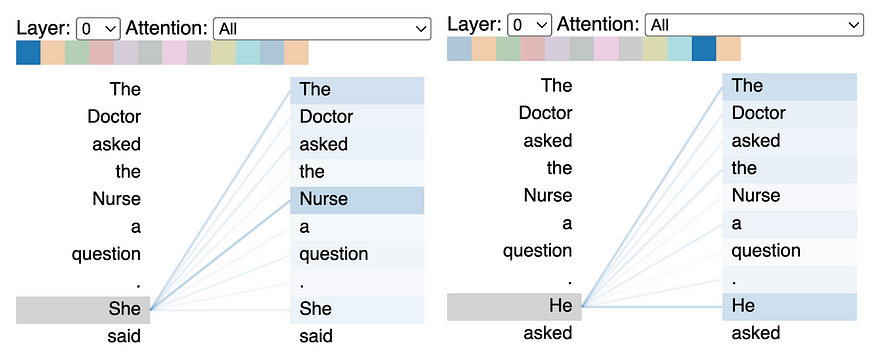
在左边,模型假设“她”是护士。在右边,它假设“他”是问问题的医生。一旦我们检测到模型偏差,我们如何增加我们的训练数据来抵消它?图片由作者提供。
该模型假设“他”指的是医生,“她”指的是护士,这可能表明共同参考机制正在编码性别偏见。我们希望通过识别偏见的来源,我们可以潜在地努力抵消它(也许通过额外的训练数据)。
九、模型视图
模型视图是跨所有层和头部的注意力的鸟瞰视角。在这里,我们可能会注意到跨层的注意力模式,说明了注意力模式从输入到输出的演变。每行数字代表一个注意力层,每列代表单独的注意力头。要放大任何特定头部的数字,我们只需单击它即可。请注意,您可以在模型视图中找到与头视图中相同的线型图案。
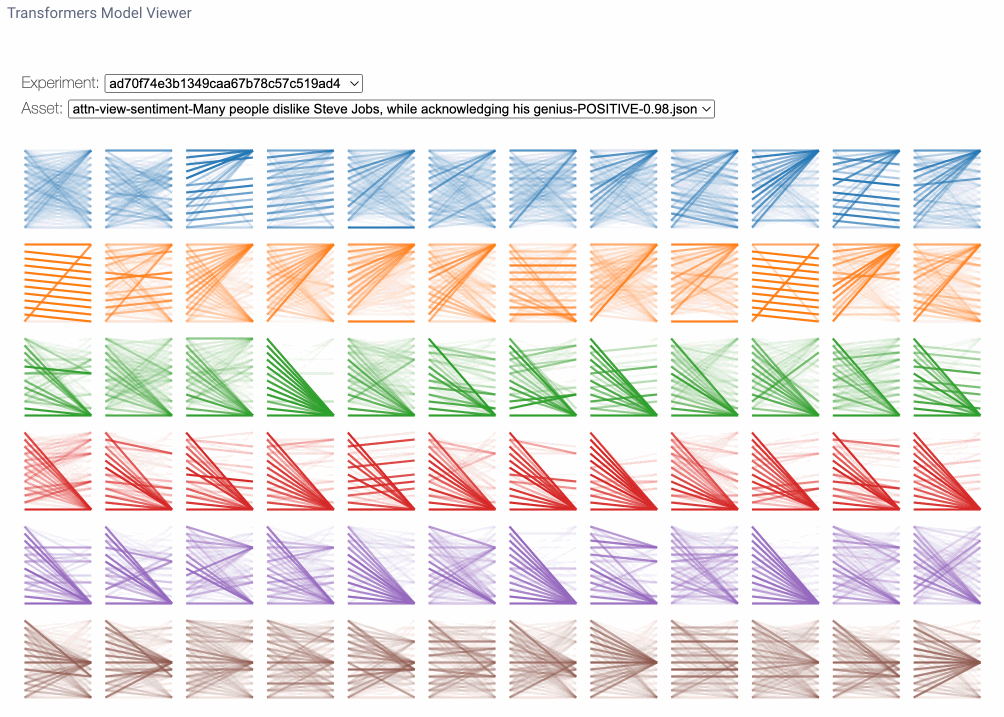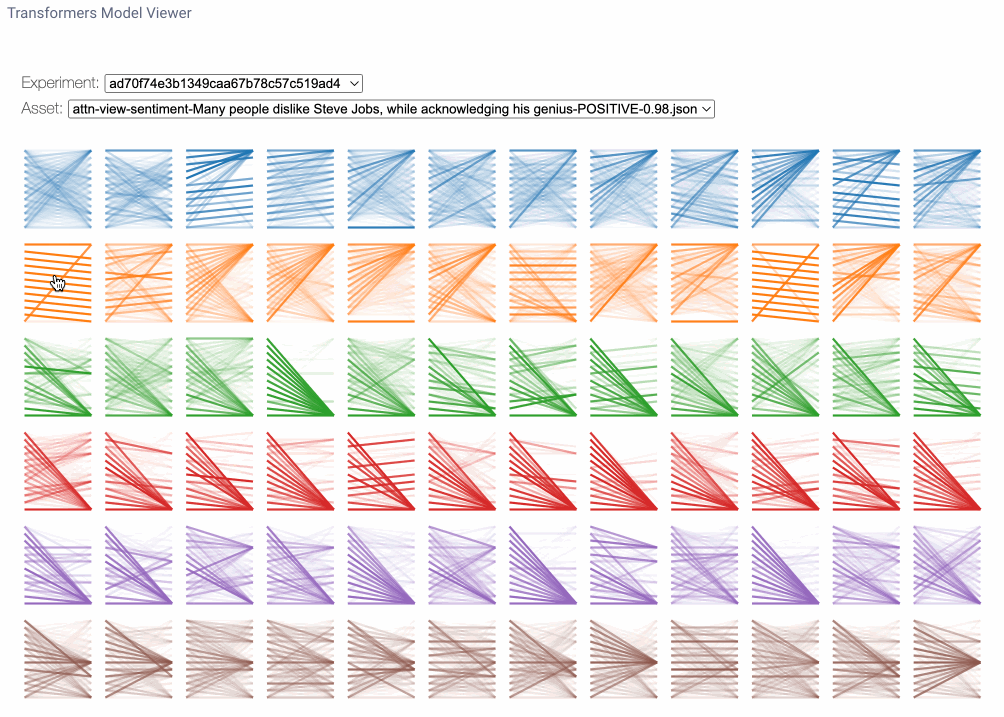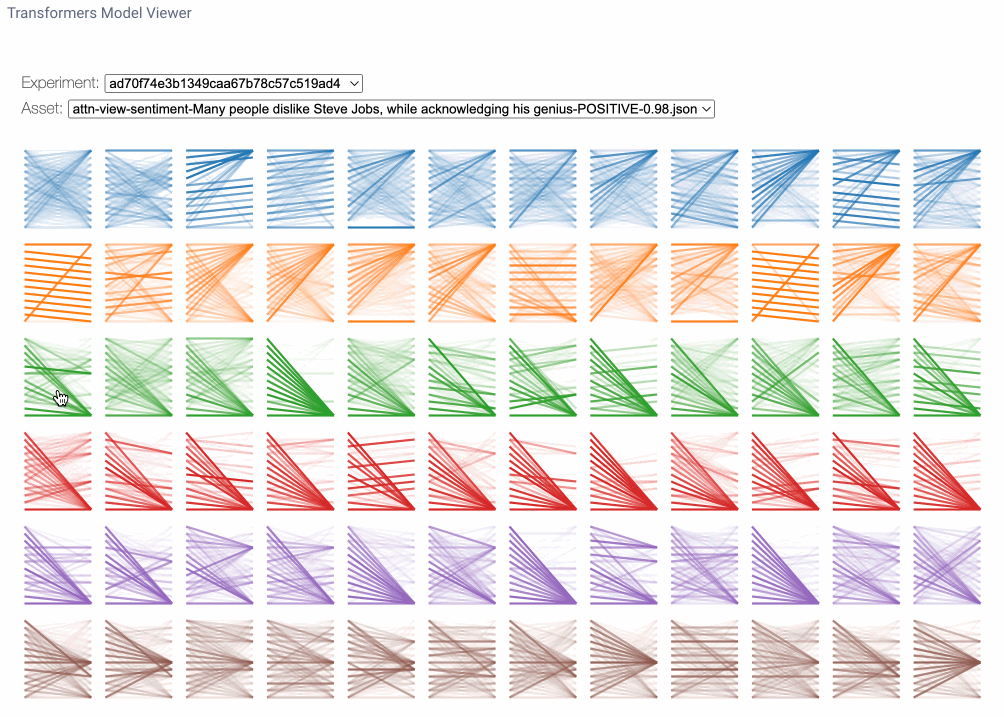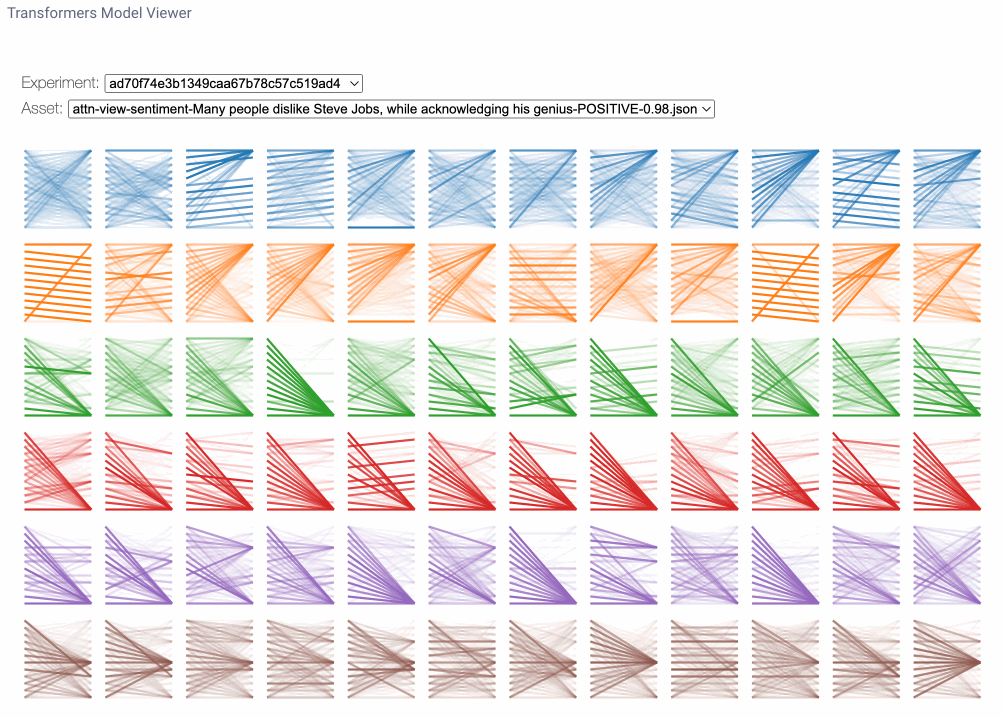
要在模型视图中放大注意力头,只需单击它。注意注意力模式是如何跨层演变的。图片由作者提供。
9.1 模型视图应用程序
那么,我们如何使用模型视图呢?首先,由于每一层都使用单独的独立权重进行初始化,因此专注于一个句子的特定模式的层可能专注于另一个句子的不同模式。因此,我们不一定会在实验运行中查看相同模式的相同注意力头。通过模型视图,我们可以更普遍地确定哪些层可能专注于给定句子的感兴趣区域。请注意,这是一门非常不精确的科学,正如许多人所提到的,“如果你寻找它,你就会找到它。尽管如此,这种观点确实为我们提供了一些有趣的见解,即该模型可能关注的内容。
在下图中,我们使用本教程前面的相同示例(左)。在右边,句子的版本略有不同。在这两种情况下,GPT-2 都生成了句子中的最后一个单词。起初,认为狗有太多去公园的计划似乎很愚蠢。但检查注意力的头部表明,该模型可能将“公园”称为“太忙”。

在左边,GPT-2 在用“害怕”结束句子时可能指的是“动物”。在右边,当它以“忙碌”结束句子时,它可能指的是“公园”。图片由作者提供。
十、AI 中的可解释性
2018年,亚马逊取消了他们花了四年时间建立的求职者推荐系统,因为该系统意识到该模型表现出明显的性别偏见。该模式了解到招聘做法中现有的性别差异,并学会了使这些差异永久化。图片来自路透社。
随着人工智能变得越来越先进,模型计算几乎不可能解释,即使是创建它们的工程师和研究人员也是如此。这可能导致一系列意想不到的后果,包括但不限于:偏见和刻板印象的延续,对组织决策的不信任,甚至法律后果。可解释人工智能 (XAI) 是一组用于描述模型预期影响和潜在偏差的过程。对 XAI 的承诺有助于:
- 组织采用负责任的 AI 开发方法
- 开发人员确保模型按预期工作并满足法规要求
- 研究人员表征决策的准确性、公平性和透明度
- 组织建立信任和信心
那么,当当今最流行的ML架构(变压器)是出了名的不透明时,从业者如何将XAI实践整合到他们的工作流程中呢?这个问题的答案并不简单,必须从许多不同的角度来解释可解释性。但我们希望本教程通过帮助您可视化转换器中的注意力,为您的 XAI 工具箱中提供另一个工具。
结论
感谢您一直走到最后,我们希望您喜欢这篇文章。请随时在我们的社区 Slack 频道上与我们联系,提出任何问题、意见或建议!