做网站需要icp吗忻州网站seo
参考:https://blog.csdn.net/qq_37858386/article/details/123755700
二、网络adb调试开启步骤
1、把Android平板或者手机WiFi连接到跟PC机子同一个网段的网络,在设置-系统-关于-状态 下面查看设备IP,然后查看PC是否可以ping通手机的设备的IP。
2、先通过手机充电线(USB线)连接平板,确保adb可以正常使用。
3、开启tcp/ip调试端口 ,5555为网络 adb 的默认端口。
adb tcpip 5555
3、使用网络进行adb调试。
adb connect <Android设备IP地址>
4、进入到Android设备shell adb shell
5、拔掉usb线,网络adb可以使用,如下图
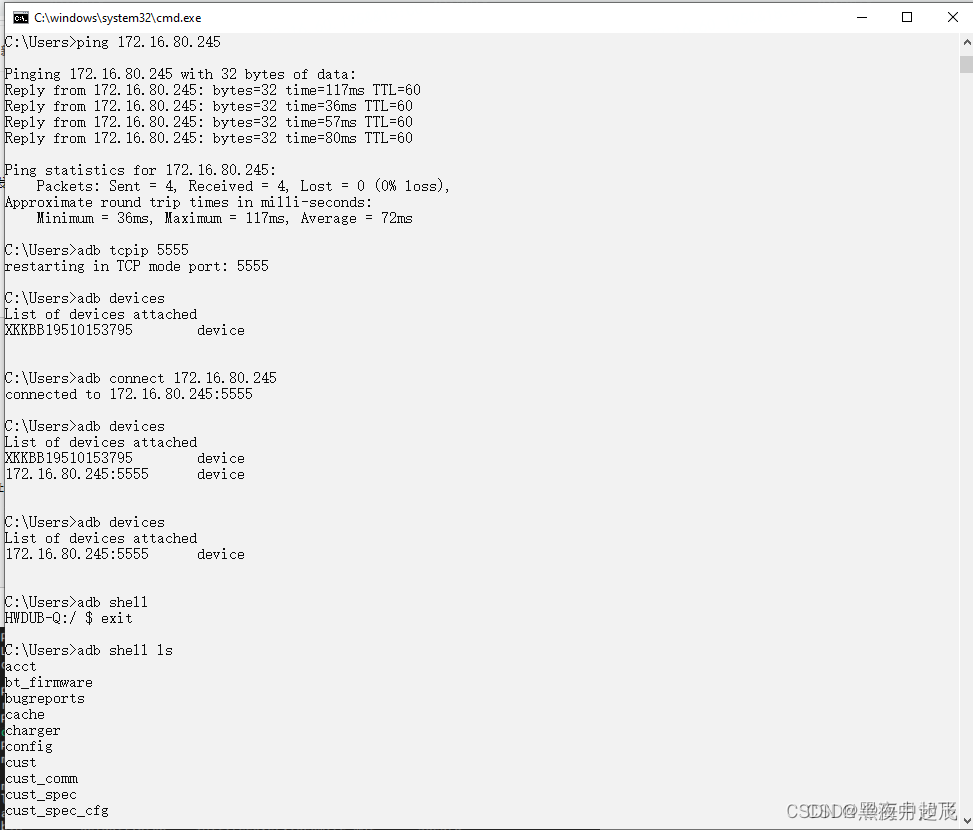
确认adb开启wifi链接功能
adb tcpip 5555
确认可以连接到手机
ping 10.254.1.181
看下当前环境下连接的手机 –
adb devices
// 连接当前手机
adb connect 10.254.1.181
// 查看连接状况
adb shell
问题一 missing port in specification: tcp:10.254.1.181
如果报上面的错误 加上5555,或者看下手机上的端口号
问题二 cannot connect to 10.254.1.xxx:5555: 由于目标计算机积极拒绝,无法连接。 (10061)
先ping一下电脑,pin通继续,pin不通就是网络问题
使用USB连接电脑,然后执行以下命令行:
// 让手机可以被TCP/IP(网络)连接到
adb tcpip 5555
adb connect IP地址:5555
问题三 手机出现:离线状态
- 打开无线调试
- 开关USB调试
- adb kill-server
- adb connect 10.254.1.181
- adb devices