贵州贵阳建网站的电话互联网广告公司是做什么的
Redis限流接口防刷
Redis 除了做缓存,还能干很多很多事情:分布式锁、限流、处理请求接口幂等性。。。太多太多了~
大家好,我是llp,许久没有写博客了,今天就针对Redis实现接口限流做个记录。废话不多说,我们先看下需求|应用场景
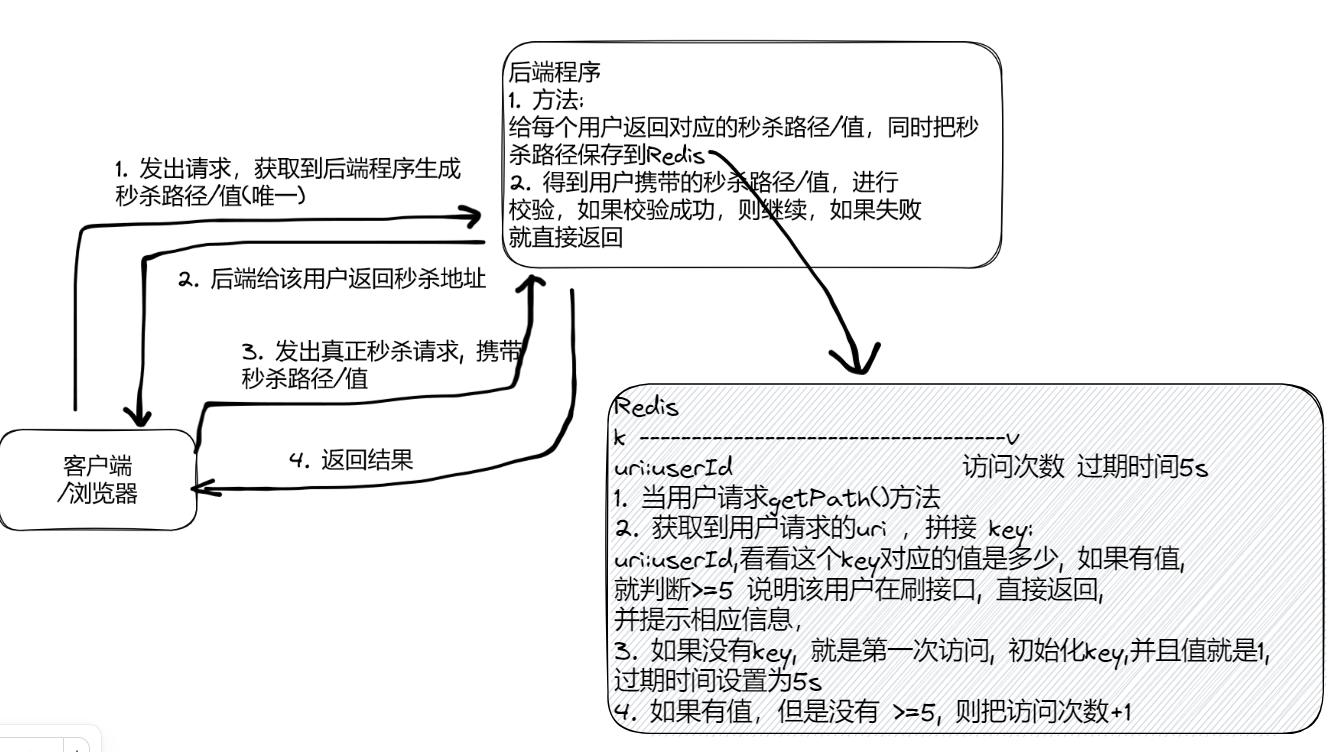
1.需求分析/图解
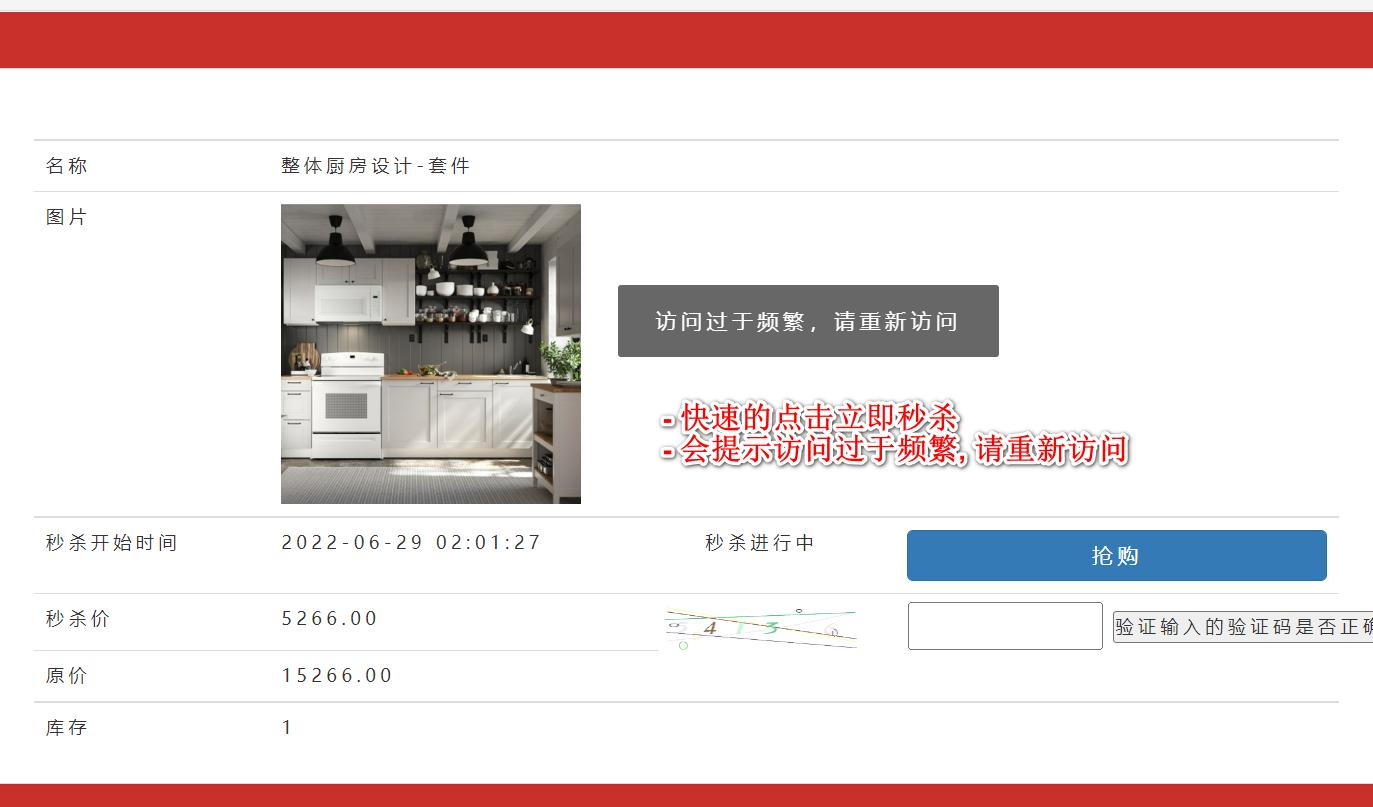
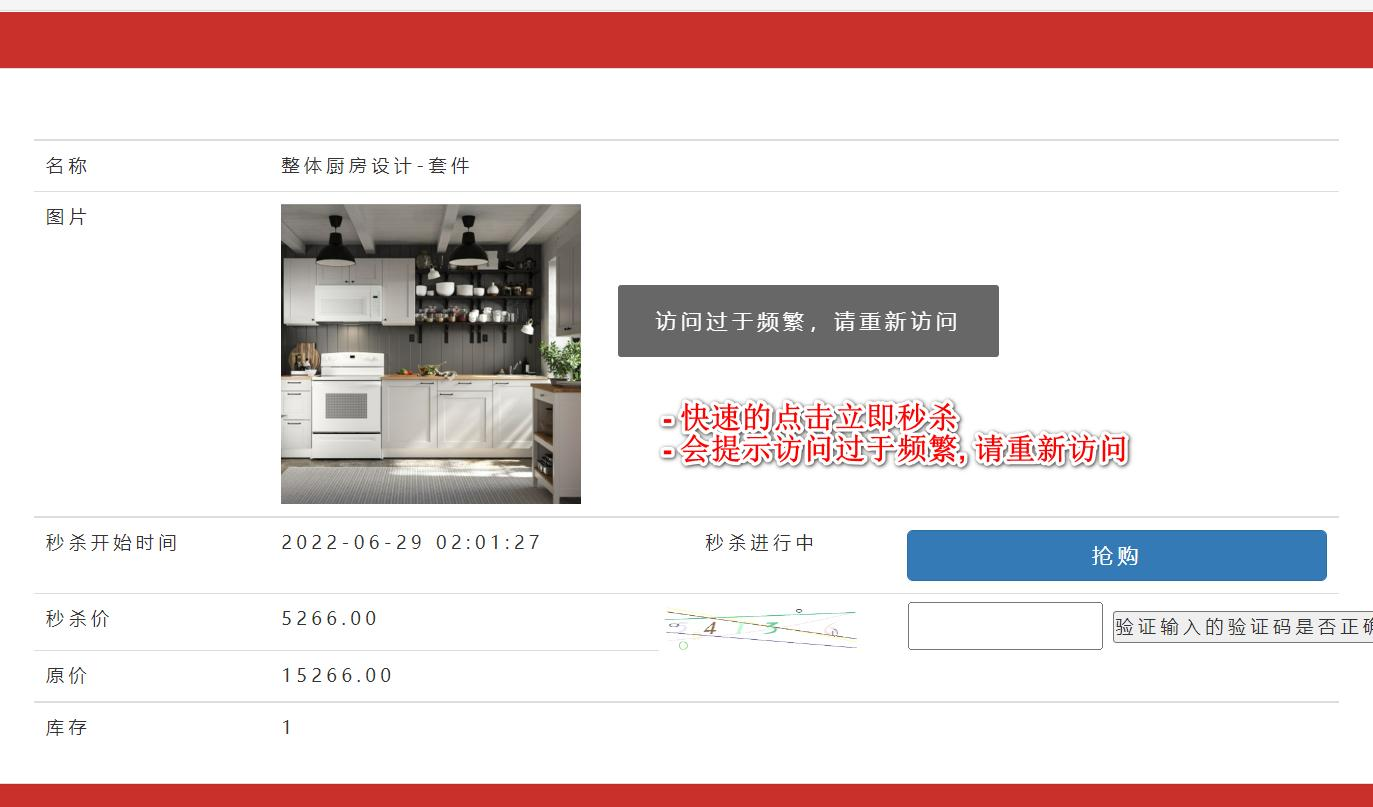
- 完成接口限流-防止某个用户频繁的请求秒杀接口
- 比如在短时间内,频繁点击抢购,我们需要给用户访问频繁的提示, 示意图
2.简单接口限流
- 使用简单的 Redis 计数器, 完成接口限流防刷
- 除了计数器算法,也有其它的算法来进行接口限流, 比如漏桶算法和令牌桶算法 (参考:https://zhuanlan.zhihu.com/p/165006444)
- 令牌桶算法, 相对比较主流, 可以关注一下.
- 代码实现
@RequestMapping(value = "/path", method = RequestMethod.GET)
@ResponseBody
public RespBean getPath(User user, Long goodsId, String captcha, HttpServletRequest request) {if (user == null) {return RespBean.error(RespBeanEnum.SESSION_ERROR);}// 秒杀 v7.0 计数器 redis,5 秒内访问超过 5 次,就认为是刷接口String uri = request.getRequestURI();ValueOperations valueOperations = redisTemplate.opsForValue();Integer count = (Integer) valueOperations.get(uri + ":" + user.getId());if (count == null) {//用户在5秒内没有访问过该接口,key=uri + ":" + user.getId() value = 1valueOperations.set(uri + ":" + user.getId(), 1, 5, TimeUnit.SECONDS);} else if (count < 5) {//用户在5秒内访问过该接口,但访问次数<5则,进行+1valueOperations.increment(uri + ":" + user.getId());} else {//用户在5秒内访问次数>5,则对接口进行限流,提示用户访问过于频繁return RespBean.error(RespBeanEnum.ACCESS_LIMIT_REACHED);}//验证用户输入的验证码boolean check = orderService.checkCaptcha(user, goodsId, captcha);if (!check) {return RespBean.error(RespBeanEnum.CAPTCHA_ERROR);}//创建真正的地址String url = orderService.createPath(user, goodsId);return RespBean.success(url);
}
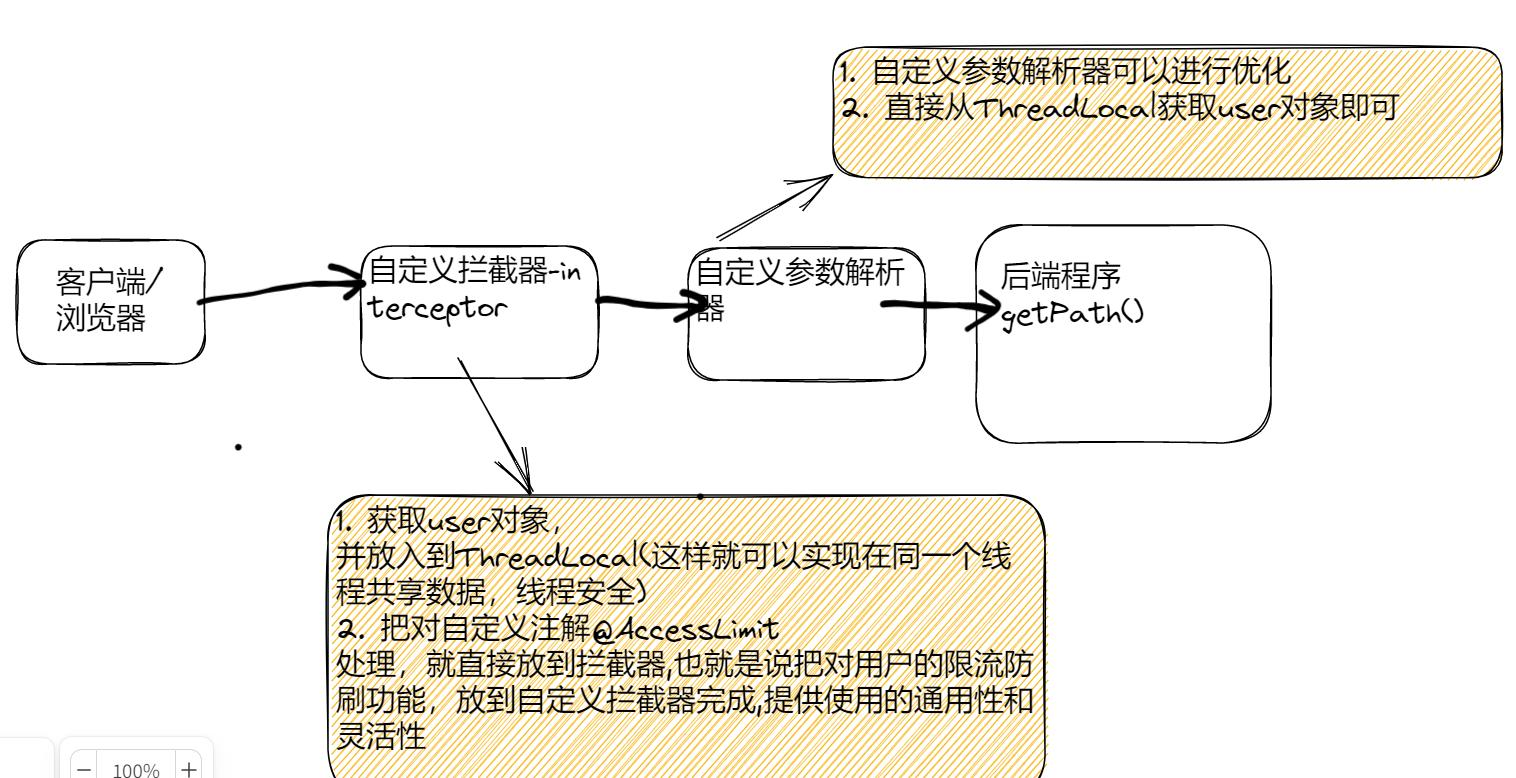
3.基于注解实现接口限流
- 自定义注解@AccessLimit, 提高接口限流功能通用性 , 减少冗余代码, 同时也减少业
务代码入侵
- 思路分析-简单示意图
代码实现
自定义限流注解
/*** 限流注解*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface AccessLimit {//定义限制多少秒内进行限流int second();//定义多少秒内,接口最大访问次数int maxCount();//接口是否需要验证登录信息boolean needLogin() default true;
}
限流拦截器
@Component
public class AccessLimitInterceptor implements HandlerInterceptor {@Resourceprivate UserService userService;@Resourceprivate RedisTemplate redisTemplate;/*** 1.preHandle 方法在目标方法执行前被执行* 2.如果返回fasle则不在执行目标方法** @param request* @param response* @param handler* @return* @throws Exception*/@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {if (handler instanceof HandlerMethod) {User user = getUser(request, response);UserContext.setUser(user);HandlerMethod handlerMethod = (HandlerMethod) handler;AccessLimit accessLimit = handlerMethod.getMethodAnnotation(AccessLimit.class);if (accessLimit == null) {//没有,直接放行return true;}boolean needLogin = accessLimit.needLogin();int limitCount = accessLimit.maxCount();int second = accessLimit.second();if (needLogin && user == null) {render(response, RespBeanEnum.SESSION_ERROR);return false;}String uri = request.getRequestURI();ValueOperations valueOperations = redisTemplate.opsForValue();Integer count = (Integer) valueOperations.get(uri + ":" + user.getId());if (count == null) {//用户在5秒内没有访问过该接口,key=uri + ":" + user.getId() value = 1valueOperations.set(uri + ":" + user.getId(), 1, second, TimeUnit.SECONDS);} else if (count < limitCount) {//用户在5秒内访问过该接口,但访问次数<5则,进行+1valueOperations.increment(uri + ":" + user.getId());} else {//用户在5秒内访问次数>5,则对接口进行限流,提示用户访问过于频繁//返回错误信息render(response, RespBeanEnum.ACCESS_LIMIT_REACHED);return false;}}return true;}/*** 渲染错误信息返回** @param response* @param respBeanEnum*/private void render(HttpServletResponse response, RespBeanEnum respBeanEnum) throws IOException {System.out.println("render-" + respBeanEnum.getMessage());response.setContentType("application/json");response.setCharacterEncoding("utf-8");PrintWriter out = response.getWriter();RespBean error = RespBean.error(respBeanEnum);out.write(new ObjectMapper().writeValueAsString(error));out.flush();out.close();}//获取当前用户private User getUser(HttpServletRequest request, HttpServletResponse response) {String ticket = CookieUtil.getCookieValue(request, "userTicket");if (!StringUtils.hasText(ticket)) {return null;}return userService.getUserByTicket(request, response, ticket);}
}
测试方法
@RequestMapping(value = "/path", method = RequestMethod.GET)
@ResponseBody
/*** @AccessLimit(second = 5, maxCount = 5, needLogin = true)* 1. 使用注解的方式完成通用的接口防刷功能* 2. second = 5, maxCount = 5 5 秒内,最多 5 次请求,否性进行限流* 3. needLogin = true 表示需要登录*/
@AccessLimit(second = 5, maxCount = 5, needLogin = true)
public RespBean getPath(User user, Long goodsId, String captcha, HttpServletRequest request) {if (user == null) {return RespBean.error(RespBeanEnum.SESSION_ERROR);}// 秒杀 v7.0 计数器 redis,5 秒内访问超过 5 次,就认为是刷接口String uri = request.getRequestURI();ValueOperations valueOperations = redisTemplate.opsForValue();Integer count = (Integer) valueOperations.get(uri + ":" + user.getId());if (count == null) {//用户在5秒内没有访问过该接口,key=uri + ":" + user.getId() value = 1valueOperations.set(uri + ":" + user.getId(), 1, 5, TimeUnit.SECONDS);} else if (count < 5) {//用户在5秒内访问过该接口,但访问次数<5则,进行+1valueOperations.increment(uri + ":" + user.getId());} else {//用户在5秒内访问次数>5,则对接口进行限流,提示用户访问过于频繁return RespBean.error(RespBeanEnum.ACCESS_LIMIT_REACHED);}//验证用户输入的验证码boolean check = orderService.checkCaptcha(user, goodsId, captcha);if (!check) {return RespBean.error(RespBeanEnum.CAPTCHA_ERROR);}//创建真正的地址String url = orderService.createPath(user, goodsId);return RespBean.success(url);
}
//用来存储拦截器获取的 user 对象
public class UserContext {//每个线程都有自己的 threadlocal,存在这里不容易混乱,线程安全private static ThreadLocal<User> userHolder = ThreadLocal.withInitial(() -> null);public static void setUser(User user) {userHolder.set(user);}public static User getUser() {return userHolder.get();}}
注册拦截器
@EnableWebMvc
@Configuration
public class WebConfig implements WebMvcConfigurer {@Resourceprivate UserArgumentResolver userArgumentResolver;@Resourceprivate AccessLimitInterceptor accessLimitInterceptor;/*** 注册拦截器*/@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(accessLimitInterceptor);}/*** 静态资源加载** @param registry*/@Overridepublic void addResourceHandlers(ResourceHandlerRegistry registry) {registry.addResourceHandler("/**").addResourceLocations("classpath:/static/");}/*** 将自定义参数解析器添加到解析器列表中** @param resolvers*/@Overridepublic void addArgumentResolvers(List<HandlerMethodArgumentResolver> resolvers) {resolvers.add(userArgumentResolver);}}
测试结果