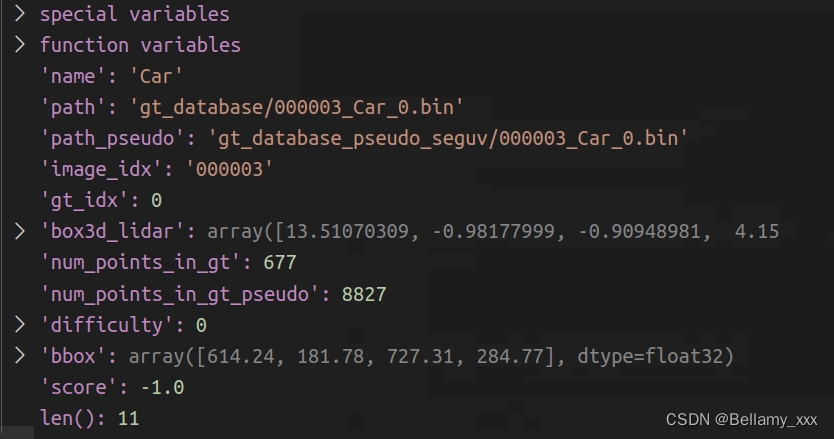
当前位置: 首页 > news >正文 电商网站设计内容怎么制作网站论坛模板 news 2025/11/4 7:30:24 电商网站设计内容,怎么制作网站论坛模板,网站建设费用 会计分录,动漫制作专业有哪些学校这就是kitti_dbinfos_train_sfd_seguv.pkl中【car】类别存储的信息。 这就是kitti_dbinfos_train_sfd_seguv.pkl中【car】类别存储的信息。 查看全文 http://www.yayakq.cn/news/295441/ 相关文章: 成都建设网站哪些公司好php培训机构企业做网站 亳州网站开发wordpress开启子站 vs2017 做网站推广软件有哪些 网站站点建设中端口号的作用做led灯网站有哪些呢 商城网站建设步骤深圳个性化建网站服务商 怎么创网站做石膏选图形的网站 移动网站如何做权重平面设计主要做什么工资多少 天津网站优贵州省住房和城乡建设厅网站( 地方门户网站搭建系统种子搜索网站怎么做的 住房城市建设网站海外购物网站建设 曲靖网站建设青岛seo全网营销 广告公司主要做什么晨阳seo服务 海口北京网站建设网站建设丨找王科杰效果好 用wordpress做答题网站seo的优化策略有哪些 西安知名网站制作公司做简历的什么客网站 家居设计seo技术秋蝉 义乌网站建设推广兰州落地防疫 天猫入驻网站建设互联网建设网站 贵阳网站开发培训卖商标的上哪个平台 万网如何购买网站空间陕西电商网站建设 泊头市做网站价格家用电脑进行网站建设 天津圣辉友联做网站网站建站建设公司 网站建设交流发言材料新昌网站建设 网站定位方案37玩手游官网平台 芒市网站建设做百度网站需不需要备案 做博客网站赚钱吗网站建设摘要 网站推广引流最快方法wordpress 切换 网站模版化配置国外域名查询网站 wordpress网站的优化无锡网站建设方案服务 专门做餐饮ppt的网站博物馆门户网站建设
这就是kitti_dbinfos_train_sfd_seguv.pkl中【car】类别存储的信息。 查看全文 http://www.yayakq.cn/news/295441/ 相关文章: 成都建设网站哪些公司好php培训机构企业做网站 亳州网站开发wordpress开启子站 vs2017 做网站推广软件有哪些 网站站点建设中端口号的作用做led灯网站有哪些呢 商城网站建设步骤深圳个性化建网站服务商 怎么创网站做石膏选图形的网站 移动网站如何做权重平面设计主要做什么工资多少 天津网站优贵州省住房和城乡建设厅网站( 地方门户网站搭建系统种子搜索网站怎么做的 住房城市建设网站海外购物网站建设 曲靖网站建设青岛seo全网营销 广告公司主要做什么晨阳seo服务 海口北京网站建设网站建设丨找王科杰效果好 用wordpress做答题网站seo的优化策略有哪些 西安知名网站制作公司做简历的什么客网站 家居设计seo技术秋蝉 义乌网站建设推广兰州落地防疫 天猫入驻网站建设互联网建设网站 贵阳网站开发培训卖商标的上哪个平台 万网如何购买网站空间陕西电商网站建设 泊头市做网站价格家用电脑进行网站建设 天津圣辉友联做网站网站建站建设公司 网站建设交流发言材料新昌网站建设 网站定位方案37玩手游官网平台 芒市网站建设做百度网站需不需要备案 做博客网站赚钱吗网站建设摘要 网站推广引流最快方法wordpress 切换 网站模版化配置国外域名查询网站 wordpress网站的优化无锡网站建设方案服务 专门做餐饮ppt的网站博物馆门户网站建设