如何让网站被百度收录网站建设要做哪些前期准备工作
大致介绍了一下C/C++内存管理、new与delete后:C++初阶:C/C++内存管理、new与delete详解
我们接下来终于进入了模版的学习了,今天就先来入门泛型编程
文章目录
- 1.泛型编程
- 2.函数模版
- 2.1概念
- 2.2格式
- 2.3函数模版的原理
- 2.4函数模版的实例化
- 2.4.1隐式实例化
- 2.4.2显示实例化
- 2.5 模板参数的匹配原则
- 3.类模板
- 3.1概念
- 3.2格式
- 3.3类模板的实例化
1.泛型编程
**泛型编程是一种编程范式,旨在编写可以适用于多种数据类型的通用代码。通过泛型编程,我们可以编写一次代码,然后将其应用于不同的数据类型,从而避免重复编写相似的代码 **
之前我们面对多种类型只能这样干:
int Swap(int& a, int& b)
{int temp = a;a = b;b = temp;
}void Swap(double& a, double& b)
{double temp = a;a = b;b = temp;
}int main()
{int a = 1, b = 2;double c = 1.1, d = 2.2;Swap(a, b);Swap(c, d);return 0;
}
使用函数重载虽然可以实现,但是有一下几个不好的地方:
重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数
代码的可维护性比较低,一个出错可能所有的重载均出错
现在就轮到泛型编程出场了:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
2.函数模版
2.1概念
函数模板是一种允许我们编写通用函数的工具。通过函数模板,我们可以定义一个函数,其中的某些类型可以是通用的,从而使函数能够处理多种数据类型。函数模板使用
template关键字定义,并使用一个或多个类型参数来表示通用的类型。
2.2格式
template<typename T1, typename T2,......,typename Tn>//一个或多个 返回值类型 functionName(T parameter1, T parameter2, ...) {// 函数体 }
template <typename T>:使用template关键字定义函数模板,并在尖括号中指定一个或多个类型参数.- typename是用来定义模板参数关键字,也可以使用class
functionName:函数模板的名称。T parameter1, T parameter2, ...:函数模板的参数列表,参数类型为通用的类型T
单模版参数:
template<class T>
void Swap(T& a, T& b)
{T temp = a;a = b;b = temp;
}
多模版参数:
template<class T ,class Y>
void print(T& a, Y& b)
{cout << a << " " << b << endl;
}int main()
{int a = 1;double b = 1.1;print(a, b);return 0;
}
2.3函数模版的原理
我们可以认为:函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器
当使用函数模板时,编译器会根据传入的参数类型来实例化模板,并生成对应的函数。
还是这段代码:
template<class T>
void Swap(T& a, T& b)
{T temp = a;a = b;b = temp;
}int main()
{int a = 1, b = 2;double c = 1.1, d = 2.2;Swap(a, b);Swap(c, d);return 0;
}
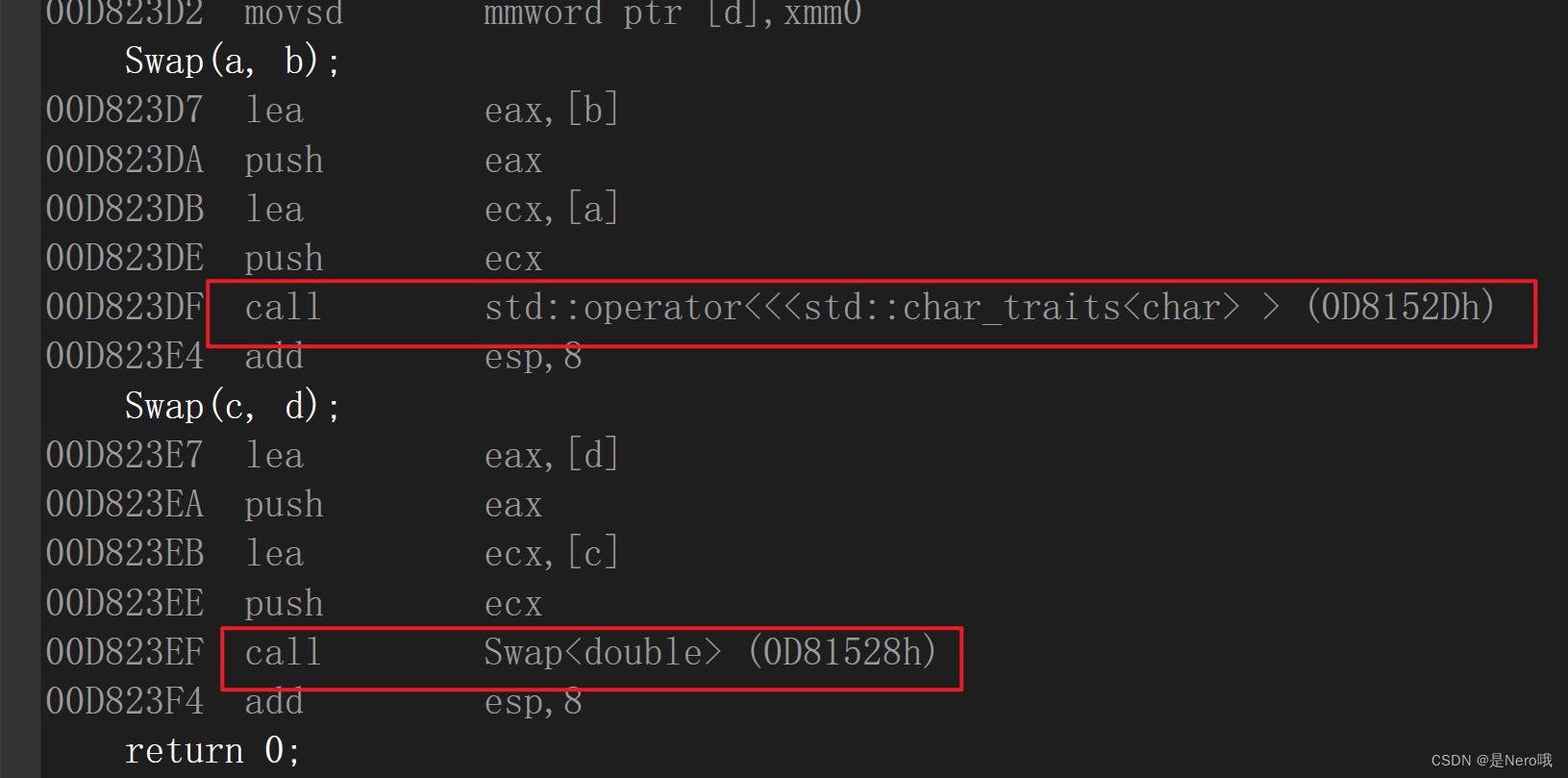
转到反汇编看后发现:两处调用函数的地址不一样,这说明不是同一个函数
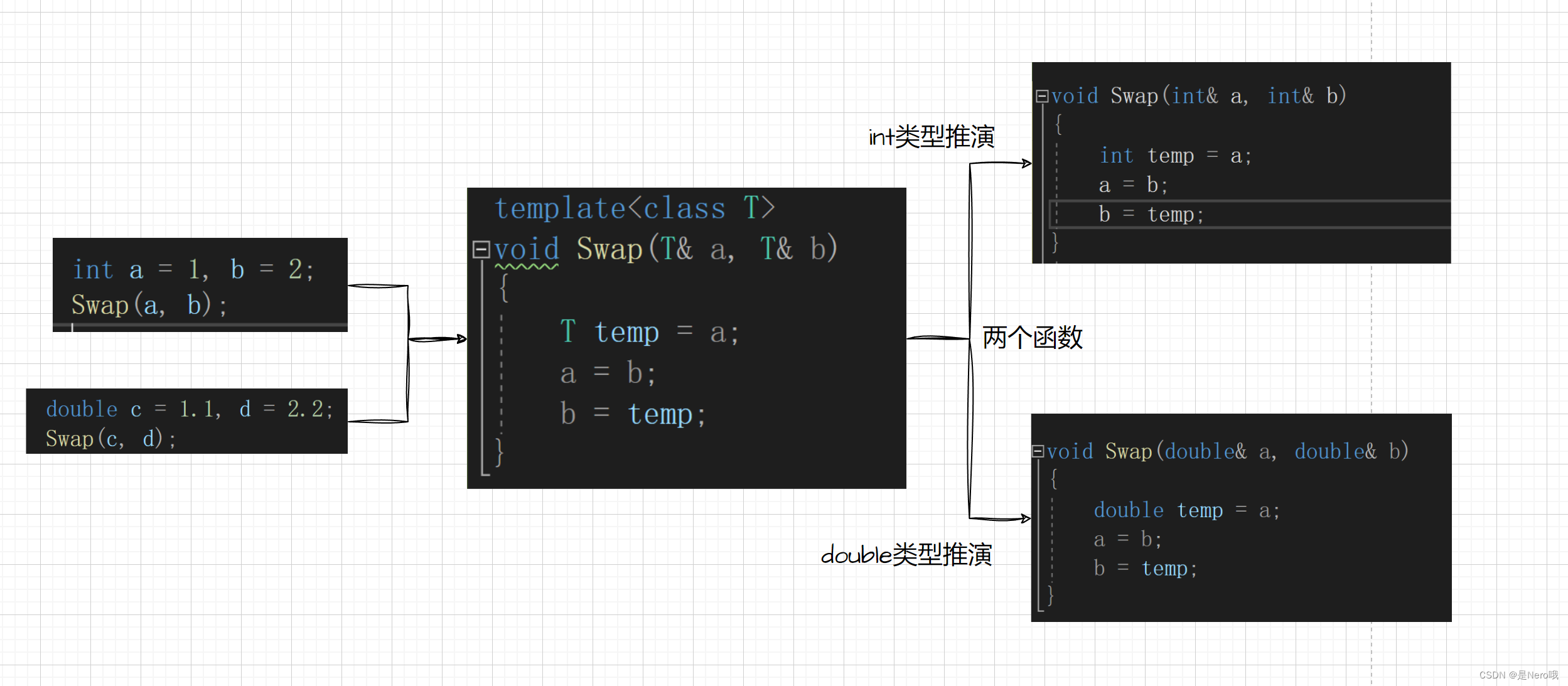
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用
int类型使用函数模板时,编译器通过对实参类型的推演,将T确定为int类型,然后产生一份专门处理int类型的代码,对于字符类型也是如此
2.4函数模版的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化。
2.4.1隐式实例化
隐式实例化:让编译器根据实参推演模板参数的实际类型
template<class T>
T add(T& a, T& b)
{return a + b;
}int main()
{int a = 1, b = 2;int ab = add(a, b);double c = 1.1, d = 2.2;double cd = add(c, d);//这样会怎样呢?add(a, c);return 0;
}
add(a, c);这样调用会怎么样呢 ?该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型 通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,编译器报错
此时有两种处理方式:
- 用户自己来强制转化
template<class T>
T add(const T& a,const T& b)
{return a + b;
}int main()
{int t1 = add(1, (int)2.2);//自己直接强制转换double t2 = add((double)1, 2.2);return 0;
}
- 使用显式实例化
2.4.2显示实例化
显式实例化:在函数名后的<>中指定模板参数的实际类型
1.解决类型推测不同问题
template<class T ,class Y>
void print(T& a, Y& b)
{cout << a << " " << b << endl;
}template<class T>
T add(const T& a,const T& b)
{return a + b;
}int main()
{int a1 = 1;double b1 = 1.1;int a = add<int>(a1, b1);//显示实例化double b = add<double>(a1, b1);print(a, b);return 0;
}
如果类型不匹配,编译器会尝试进行隐式类型转换,如果无法转换成功编译器将会报错
- 函数模版参数列表里没有通用类型
template<class T>
T* fun1(int n)
{return new T[n];
}int main()
{int* a = fun1<int>(10);//此时必须显示实例化,不然没有办法推测T是什么类型return 0;
}
2.5 模板参数的匹配原则
- 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
- 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
- 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
3.类模板
3.1概念
**类模板允许我们创建通用的类,以存储和操作多种数据类型。类模板使用
template关键字定义,并可以包含一个或多个类型参数 **
3.2格式
template<class T1, class T2, ..., class Tn>
class 类模板名
{// 类内成员定义
};
template<class T>
class Stack
{
public:Stack(int capacity = 3){cout << "调用了构造函数" << endl;_a = new T[capacity];_top = 0;_capacity = capacity;}~Stack(){cout << "~Stack()" << endl;delete _a;_a = nullptr;_top = -1;_capacity = 0;}
private:int* _a;int _top;int _capacity;
};int main()
{Stack<int> s1;Stack<double> s2;//之前我们都是使用typedef来改变,但是只能存在一个。现在不一样了return 0;
}
3.3类模板的实例化
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟
<>,然后将实例化的类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类
int main()
{// Stack是类名,Stack<int>和Stack<double>才是类型Stack<int> s1;Stack<double> s2;return 0;
}
好啦,这次的内容就到这里啦。接下来进入stl的学习啦!!感谢大家支持~!