网站建设十年经验星速浏览器
🌟组件化:把一个项目拆成一个一个的组件,为了便与开发与维护
组件之间互相独立且封闭,一般而言,每个组件只能使用自己的数据(组件状态私有)。
如果组件之间相互传参怎么办? 那么就要考虑组件之间的通讯。
props基本使用
props能够实现传递数据和接受数据。
作用:接收其他组件传递的数据
传递:给组件标签添加属性,就表示给组件传递数据
接收:分为函数组件和类组件
- 函数组件:通过参数
props - 类组件:通过
this.props
函数式组件使用props
// 函数组件通过props获取
function Hi(props) {return <div>{props.name}</div>
}...
...
const VNode = (<div><Hi name={'Tricia'}></Hi></div>
)
类组件使用this.props
// class 组件需要通过 this.props 来获取
class Hello extends Component {render() {return <div>接收到的数据:{this.props.age}</div>}
}
...
...
const VNode = (<div><Hello name="jack" age={19} /></div>
)

注意点:
- props只能读取对象中的属性,但是无法修改。
- 单向数据流: 数据从父组件流向子组件,即父组件的数据修改时,子组件也跟着修改
- 子组件的数据不能传递给父组件
- 🌟传递字符串时可以直接传递,传递其他数据类型时需要加
{}
组件通讯
父传子
将父组件的数据传递给子组件,数据是单向流,子组件中是只读的!
步骤:
- 父组件提供要传递的state数据
- 给子组件标签添加属性,值为state中的数据
- 子组件中通过props接收父组件传递过来的数据
- 父组件
// 定义一个父组件
class Father extends React.Component {// 父组件在state中提供数据state = {fName: '朗道',}render() {return (<><div><p>father</p>{/* 父组件数据通过子组件标签传递给子组件 */}<Son fName={this.state.fName}></Son></div></>)}
}
-
子组件中通过
this.props.属性名接收父组件中传递的数据import { Component } from 'react' class Son extends Component {render() {return (<>{/* 子组件通过this.props接收父组件传过来的数据并渲染 */}<p>Son : {this.props.fName}</p></>)} } export default Son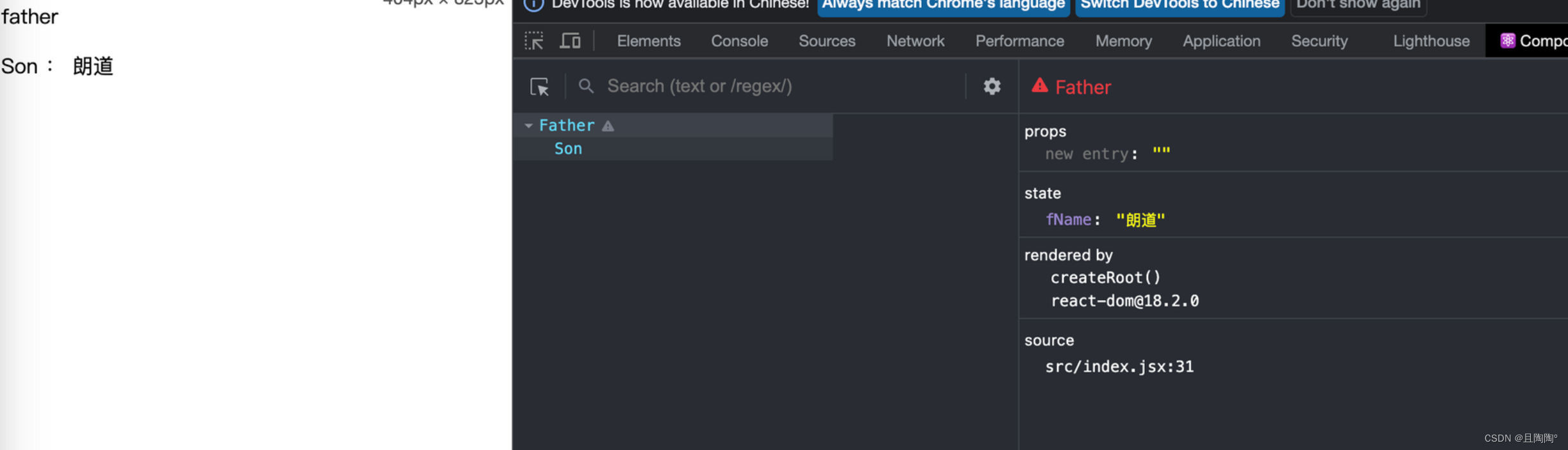
注意:
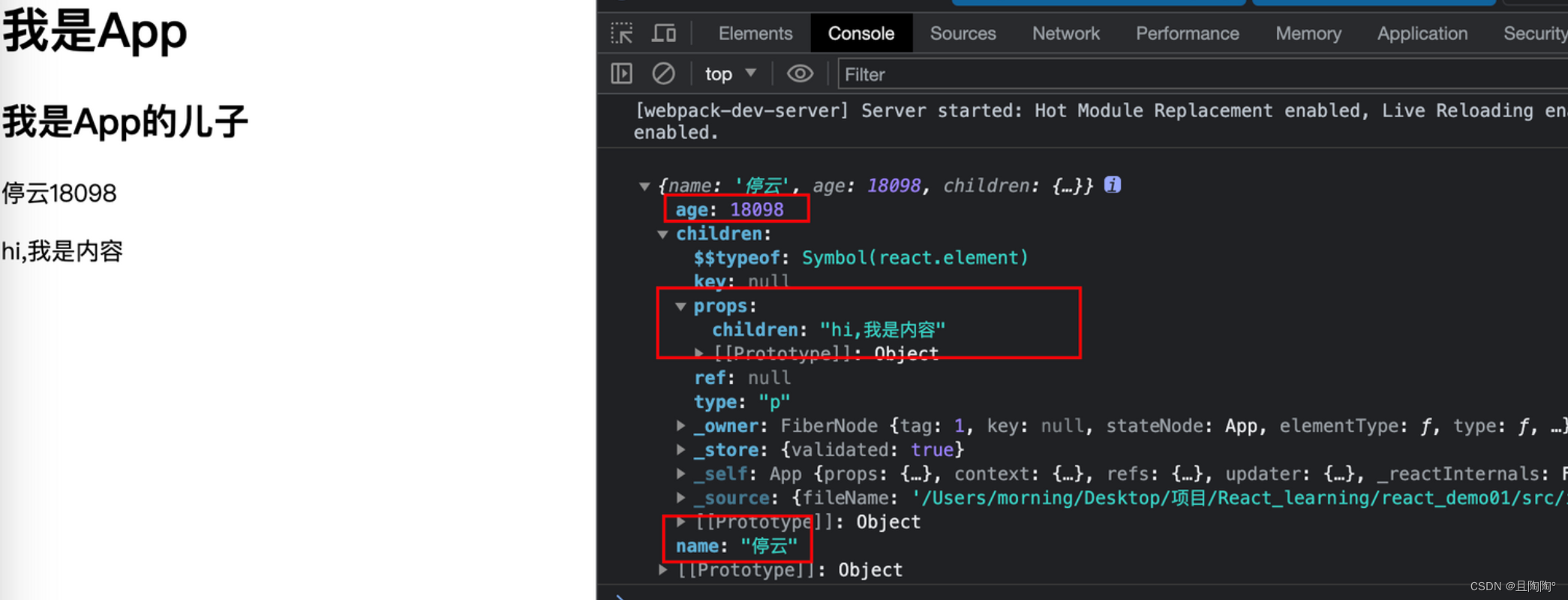
父传子也可以在内容里面传,用JSX。子组件接受时使用 this.props.children
import React, { Component } from 'react'
import ReactDom from 'react-dom'class AppSon extends Component {render() {console.log(this.props)return (<><h2>我是App的儿子</h2><div>{this.props.name}{this.props.age}{/* 用children来接受 */}{this.props.children}</div></>)}
}
class App extends Component {render() {return (<><h1>我是App</h1><AppSon name={'停云'} age={18098}>{/* 父传子也可以在此处传递 */}{<p>hi,我是内容</p>}</AppSon></>)}
}
ReactDom.createRoot(document.querySelector('#root')).render(<App></App>)
子传父
步骤
- 父组件提供一个回调函数,将该函数作为属性的值,传递给子组件。
- 子组件通过props调用回调函数
- 将子组件的数据作为参数传递给回调函数。
import React, { Component } from 'react'
import ReactDom from 'react-dom/client'// 子传父本质是父组件传递给子组件一个方法,子组件通过调这个方法来向父组件传参。
class AppSon extends Component {render() {return (<><h2>我是App的儿子</h2><span>{this.props.name}</span><button onClick={() => this.props.editName(this.props.name)}>点击执行父组件的方法</button></>)}
}
class App extends Component {state = {name: '冷面小青龙',}editName = (val) => {console.log(val)this.setState({name: val === '丹恒' ? '冷面小青龙' : '丹恒',})}render() {return (<><h1>我是App</h1><AppSon name={this.state.name} editName={this.editName}></AppSon></>)}
}
ReactDom.createRoot(document.querySelector('#root')).render(<App></App>)
注意
回调函数不能用普通函数,因为this指向的问题,如果是普通函数那么谁调用this就指向谁。这个函数是被this.props调用的,所以this指向的是父组件传递过去的参数
class App extends Component {state = {name: '冷面小青龙',}editName() {// 错误写法// 注意⚠️:这里不能用普通函数,因为this指向的问题,如果是普通函数那么谁调用this就指向谁。这个函数是被this.props调用的,所以this指向的是父组件传递过去的参数console.log(this)} render() {return (<><h1>我是App</h1><AppSon name={this.state.name} editName={this.editName}></AppSon></>)}
}
兄弟组件通讯(状态提升)
核心思想:状态提升
公共父组件职责:
- 提供共享状态
- 提供操作共享状态的方法
要互相通讯的两个子组件只需通过props接受或者操作状态。说白了就是。父传子 + 子传父
步骤:
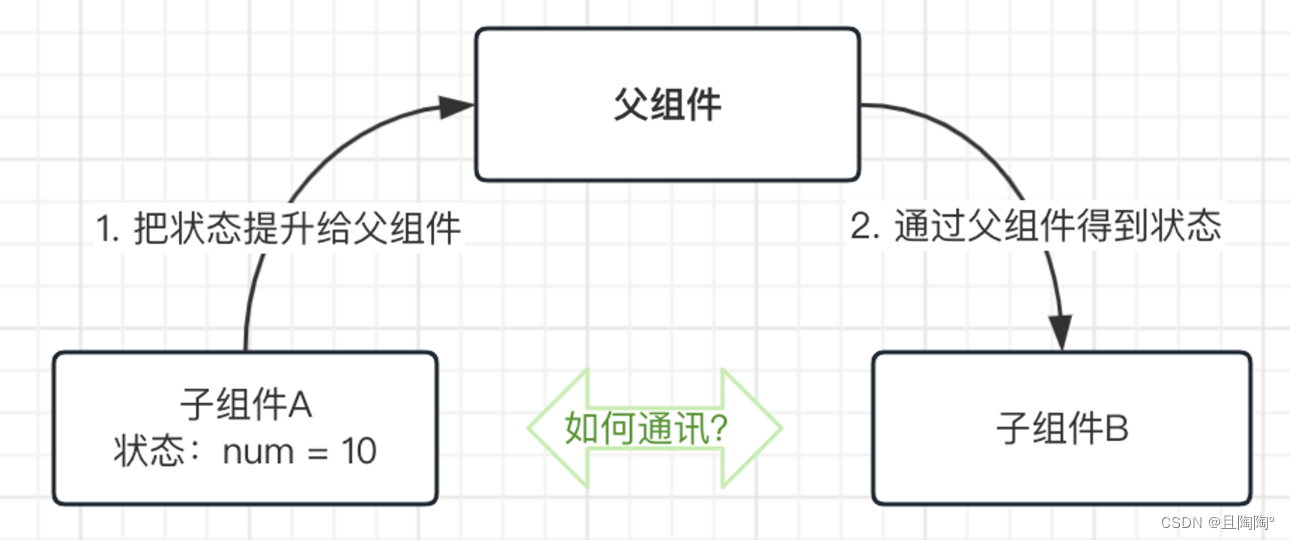
- Son1通过子传父,将自己要传递的state给公共父组件
- Son2通过父传子得到这个state
import React, { Component } from 'react'
import ReactDOM from 'react-dom/client'
import Son1 from './Son1'
import Son2 from './Son2'
export default class App extends Component {state = {num: '123',}editNum = (n) => {this.setState({num: +this.state.num + n,})}render() {return (<><div>App</div>{/* 通过子传父改变num值 */}<Son1 editNum={this.editNum}></Son1>{/* 父传子得到Son1的num 值 */}<Son2 num={this.state.num}></Son2></>)}
}
ReactDOM.createRoot(document.querySelector('#root')).render(<App></App>)
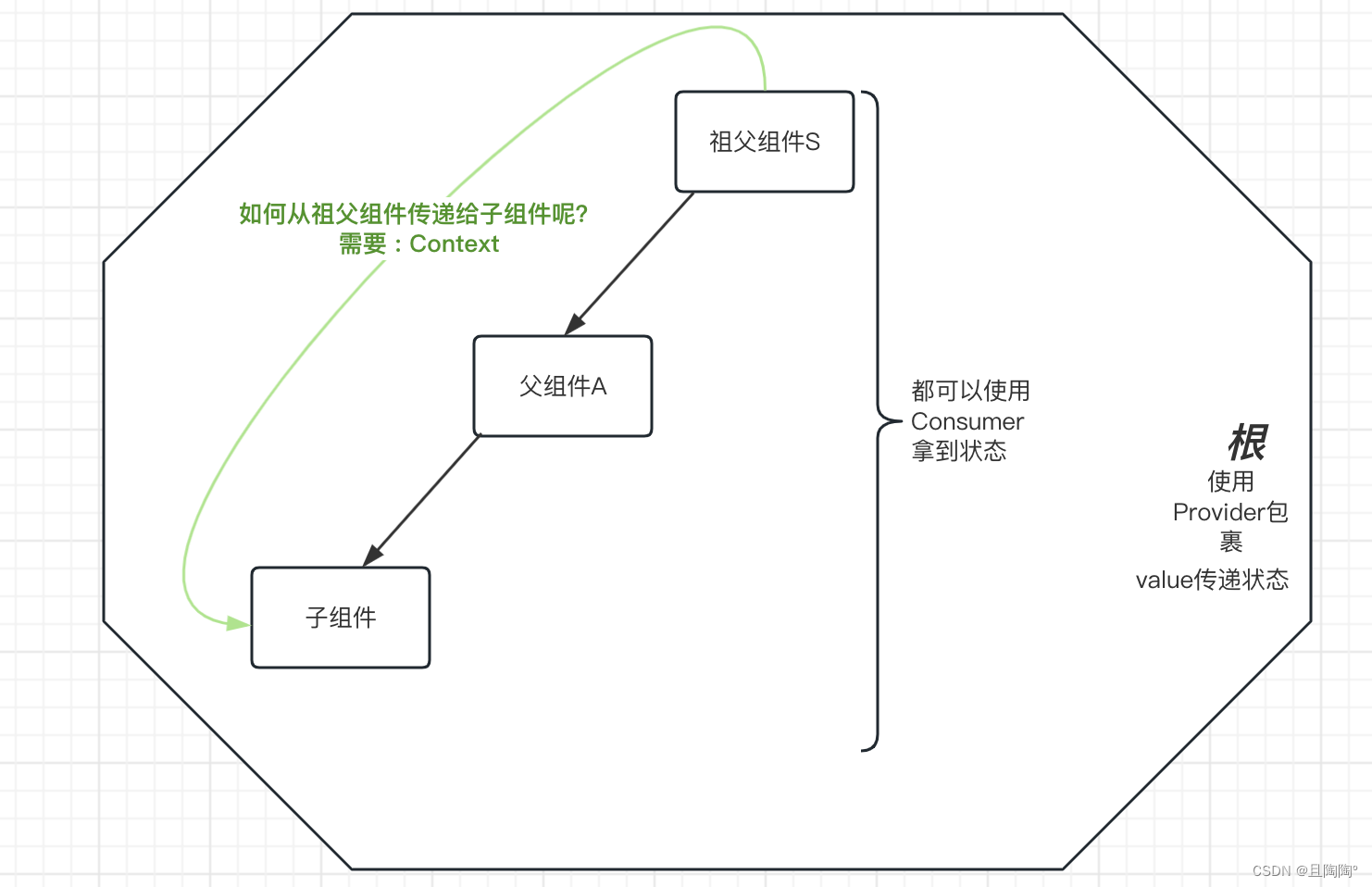
跨级组件通讯 - context
context: 上下文,可以理解为是一个范围,在这个范围内的所有组件都可以跨级通讯。
步骤
- 引入createContext方法,拿到Provider和Consumer
- 将createContext方法提出来,提供Provider, Consumer这两个组件并导出
- 使用Provider组件包裹整个应用,通过value属性提供要共享的数据。
- 通过Consumer组件接收共享的数据
-
context.jsx
// 公共组件:提供Provider, Consumer这两个组件// 1. 导入createcontext方法 import { createContext } from 'react' // 2. 调用方法得到两个组件 Provider, Consumer const Context = createContext() export default Context -
index.js
- 提供共享的数据和方法
- 如果要修改状态,也是将方法写在value中,最后由需要组件去调用。
import React, { Component } from 'react' import ReactDOM from 'react-dom/client' import GrandPa from './GrandPa'import Context from './Context/context' const { Provider } = Contextexport default class App extends Component {state = {num: '云浮将军景元元',age: 109776,}render() {return (// 使用Provider组件包裹根组件,并要提供value// 若要提供多个属性,可以写成对象格式<Provider value={{ name: this.state.num, age: this.state.age }}><div><h1>App</h1><GrandPa></GrandPa></div></Provider>)} }ReactDOM.createRoot(document.querySelector('#root')).render(<App></App>) -
在任意一个组件中均可使用共享的数据,例如Father.jsx
import React, { Component } from 'react' import Son from './Son' import Context from './Context/context' const { Consumer } = Context export default class Father extends Component {render() {return (<Consumer>{/* 接收state 需要将DOM放入插值中,并用箭头函数返回 */}{(obj) => (<div style={{ border: '2px solid #333', margin: '10px' }}>Father -- {obj.name}<Son></Son></div>)}</Consumer>)} } -
在Son.jsx组件中去修改状态
import React, { Component } from 'react'
import Context from './Context/context'
const { Consumer } = Context
export default class Son extends Component {render() {return (<Consumer>{(obj) => (<div style={{ border: '2px solid #333', margin: '10px' }}>Son -- {obj.age}岁<button onClick={() => obj.editAge(5)}>增加➕</button></div>)}</Consumer>)}
}
