网站都是哪里找的百度霸屏推广一般多少钱
今天碰到要判断两个UI是否相交的交互。
尝试了下,发现有两个方法都成功了。
1、使用Collider2D组件
分别创建两个Image组件,并且添加Collider2D组件,其中一个还要添加Rigidbody2D组件,如下图:
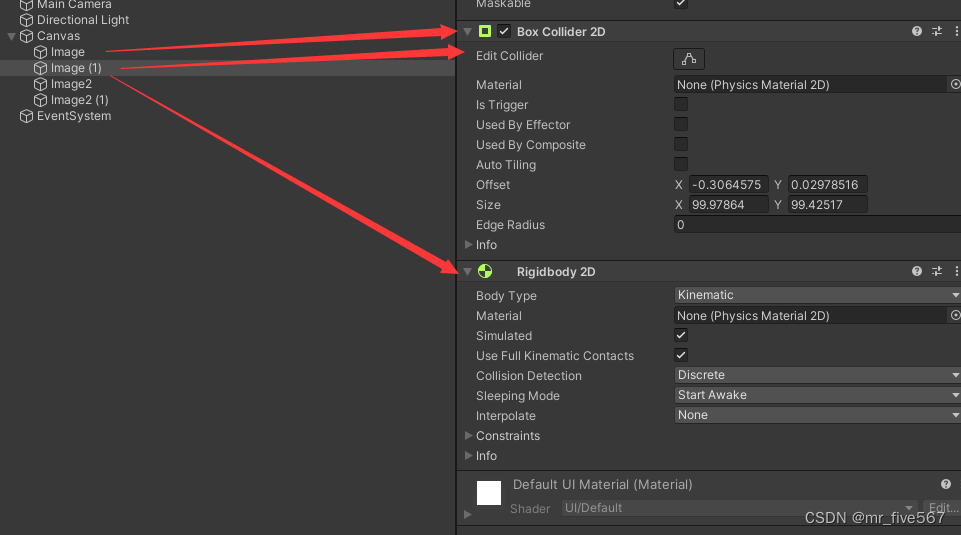
然后创建个判断脚本“UIintersect.cs",具体脚本代码如下,把脚本拉到场景中,当物体碰到一起是就能检测到它们是否相交了。
public Image image1;public Image image2;private Collider2D collider1;private Collider2D collider2;// Start is called before the first frame updatevoid Start(){// 获取image1和image2的Collider组件collider1 = image1.GetComponent<Collider2D>();collider2 = image2.GetComponent<Collider2D>();}// Update is called once per framevoid Update(){// 检测两个Collider是否相交if (collider1.IsTouching(collider2)){Debug.Log("UI相交了!");}else{Debug.Log("UI没有相交!");}}2、使用RectTransform组件和边界框。
本方法只需要脚本获取UI的RectTransform,然后判断它们的边界是否相交即可。
代码如下:
public RectTransform uiElement1;public RectTransform uiElement2;// Start is called before the first frame updatevoid Start(){}// Update is called once per framevoid Update(){if (CheckCollision(uiElement1, uiElement2)){Debug.Log("UI相交了!");}else{Debug.Log("UI没有相交!");}}private bool CheckCollision(RectTransform rectTransform1, RectTransform rectTransform2){Rect rect1 = rectTransform1.rect;Rect rect2 = rectTransform2.rect;Rect worldRect1 = GetWorldRect(rectTransform1);Rect worldRect2 = GetWorldRect(rectTransform2);return worldRect1.Overlaps(worldRect2);}private Rect GetWorldRect(RectTransform rectTransform){Vector3[] corners = new Vector3[4];rectTransform.GetWorldCorners(corners);Vector3 bottomLeft = corners[0];Vector3 topRight = corners[2];return new Rect(bottomLeft.x, bottomLeft.y, topRight.x - bottomLeft.x, topRight.y - bottomLeft.y);}把代码拉到场景中,也能判断UI是否相交。
总的感觉两种方法都不错。
效果:Unity判断两个UI是否相交_哔哩哔哩_bilibili