佛山外贸网站建设平台中国企业500强排行榜
目录
编辑编辑编辑
一、快速入门程序
①准备工作
②引入Mybatis相关依赖,配置Mybatis
③编写SQL(注解/XML)
④单元测试
⑤相关代码
1.pom.xml
2. application.properties
3.User.java
4. UserMapper.java
5.Test.java
⑥配置SQL提示
二、JDBC
①JDBC介绍
②JCBD与MyBatis
三、数据库连接池
①数据库连接池
②数据库连接池的作用
③常见数据库连接池
④切换数据库连接池
⑤总结
四、Lombok
①问题引入
②总结


一、快速入门程序
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
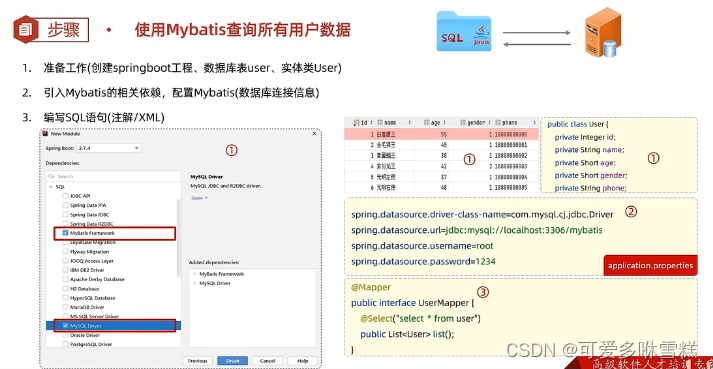
①准备工作
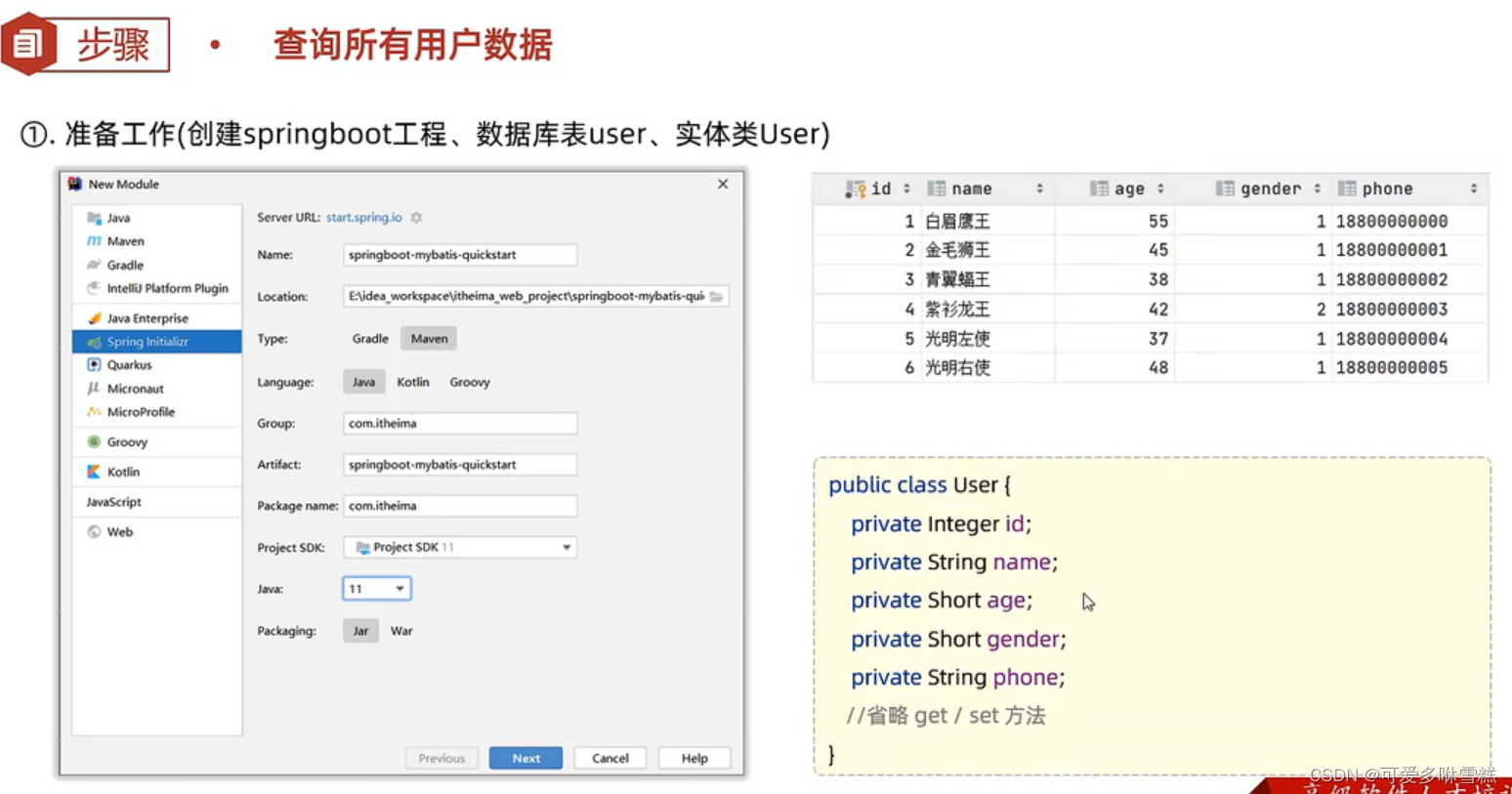
②引入Mybatis相关依赖,配置Mybatis

③编写SQL(注解/XML)

④单元测试

⑤相关代码
1.pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion>
<!-- 父工程--><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.17</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.itheima</groupId><artifactId>springboot-mybatis-quickstart01</artifactId><version>0.0.1-SNAPSHOT</version><name>springboot-mybatis-quickstart01</name><description>springboot-mybatis-quickstart01</description><properties><java.version>11</java.version></properties><dependencies>
<!-- mybatis的起步依赖--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version></dependency>
<!--mysql驱动包--><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency>
<!--springboot单元测试依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter-test</artifactId><version>2.3.1</version><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
2. application.properties
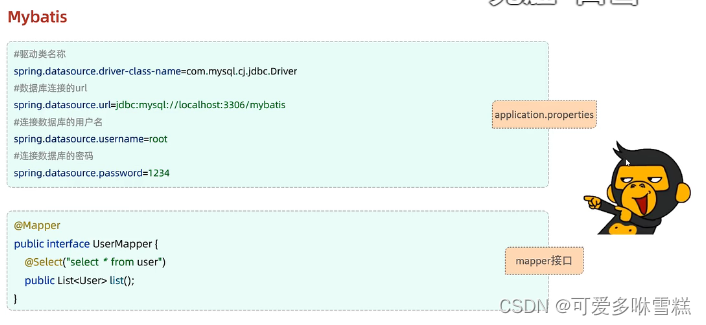
#配置数据库的连接信息#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库链接的url
spring.datasource.url=jdbc:mysql://localhost:3306/wms
#链接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=1234563.User.java
package com.itheima.pojo;public class User {private Integer id;private String name;private Short age;private Short gender;@Overridepublic String toString() {return "User{" +"id=" + id +", name='" + name + '\'' +", age=" + age +", gender=" + gender +", phone='" + phone + '\'' +'}';}public User() {}public User(Integer id, String name, Short age, Short gender, String phone) {this.id = id;this.name = name;this.age = age;this.gender = gender;this.phone = phone;}public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Short getAge() {return age;}public void setAge(Short age) {this.age = age;}public Short getGender() {return gender;}public void setGender(Short gender) {this.gender = gender;}public String getPhone() {return phone;}public void setPhone(String phone) {this.phone = phone;}private String phone;}4. UserMapper.java
package com.itheima.mapper;import com.itheima.pojo.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;import java.util.List;@Mapper//当前是mybatis中的Mapper接口,程序运行时框架会自动生成该接口的实现类对象(代理对象),并且将该对象交给Spring的IOC容器管理
public interface UserMapper {//查询全部用户信息@Select("select * from user")public List<User> list();
}
Mapper层相当于三层架构中的Dao层(持久层),在mybatis中只需要定义Mapper接口,并加上注解@Mapper,程序运行的时候框架就会自动生成该接口的实现类对象(代理对象),并将该对象交由Spring的IOC容器管理
在UserMapper的接口方法list上加了@Select注解,在value中定义了SQL语句,
5.Test.java
package com.itheima;import com.itheima.mapper.UserMapper;
import com.itheima.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.List;@SpringBootTest//Springboot整合单元测试
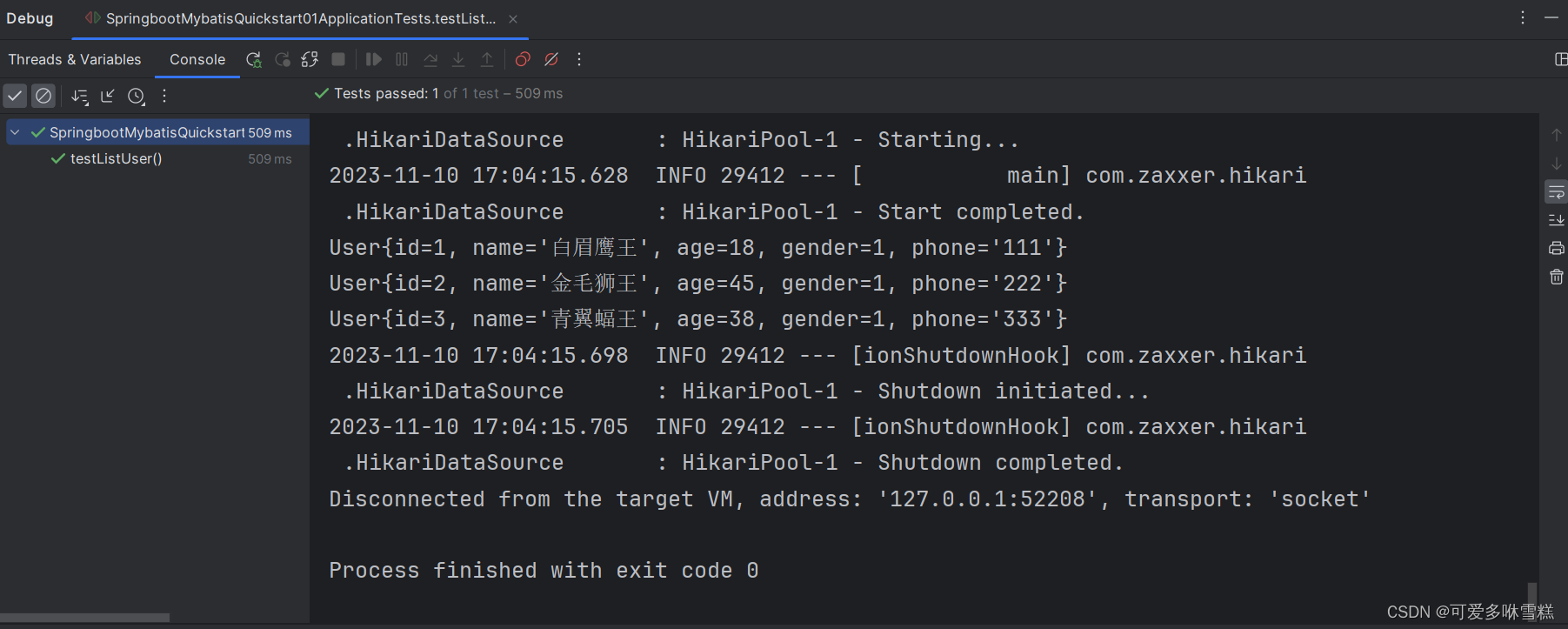
class SpringbootMybatisQuickstart01ApplicationTests {@Autowiredprivate UserMapper userMapper;@Testpublic void testListUser(){List<User> userList=userMapper.list();userList.stream().forEach(user -> System.out.println(user));}}
定义一个UserMapper接口对象userMapper,并加上@Autowired注解,就会自动注入mybatis自动生成的实现类对象。
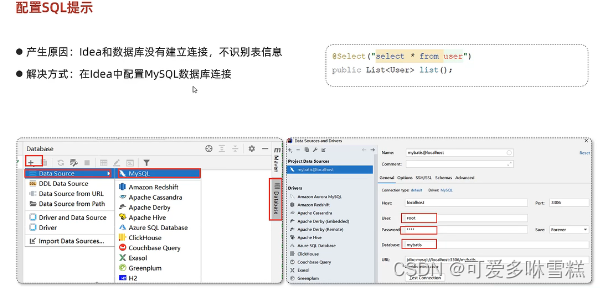
⑥配置SQL提示

二、JDBC
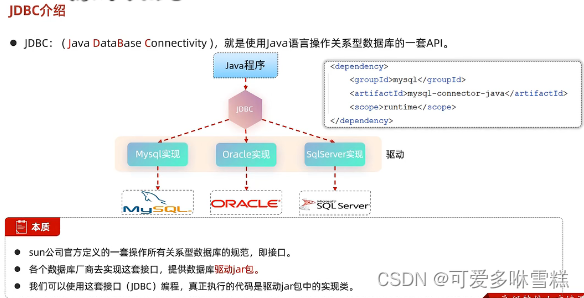
①JDBC介绍
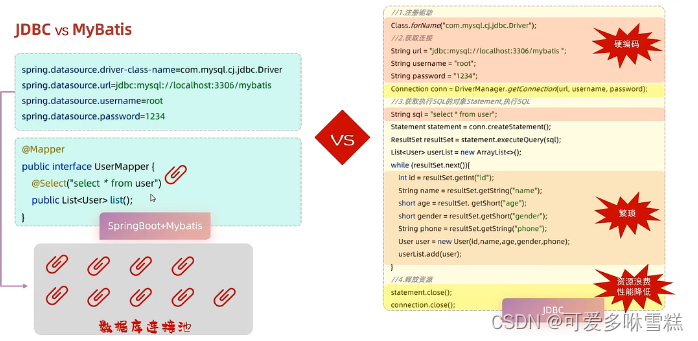
②JCBD与MyBatis
三、数据库连接池
①数据库连接池
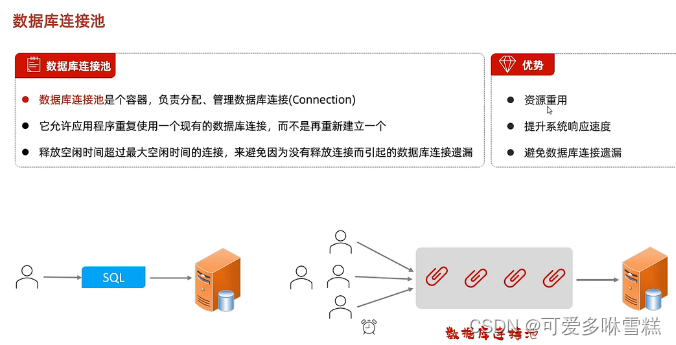
②数据库连接池的作用
如果没有数据库连接池,客户端要执行SQL语句,首先创建新连接对象在执行SQL语句,然后把链接对象关闭释放资源
如果有了数据库连接池,程序在启动的时候就会在容器中初始化一定数量的连接对象,数据库要执行SQL语句,会从连接池中获取一个链接,执行这条SQL语句,执行完毕再归还连接池,做到连接池的复用,而不用每次使用完就释放。
各个客户端在执行SQL语句的时候,会从连接池中获取相关链接,执行完SQL语句就会将连接归还给连接池,如果有个别客户端获取到链接后一直处于空闲状态,此时数据库连接池就会监测链接空闲时间,如果超过了数据库的连接池预设的最大时间,该链接会释放归还给链接,预防连接池没有及时释放二造成数据库连接池中的链接越来越少,从而导致下一个客户端无连接池可用。
③常见数据库连接池

④切换数据库连接池
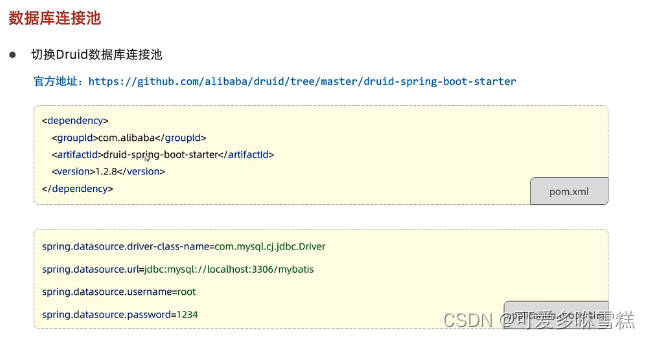
⑤总结

四、Lombok
①问题引入

不用自己写get/set/construct方法,直接在类上加@Data注解即可
②总结

原理:在编译时期根据注解决定为该类提供对应的方法
不需要指定版本号,因为在Springboot中已经集成lombok