网站制作合作协议河南省城乡与住房建设厅网站
目录
前言
注解式 WebSocket 构建聊天系统
群聊系统(基本框架)
群聊系统(添加昵称)
单聊系统
WebSocket 作用域下无法注入 Spring Bean 对象?
考虑离线消息
前言
很久之前,咱们聊过 WebSocket 编程式的写法,但是有些过于繁琐,这次来看看更接近现代的注解式,构建 群聊、单聊 有多么便利.
注解式 WebSocket 构建聊天系统
群聊系统(基本框架)
a)定义 WebSocket 配置类.
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
import org.springframework.web.socket.server.standard.ServerEndpointExporter/*** 注入对象 ServerEndpointExporter* 这个 bean 会自动注册使用了 @ServerEndpoint 注解声明的 WebSocket endpoint*/@Configuration
class WebSocketConfig {@Beanfun serverEndpointExporter() = ServerEndpointExporter()}
b)WebSocket 实现类
import org.springframework.stereotype.Component
import java.util.concurrent.CopyOnWriteArraySet
import javax.websocket.OnClose
import javax.websocket.OnError
import javax.websocket.OnMessage
import javax.websocket.OnOpen
import javax.websocket.Session
import javax.websocket.server.ServerEndpoint/*** 虽然此处 @Component 默认是单例的,但是 SpringBoot 还是会为每个 WebSocket 初始化一个 bean,* 因此可以使用一个静态的 Set 保存起来(CopyOnWriteArraySet 相比于 HashSet 是线程安全的)*/
@ServerEndpoint(value = "/websocket")
@Component
class MyWebSocket {companion object {//用来存放每个客户端对应的 MyWebSocket 对象private val webSocketSet = CopyOnWriteArraySet<MyWebSocket>()}//与某个客户都安连接的会话,需要通过他来给客户都安发送数据private lateinit var session: Session/*** 连接成功调用的方法*/@OnOpenfun onOpen(session: Session) {//获取当前连接客户端 sessionthis.session = session//加入到 set 中webSocketSet.add(this)println("当前在线人数为: ${webSocketSet.size}")this.session.asyncRemote.sendText("恭喜您成功连接上 WebSocket,当前在线人数为: ${webSocketSet.size}")}/*** 收到客户端消息时调用的方法*/@OnMessagefun onMessage(message: String, session: Session) {println("收到客户端的消息: $message")//群发消息allSend(message)}@OnErrorfun onError(session: Session, error: Throwable) {println("连接异常")error.printStackTrace()}@OnClosefun onClose() {webSocketSet.remove(this)println("有人下线!当前在线人数: ${webSocketSet.size}")}/*** 自定义群发消息* basicRemote: 阻塞式* asyncRemote: 非阻塞式* 大部分情况下更推荐使用 asyncRemote, 详情: https://blog.csdn.net/who_is_xiaoming/article/details/53287691*/private fun allSend(message: String) {webSocketSet.forEach {//it.session.basicRemote.sendText(message)it.session.asyncRemote.sendText(message)}}}
c)客户端开发
<!DOCTYPE HTML>
<html><head><meta charset="UTF-8"><title>My WebSocket</title><style>#message {margin-top: 40px;border: 1px solid gray;padding: 20px;}</style>
</head><body><button onclick="conectWebSocket()">连接WebSocket</button><button onclick="closeWebSocket()">断开连接</button><hr /><br />消息:<input id="text" type="text" /><button onclick="send()">发送消息</button><div id="message"></div>
</body>
<script type="text/javascript">var websocket = null;function conectWebSocket() {//判断当前浏览器是否支持WebSocketif ('WebSocket' in window) {websocket = new WebSocket("ws://localhost:9000/websocket");} else {alert('Not support websocket')}//连接发生错误的回调方法websocket.onerror = function () {setMessageInnerHTML("error");};//连接成功建立的回调方法websocket.onopen = function (event) {setMessageInnerHTML("tips: 连接成功!");}//接收到消息的回调方法websocket.onmessage = function (event) {setMessageInnerHTML(event.data);}//连接关闭的回调方法websocket.onclose = function () {setMessageInnerHTML("tips: 关闭连接");}//监听窗口关闭事件,当窗口关闭时,主动去关闭websocket连接,防止连接还没断开就关闭窗口,server端会抛异常。window.onbeforeunload = function () {websocket.close();}}//将消息显示在网页上function setMessageInnerHTML(innerHTML) {document.getElementById('message').innerHTML += innerHTML + '<br/>';}//关闭连接function closeWebSocket() {websocket.close();}//发送消息function send() {var message = document.getElementById('text').value;websocket.send(message);}</script></html>d)效果如下:
打开两个浏览器,依次点击建立连接
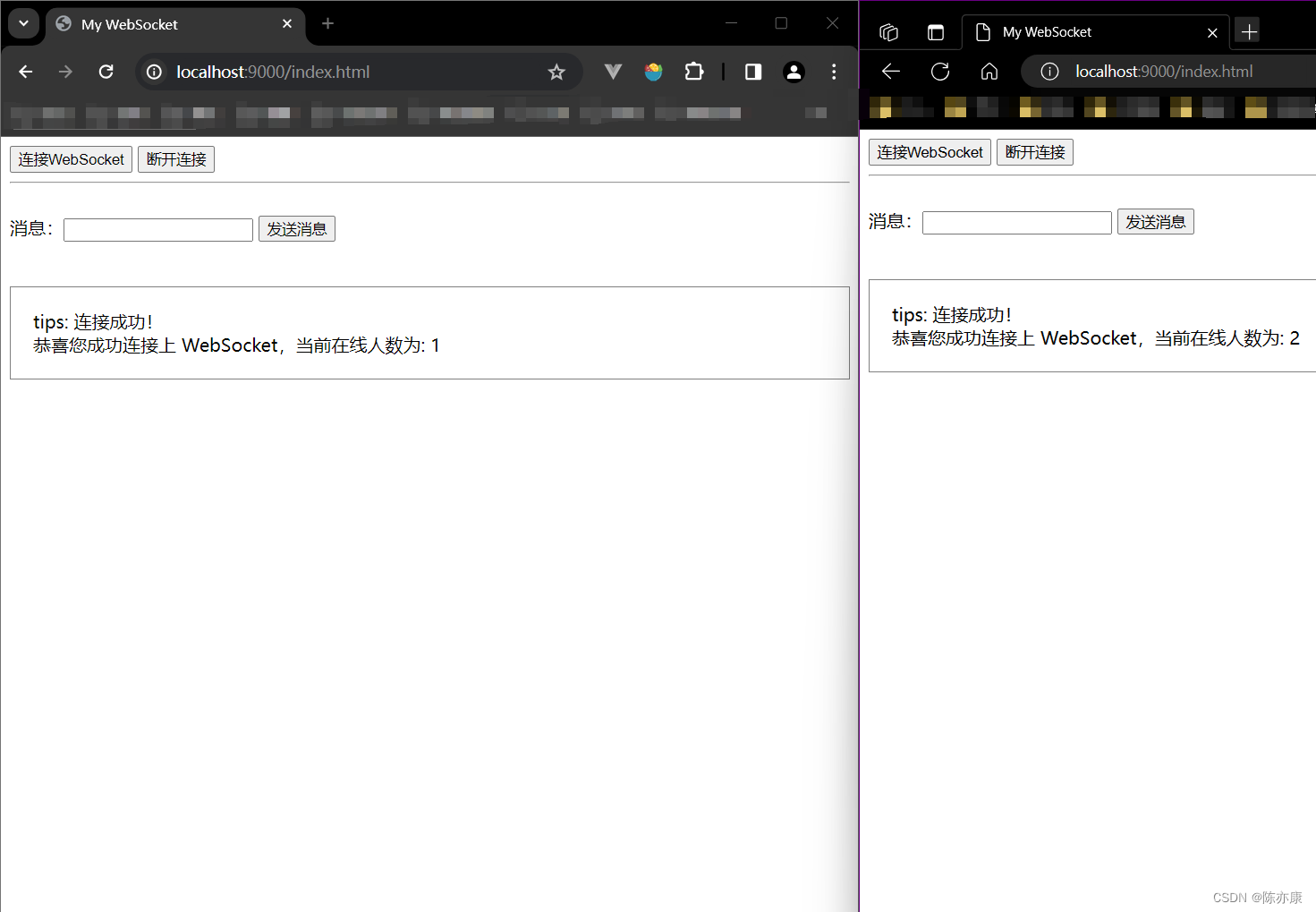
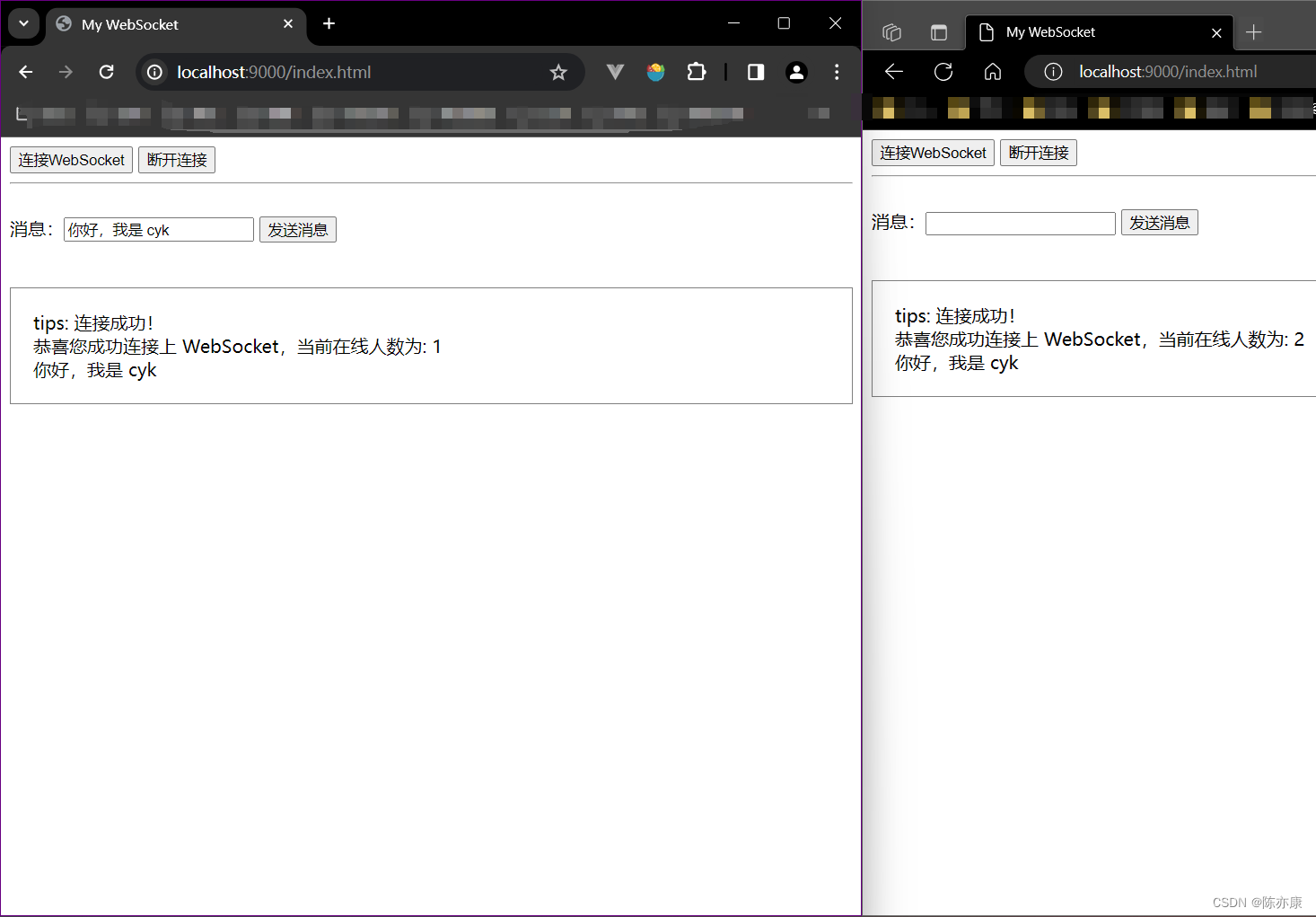
左边的浏览器中输入:"你好,我是 cyk",效果如下
群聊系统(添加昵称)
上述聊天系统中可以看到,并不知道当前消息是哪一个用户发出的,因此这里我们改造一下,让每个消息前携带用户名.
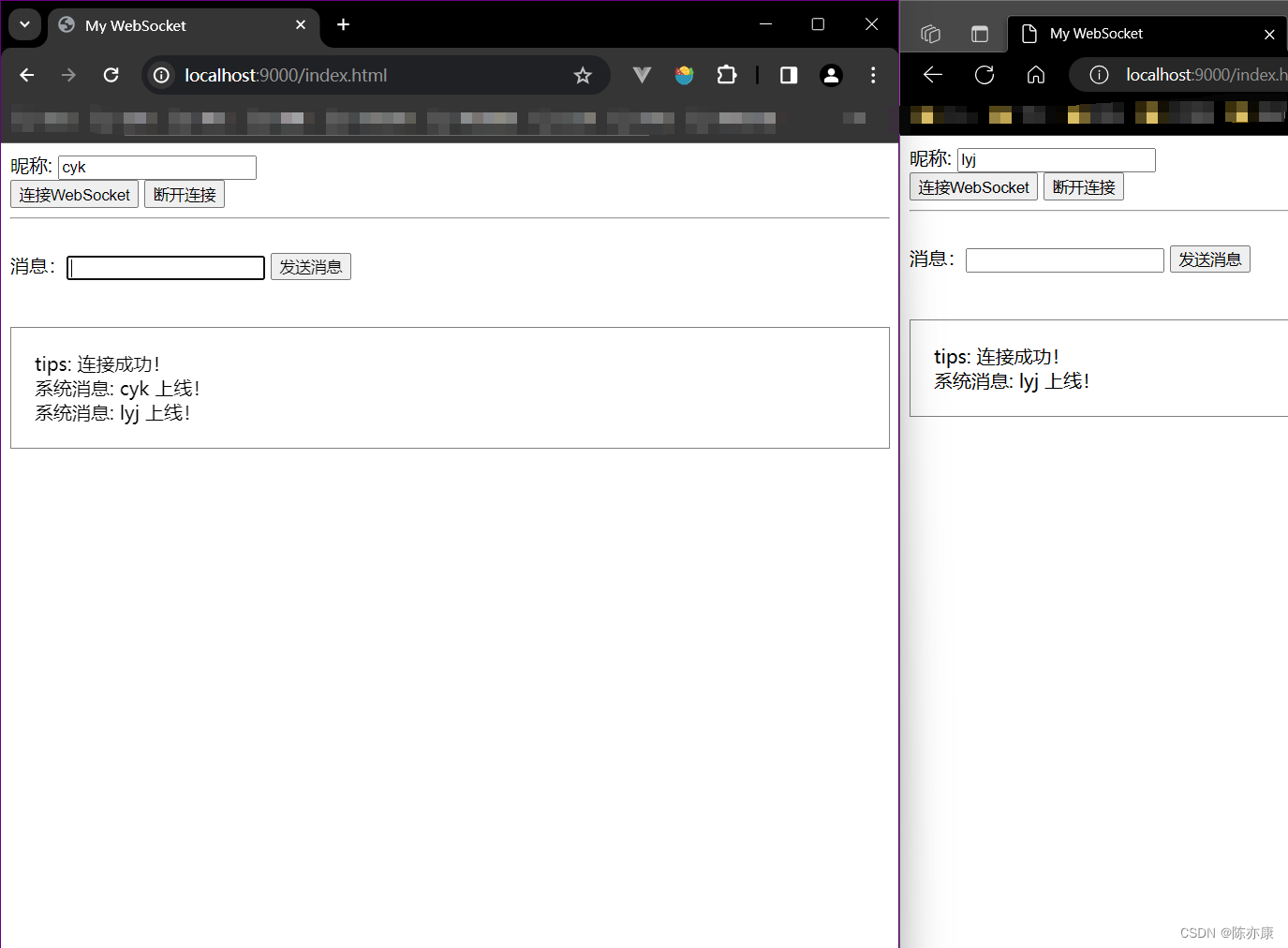
a)客户端改造:在用户点击 "连接 WebSocket" 之前输入昵称,以此作为消息的身份标识.

b)服务端改造:

之后在 WebSocket 注解标记的每一个方法中,都可以通过 @PathParam("nickname") nickname: String 获取到 nickname.
尽管如此,再上图中我还是使用成员变量 nickname 在 WebSocket 第一次建立连接的时候通过 @onOpen 标记的方法进行保存. 如下:
/*** 连接成功调用的方法*/@OnOpenfun onOpen(session: Session,@PathParam("nickname") nickname: String) {//获取当前连接客户端 sessionthis.session = sessionthis.nickname = nickname//加入到 set 中webSocketSet.add(this)println("$nickname 上线,当前在线人数为: ${webSocketSet.size}")allSend("系统消息: $nickname 上线!")}
发送的消息携带上昵称
@OnMessagefun onMessage(message: String, session: Session) {println("收到客户端的消息: $message")//群发消息allSend("$nickname: $message")}
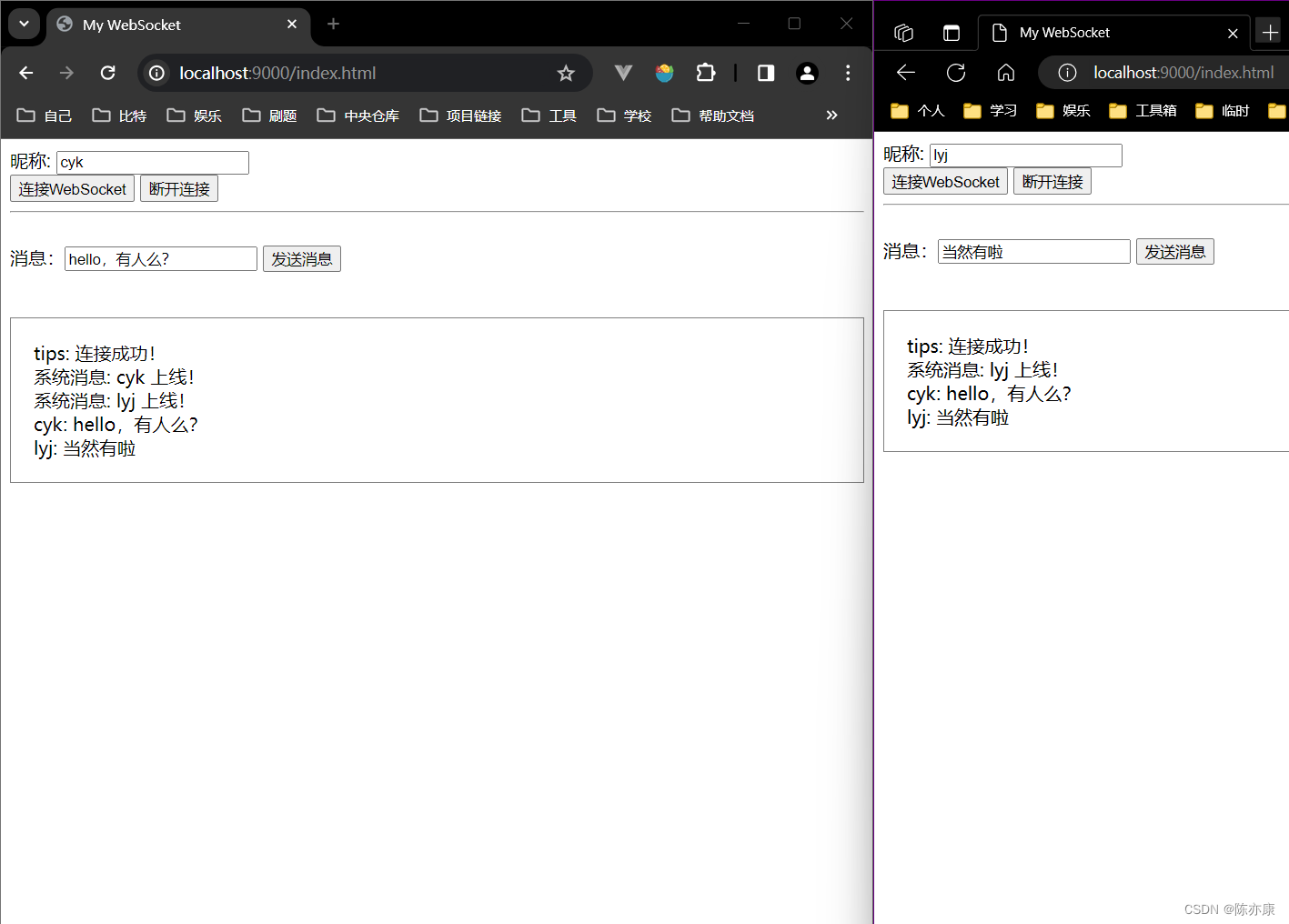
c)效果如下:
单聊系统
a)服务器开发:需要通过一个 map 来记录用户的 session 信息(key:用户唯一标识,value: session)
ChatMsg:用来接收客户端传入的 JSON 消息(通过 ObjectMapper 反序列化).
onOpen:记录用户信息到 map 中.
opMessage:将消息转发给目标人物.
import com.fasterxml.jackson.databind.ObjectMapper
import org.springframework.stereotype.Component
import java.util.concurrent.ConcurrentHashMap
import javax.websocket.OnClose
import javax.websocket.OnError
import javax.websocket.OnMessage
import javax.websocket.OnOpen
import javax.websocket.Session
import javax.websocket.server.PathParam
import javax.websocket.server.ServerEndpointdata class ChatMsg (val targetName: String = "", //目标val msg: String = "", //消息
)/*** 虽然此处 @Component 默认是单例的,但是 SpringBoot 还是会为每个 WebSocket 初始化一个 bean,* 因此可以使用一个静态的 Set 保存起来(CopyOnWriteArraySet 相比于 HashSet 是线程安全的)*/
@ServerEndpoint(value = "/websocket/{nickname}")
@Component
class MyWebSocket {companion object {//用来存放每个客户端对应的 MyWebSocket 对象private val webSocketMap = ConcurrentHashMap<String, Session>()}//与某个客户都安连接的会话,需要通过他来给客户都安发送数据private lateinit var session: Session //用来记录当前连接者会话private lateinit var nickname: String/*** 连接成功调用的方法*/@OnOpenfun onOpen(session: Session,@PathParam("nickname") nickname: String) {//获取当前连接客户端 sessionthis.session = sessionthis.nickname = nickname//加入到 set 中webSocketMap[nickname] = sessionprintln("$nickname 上线,当前在线人数为: ${webSocketMap.size}")allSend("系统消息: $nickname 上线!")}/*** 收到客户端消息时调用的方法*/@OnMessagefun onMessage(messageJson: String, session: Session) {println("收到客户端的消息: $messageJson")//单独发送消息val mapper = ObjectMapper()val message = mapper.readValue(messageJson, ChatMsg::class.java)val targetSession = webSocketMap[message.targetName]val postSession = this.sessionif(targetSession == null) {postSession.asyncRemote.sendText("当前用户不存在或者不在线!")} else {postSession.asyncRemote.sendText("${nickname}: ${message.msg}") //发送者获取自己的消息targetSession.asyncRemote.sendText("${nickname}: ${message.msg}") //接收者获取发送者的消息}}@OnErrorfun onError(session: Session, error: Throwable) {println("连接异常")error.printStackTrace()}@OnClosefun onClose() {webSocketMap.remove(nickname)println("${nickname} 下线!当前在线人数: ${webSocketMap.size}")allSend("系统消息: $nickname 下线!")}/*** 自定义群发消息* basicRemote: 阻塞式* asyncRemote: 非阻塞式* 大部分情况下更推荐使用 asyncRemote, 详情: https://blog.csdn.net/who_is_xiaoming/article/details/53287691*/private fun allSend(message: String) {webSocketMap.forEach {it.value.asyncRemote.sendText(message)}}}
b)客户端开发
<!DOCTYPE HTML>
<html><head><meta charset="UTF-8"><title>My WebSocket</title><style>#message {margin-top: 40px;border: 1px solid gray;padding: 20px;}</style>
</head><body><div><span>昵称: </span><input type="text" id="nickname"></div><button onclick="conectWebSocket()">连接WebSocket</button><button onclick="closeWebSocket()">断开连接</button><hr /><br /><div><span>targetName: </span><input type="text" id="targetName"></div><div><span>消息: </span><input id="text" type="text" /></div><button onclick="send()">发送消息</button><div id="message"></div>
</body>
<script type="text/javascript">var websocket = null;function conectWebSocket() {//判断当前浏览器是否支持WebSocketif ('WebSocket' in window) {let nickname = document.getElementById("nickname").valueif (nickname == null || nickname == "") {alert("请先输入昵称!")return}websocket = new WebSocket("ws://localhost:9000/websocket/" + nickname);} else {alert('Not support websocket')}//连接发生错误的回调方法websocket.onerror = function () {setMessageInnerHTML("error");};//连接成功建立的回调方法websocket.onopen = function (event) {setMessageInnerHTML("tips: 连接成功!");}//接收到消息的回调方法websocket.onmessage = function (event) {setMessageInnerHTML(event.data);}//连接关闭的回调方法websocket.onclose = function () {setMessageInnerHTML("tips: 关闭连接");}//监听窗口关闭事件,当窗口关闭时,主动去关闭websocket连接,防止连接还没断开就关闭窗口,server端会抛异常。window.onbeforeunload = function () {websocket.close();}}//将消息显示在网页上function setMessageInnerHTML(innerHTML) {document.getElementById('message').innerHTML += innerHTML + '<br/>';}//关闭连接function closeWebSocket() {websocket.close();}//发送消息function send() {var message = document.getElementById('text').value;var targetName = document.getElementById('targetName').value;var chatMsg = {"targetName": targetName,"msg": message}websocket.send(JSON.stringify(chatMsg));}</script></html>
WebSocket 作用域下无法注入 Spring Bean 对象?
这是因为 Spring 管理 Bean 对象默认都是单例的,而 WebSocket 却是多例的,因此注入 Spring 中的 Bean 对象会冲突.
解决办法:通过 set 方法注入一个静态的 Bean 即可.
@ServerEndpoint("/websocket/{id}")
@Component
class ChatRoom {companion object {private lateinit var userInfoRepo: UserInfoRepo}@Resourcefun setUserInfoRepo(userInfoRepo: UserInfoRepo) {Companion.userInfoRepo = userInfoRepo}}
考虑离线消息
只需要再添加一个 ConcurrentHashMap 来记录用户和离线消息~
考虑到消息可能过大,放在内存中不太合适,也可以通过专门设计一个张数据库表来存放用户的离线消息.
当用户再次上线,触发 onOpen 方法时,就可以恢复离线消息啦~
Ps:想要源码可以联系我......
