做公司网站哪里好wordpress 分类不显示
文章目录
- 需求
- Clion连接服务器内的Docker
- Docker
- CLion
- Docker内配置HElib库
- 参考
需求
- HElib库是用C++编写的同态加密开源库,一般在Linux下使用
- 为了不混淆生产环境,使用Docker搭建HElib运行环境
- 本地在Windows下开发,使用的IDE为Clion,本地无HElib运行环境
- 综上,需求是,让CLion连接搭建好HElib的Docker上,在本地CLion中编写代码,在远程服务器的Docker里运行代码
Clion连接服务器内的Docker
Docker
- Docker安装略
- Docker创建容器
命令解释:–name指定容器名字;-p指定端口,用于服务器端口映射到Docker内端口,由于后续需要通过ssh连接Docker容器,故映射到22端口;使用的镜像为ubuntu:20.04,镜像随意;bash指定运行终端sudo docker run -it --name helib -p 12022:22 ubuntu:20.04 bash
PS. 可以加个-v参数指定挂载目录 - 进入Docker后,先退出然后再重启进入(想让容器一直运行不关闭我就这么干的)
在容器内:exit # 退出后容器也会退出 sudo docker start helib # 启动容器 sudo docker exec -it helib bash # 进入容器,之后再退出容器也不会退出了 - 安装ssh等服务
apt update apt install openssl openssh-server -y echo "PermitRootLogin yes" >> /etc/ssh/sshd_config service ssh restart passwd root # 设置Docker容器的root密码,用于后续连接 - 测试连接
- 在Docker外,用ssh测试连接:
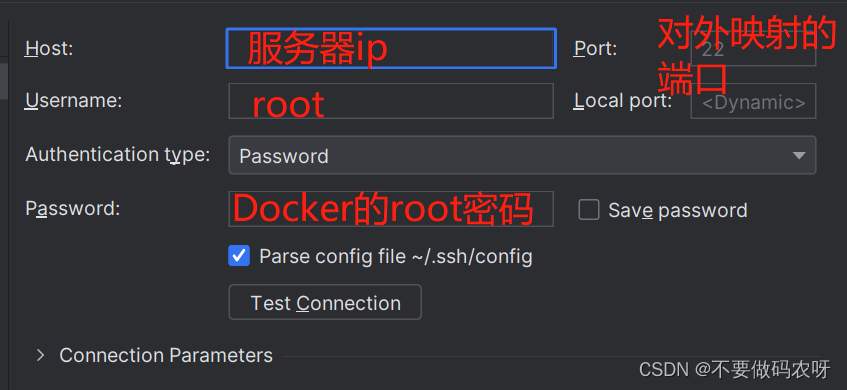
ssh root@localhost -p 12022,输入Docker的root密码,成功如下:
- 在Docker外,用ssh测试连接:
CLion
- Settings -> Build… -> Toolchains -> ‘+’ -> Remote Host

- 可以自定义名字,然后设置连接

- 按下图填写,注意port应该填写的是Docker对外映射的端口,我这里就应该是12022,而不是22,测试连接没问题就可以了
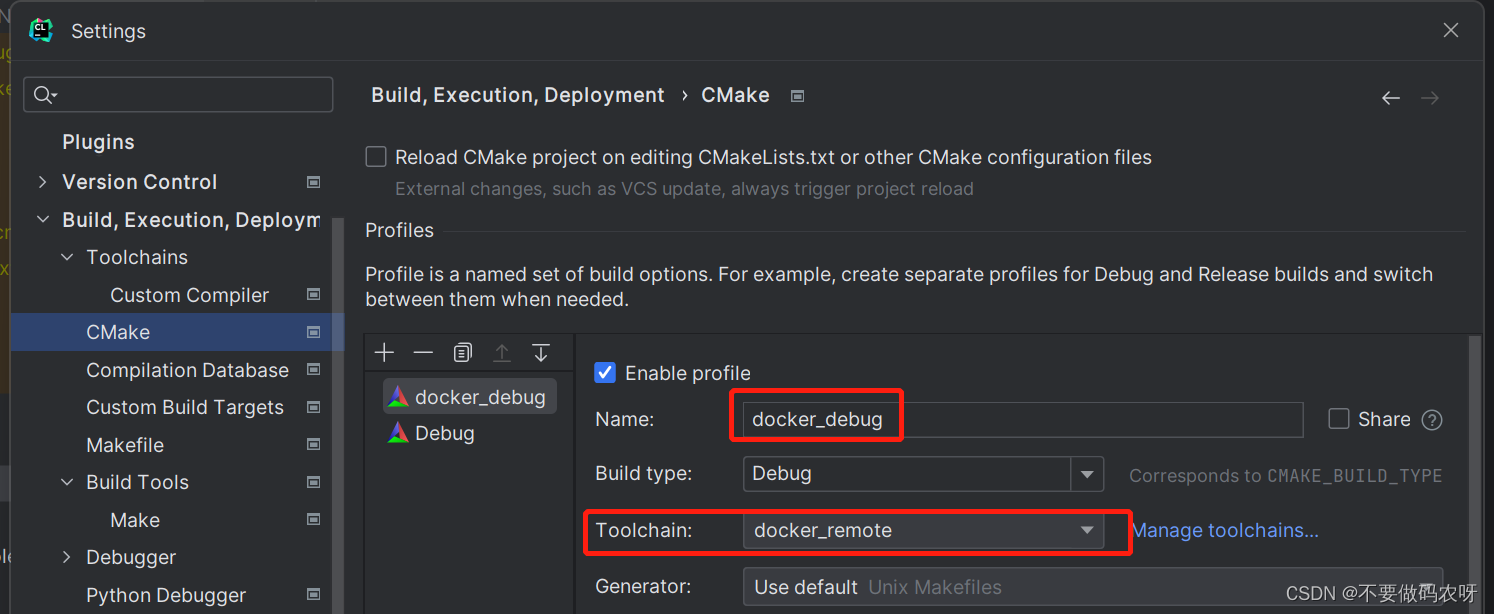
- 设置CMake:Settings -> Build… -> CMake,指定toolchains就行
- 另外,如果想把代码啥的也同步到Docker上,则添加SFTP:Settings -> Build… -> Deployment,添加SFTP,设置Mappings,见下图:

- 下面这个看自己情况设置

至此,CLion可以顺利连接到服务器里的Docker啦
Docker内配置HElib库
参考官方文档:HElib/INSTALL.md
-
apt安装依赖:g++, cmake这些
-
克隆项目,在Docker内或者在Docker外对应挂载的目录下克隆都行
-
按照官网教程编译后,在build路径下会得到一个目录
helib_pack,建议将其放至全局变量里:cp -r helib_pack /usr/local,这样在编译自己写的程序时不需要指定路径,在Clion里也能检测到这些依赖 -
测试部分参考:HElib/examples/README.md
-
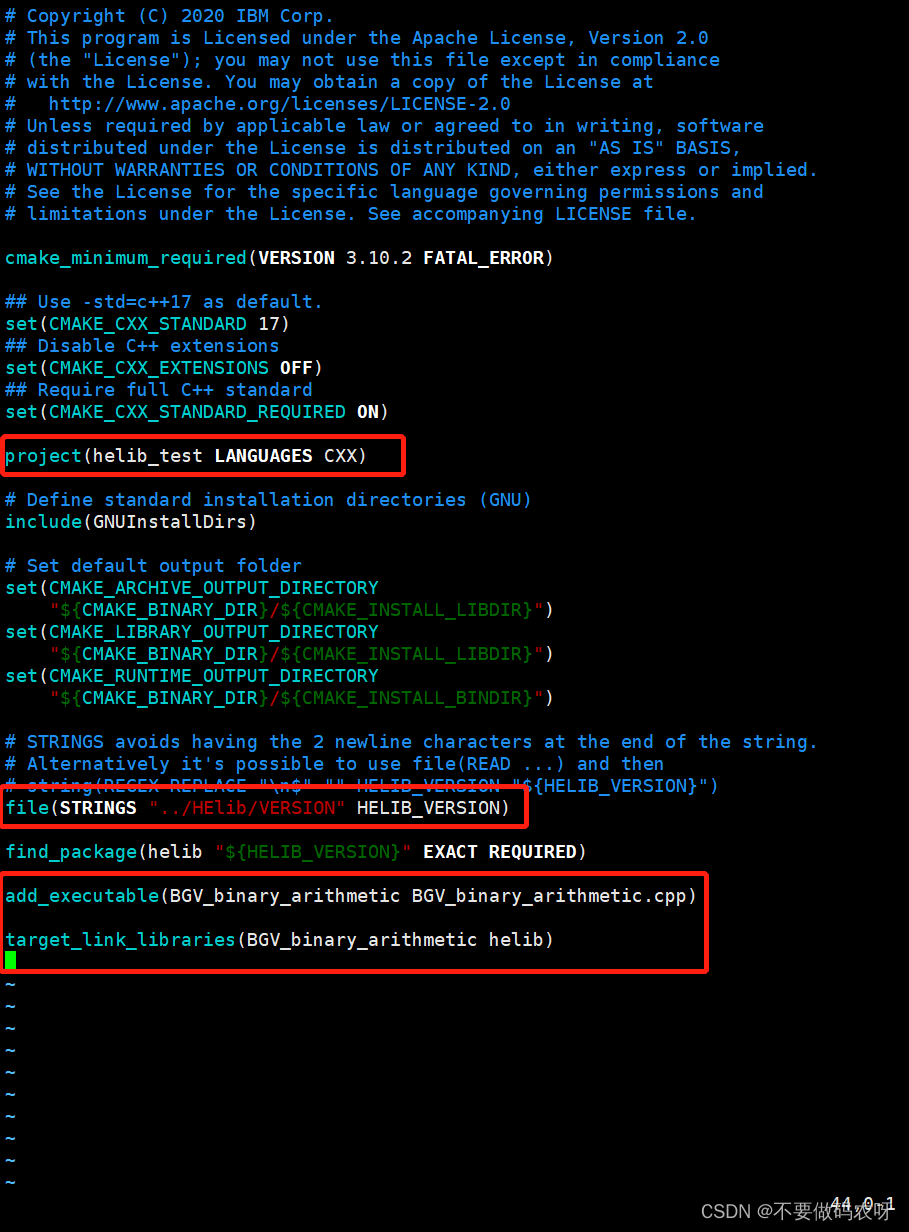
自己编写程序时,注意CMakeList.txt的写法,注意文件路径是否写对,自己编写的程序路径不同,CMakeList就需要修改对应的路径,下面是我的CMakeList,大概能改的地方圈出来了
参考
以clion为例记录一次基于docker环境配置开发-CSDN