网络建设与运维初级网站页面优化内容包括哪些
一、什么vite?
vite:是一款思维比较前卫而且先进的构建工具,他解决了一些webpack解决不了的问题——在开发环境下可以实现按需编译,加快了开发速度。而在生产环境下,它使用Rollup进行打包,提供更好的tree-shaking、代码压缩和性能优化;
vite主要解决了现有工具(如webpack、rollup)在大型项目开发过程中存在的启动慢、热更新慢等问题。vite致力于为现代前端工作流提供一个更快、更轻的解决方案。
vite是Vue团队的官方出品,背靠超级生态,Vue-cli会在下面两个版本中将vite作为预设构建工具;
未来使用vue-cli去构建vue项目的时候你要写的vue.config.js,不再是webpack的配置而是vite的配置;
它主要由两部分组成:
1、一个开发服务器,它基于 原生 ES 模块 提供了 丰富的内建功能,如速度快到惊人的 模块热更新(HMR)。
2、一套构建指令,它使用 Rollup 打包你的代码,并且它是预配置的,可输出用于生产环境的高度优化过的静态资源。
二、vite能做什么?
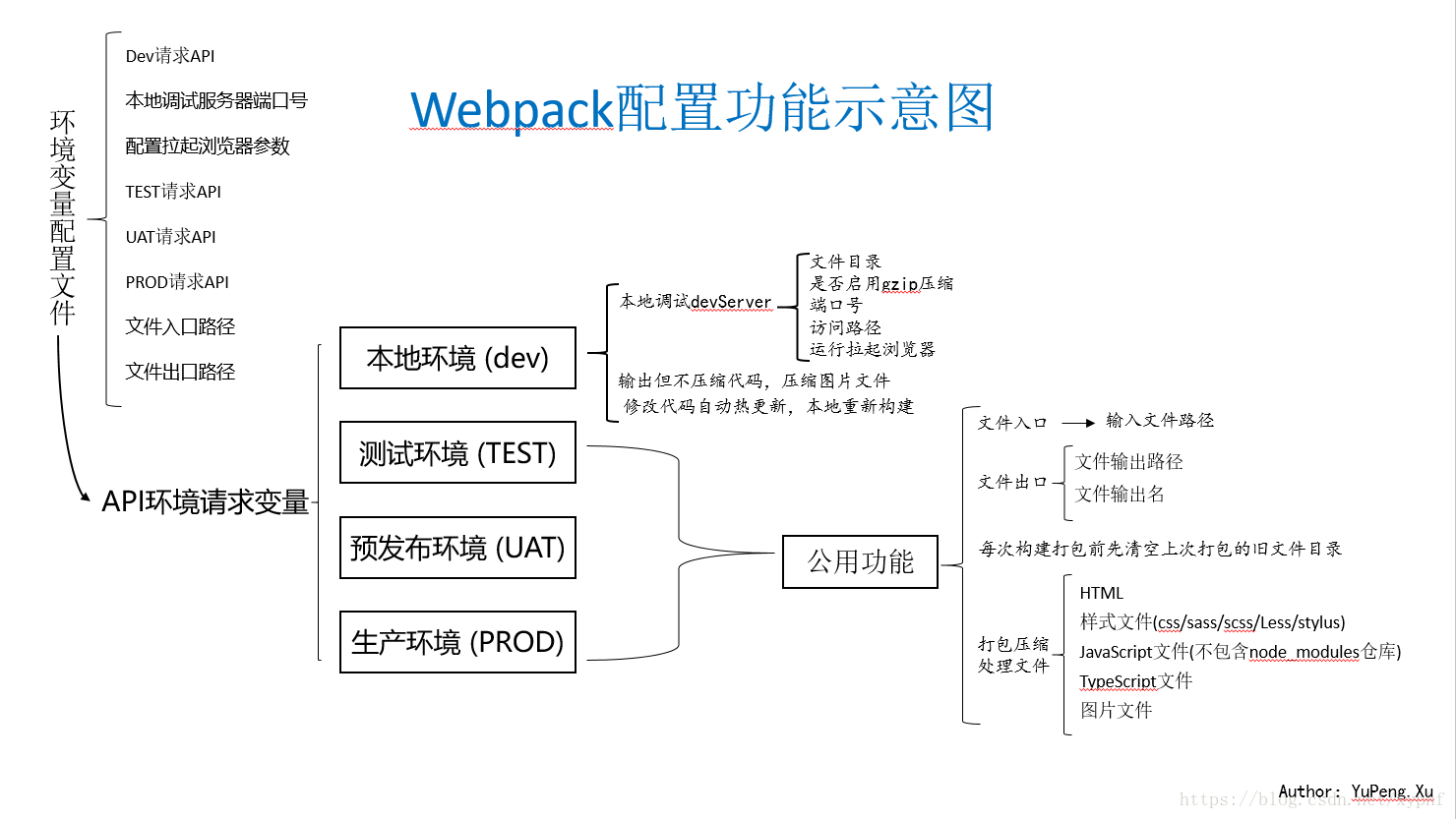
①、分环境构建
我们在开发的时候通常会分开发环境、测试环境、预发布环境、灰度环境、生产环境等,一般不同环境请求API不一样,而且一般要求开发环境代码不压缩,生产环境代码压缩等,可以根据不同的环境来进行不同的构建。
②、模块化开发
支持直接从node_modules里引入代码 + 多种模块化支持
③、兼容性处理
利用babel实现语法降级,将高版本的ES语法转换成大多数浏览器都支持的低版本ES语法,将TS语法转换成JS语法,将less、scss等css预处理器转化成css;自动添加如webkit等css头等;
④、性能优化
如实现构建速度优化、按需加载、代码压缩、动态导入、CDN加速等等;
⑤、优化开发体验
实现前端mock数据、浏览器热更新、本地开发跨域代理等等。
三、vite和webpack的区别?
webpack 4.x介绍

Webpack通过先将整个应用打包,再将打包后代码提供给dev server

Vite直接将源码交给浏览器,实现dev server秒开,浏览器显示页面需要相关模块时,再向dev server发起请求,服务器简单处理后,将该模块返回给浏览器,实现真正意义的按需加载
| Webpack | Vite | |
| 基础概念不同 | webpack是一个模块打包器,它可以把许多不同类型的模块和资源文件打包为静态资源。它具有高度的可配置性,可以通过插件和loader扩展其功能。 | vite由Vue.团队溪开发并维护,是一个基于浏览器原生 ES imports 的开发服务器。它能够提供丰富的功能,如快速冷启动、即时热更新和真正的按需编译等。 |
| 编译方式不同 | webpack在编译过程中,会将所有模块打包为一个bundle.js文件,然后再运行这个文件。 | vite在开发模式下,没有打包的步骤,它利用了浏览器的ES Module Imports特性,只有在真正需要时才编译文件。在生产模式下,vite使用Rollup进行打包,提供更好的tree-shaking,代码压缩和性能优化。 |
| 开发效率不同 | webpack的热更新是全量更新,即使修改一个小文件,也会重新编译整个应用,这在大型应用中可能会导致编译速度变慢。 | vite的热更新是增量更新,只更新修改的文件,所以即使在大型应用中也能保持极快的编译速度。 |
| 扩展性不同 | webpack有着成熟的插件生态,几乎可以实现任何你想要的功能,扩展性非常强。 | vite虽然也支持插件,但相比webpack的生态,还有一些距离。 |
| 应用场景不同 | webpack由于其丰富的功能和扩展性,适合于大型、复杂的项目。 | vite凭借其轻量和速度,更适合于中小型项目和快速原型开发。 |
| 优点 | 相对健全的生态,webpack的loader和plugin已经很成熟 | 1、vite使用esbuild预构建依赖,esbuild使用go语言编写,并且比以javascript编写的打包器构建依赖快10-100倍。 2、vite采用的是按需动态编译的模式,当浏览器请求需要的模块时,再对模块进行编译,这种处理模式极大的缩短了编译时间,当项目越大,文件越多,vite的开发时优势越明显; 3、vite的热更新比webpack快。vite在HRM方面(HMR是指当你对代码进行修改并保存后,webpack对代码重新打包,并将新的模块发送到浏览器端,浏览器通过替换旧的模块,在不刷新浏览器的前提下,就能够对应用进行更新),当改动了一个模块后,vite仅需让浏览器重新请求该模块即可,不像webpack那样需要把该模块的相关依赖模块全部编译一次,效率更高。 4、由于现代浏览器本身就支持ES Module,会自动向依赖的Module发出请求。vite充分利用了这点,将开发环境下的模块文件,就作为浏览器要执行的文件,而不是像webpack那样进行打包合并。 |
| 缺点 | 热更新效率低下。webpack的热更新需要打包构建,而vite直接响应。 | 1、生态不及webpack,加载器、插件不够丰富 2、项目的开发浏览器要支持ESmodule, 而且不能识别CommonJS语法 3、实践较少,可能存在好多问题还未暴漏出来 |