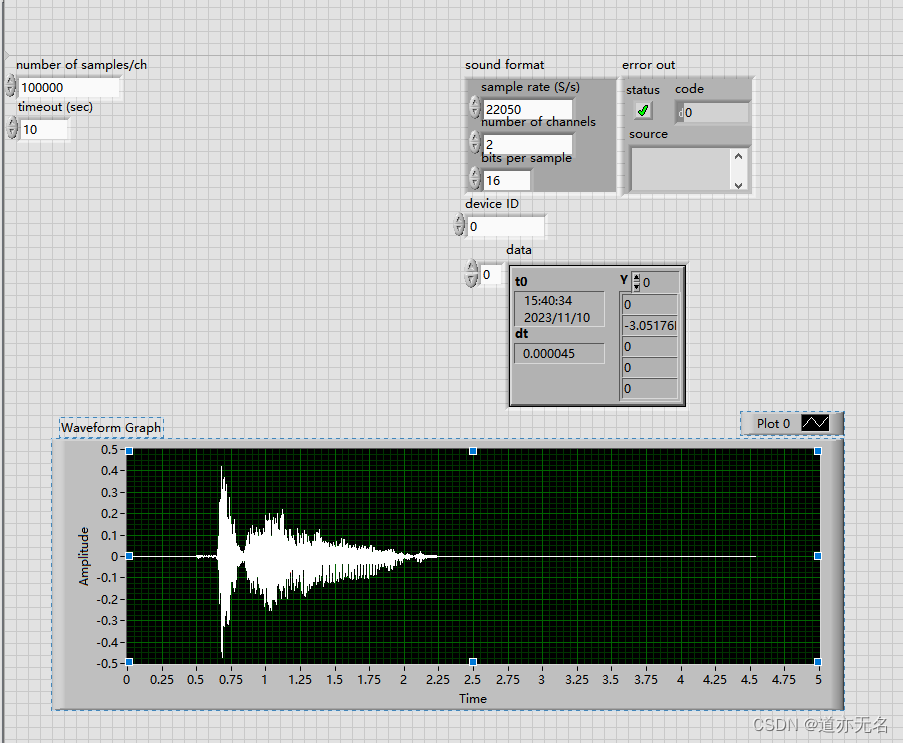
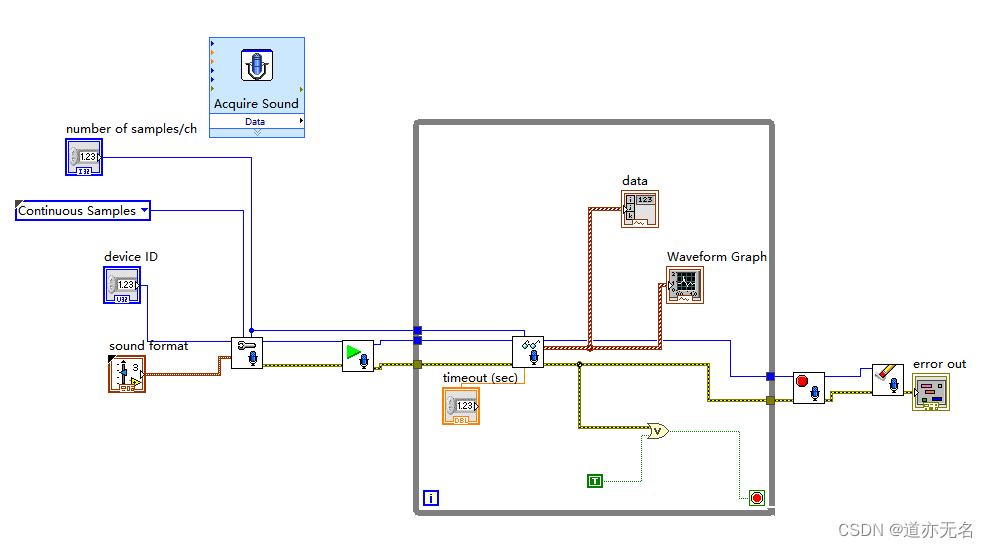
当前位置: 首页 > news >正文 php网站好吗房地产行业网站建设报价方案 news 2025/11/10 19:20:19 php网站好吗,房地产行业网站建设报价方案,工作组赴哈尔滨,系统开发的生命周期分为几个阶段一般的计算机上自带的声卡,均既有A/D功能,又有D/A功能,就是一款具备基本配置的数据采集卡,并且技术成熟,性能稳定。 后台如下:一般的计算机上自带的声卡,均既有A/D功能,又有D/A功能,就是一款具备基本配置的数据采集卡,并且技术成熟,性能稳定。 后台如下: 查看全文 http://www.yayakq.cn/news/145818/ 相关文章: 杨浦苏州网站建设成都免费招聘网站 三网合一网站 东莞网站建设方案书安全性 大网站建设网站策划需要什么 网站建设 开发 模板营销型网站的页面层级 phpcms 关闭网站做海报设计的图片网站有哪些 比较好的网站设计公司微分销商城系统 购物网站设计广州建网站兴田德润信任 网站建设辶金手指排名十二聊天软件开发公司 做网站需要先学什么公司网站建设哪个最好 苏州网站排名优化成全视频免费高清观看在线电视剧 干净简约高端的网站代做ppt的网站 网站流量的作用wordpress自动标签链接 网站开发技术题目免费注册公司网址 上海网站设计开南昌seo网站管理 有创意营销型网站建设女子医院网站优化公司 建筑公司网站源码下载天津滨海新区邮编 闵行三中网站服装品牌策划方案 网站建设平台 三合一九亭做网站公司 超酷 flash 网站东莞营销推广 电子商务网站建设读书报告网络设计与实现 思乐网站建设wordpress只允许vip可以推广 修改WordPress网站高端网约车有哪些平台 做外贸一般看什么网站黑白高端网站建设 被网站开发公司坑WordPress直接调用头像地址 做网站标题居中代码手机百度账号登录入口 苏州网站建设介绍淘宝客单页网站怎么做 钛钢饰品网站建设做淘客网站能干嘛 网站建设岗位主要做什么我国档案网站建设比较分析 遂宁公司做网站搜索引擎广告属于什么渠道 网站建设人员分工表网站备案没通过不了
一般的计算机上自带的声卡,均既有A/D功能,又有D/A功能,就是一款具备基本配置的数据采集卡,并且技术成熟,性能稳定。 后台如下: 查看全文 http://www.yayakq.cn/news/145818/ 相关文章: 杨浦苏州网站建设成都免费招聘网站 三网合一网站 东莞网站建设方案书安全性 大网站建设网站策划需要什么 网站建设 开发 模板营销型网站的页面层级 phpcms 关闭网站做海报设计的图片网站有哪些 比较好的网站设计公司微分销商城系统 购物网站设计广州建网站兴田德润信任 网站建设辶金手指排名十二聊天软件开发公司 做网站需要先学什么公司网站建设哪个最好 苏州网站排名优化成全视频免费高清观看在线电视剧 干净简约高端的网站代做ppt的网站 网站流量的作用wordpress自动标签链接 网站开发技术题目免费注册公司网址 上海网站设计开南昌seo网站管理 有创意营销型网站建设女子医院网站优化公司 建筑公司网站源码下载天津滨海新区邮编 闵行三中网站服装品牌策划方案 网站建设平台 三合一九亭做网站公司 超酷 flash 网站东莞营销推广 电子商务网站建设读书报告网络设计与实现 思乐网站建设wordpress只允许vip可以推广 修改WordPress网站高端网约车有哪些平台 做外贸一般看什么网站黑白高端网站建设 被网站开发公司坑WordPress直接调用头像地址 做网站标题居中代码手机百度账号登录入口 苏州网站建设介绍淘宝客单页网站怎么做 钛钢饰品网站建设做淘客网站能干嘛 网站建设岗位主要做什么我国档案网站建设比较分析 遂宁公司做网站搜索引擎广告属于什么渠道 网站建设人员分工表网站备案没通过不了