土建找工作去哪个网站比亚迪新能源汽车价格表
一、AI 讲解
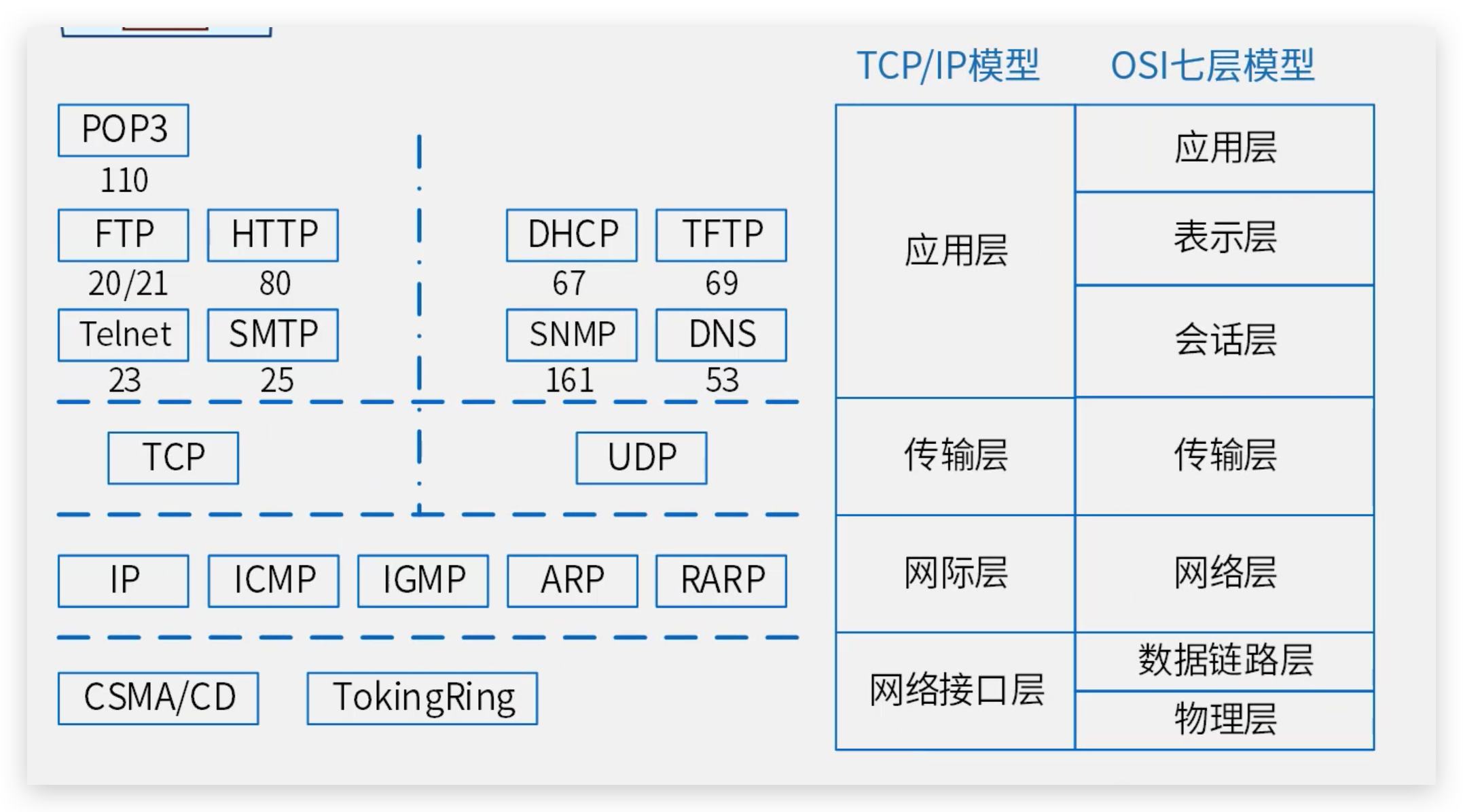
TCP/IP 协议族是一组计算机网络通信协议的集合,其中TCP和IP是两个核心协议。TCP/IP 协议族通常被用来参照互联网的基础通信架构。与之相对的OSI七层模型,是一个更为理论化的网络通信模型,它将网络通信分为七个层次。
TCP/IP 与 OSI 模型对比
| 层级 | TCP/IP 协议族 | OSI 七层模型 |
|---|---|---|
| 应用层 | 应用层 (HTTP, FTP, SMTP等) | 应用层、表示层、会话层 |
| 传输层 | 传输层 (TCP, UDP) | 传输层 |
| 网络层 | 网络层 (IP, ICMP等) | 网络层 |
| 链路层 | 网络接口层 (以太网, Wi-Fi等) | 数据链路层、物理层 |
TCP/IP 模型将应用层、表示层、会话层合并为一个应用层,而 OSI 模型则是将这三个功能层分开。同时,TCP/IP的网络接口层相当于OSI模型的数据链路层和物理层的结合。

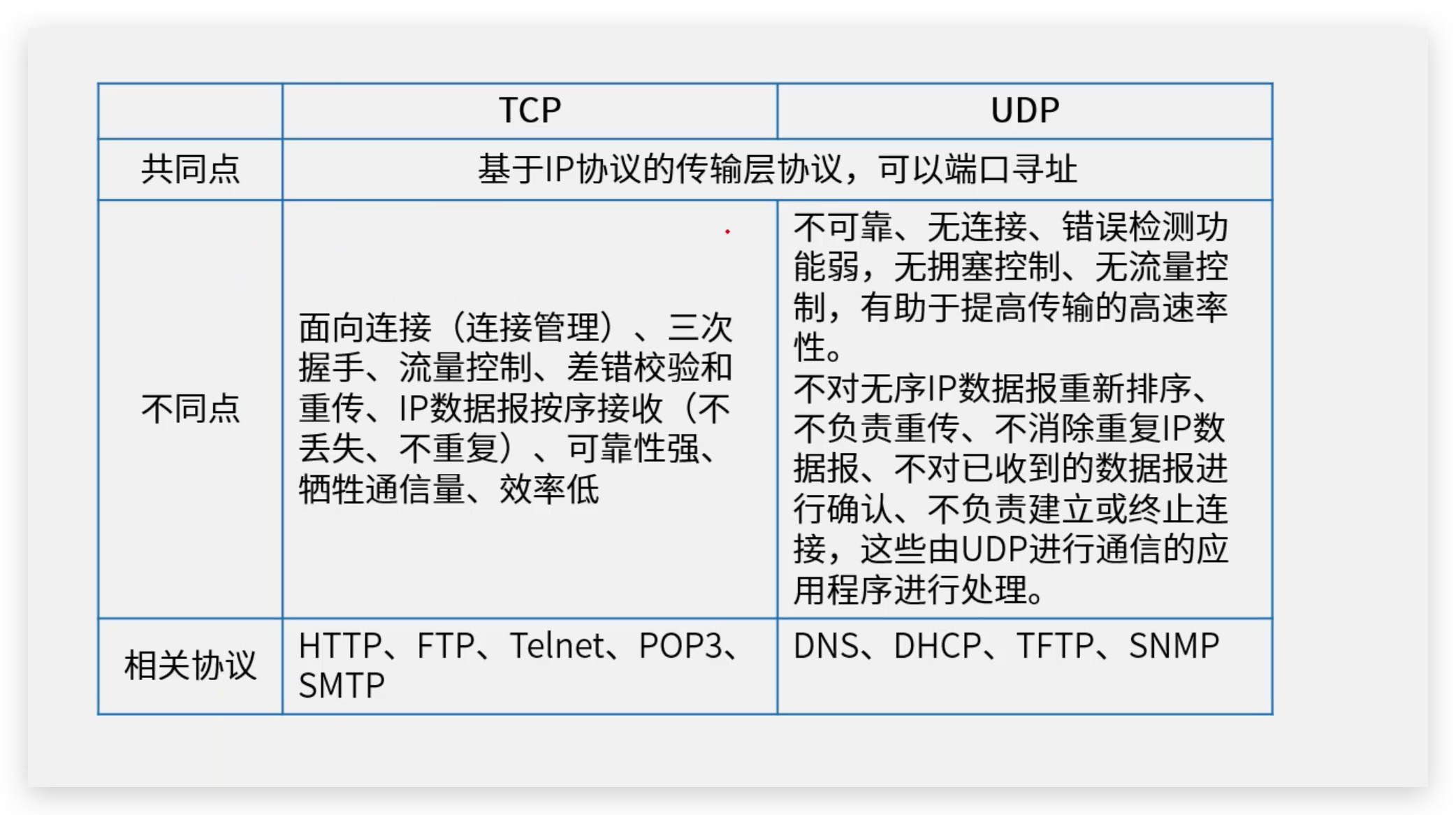
TCP 与 UDP 的区别
TCP(Transmission Control Protocol,传输控制协议)和UDP(User Datagram Protocol,用户数据报协议)是传输层的两个核心协议,它们在数据传输方式和特性上有显著的区别。
| 特性 | TCP | UDP |
|---|---|---|
| 连接类型 | 面向连接 | 无连接 |
| 可靠性 | 可靠传输,通过ACK确认、重传等机制保证数据准确 | 不可靠传输,不保证数据的准确性与顺序 |
| 速度 | 相对较慢,因为要进行连接建立、维护和拥塞控制 | 相对较快,适用于对实时性要求高的场景 |
| 应用实例 | HTTP、FTP、邮件传输等 | DNS查询、在线视频和游戏 |
| 数据传输 | 基于字节流 | 基于数据报 |
TCP提供了一种可靠的、面向连接的服务,适合对数据完整性和顺序有严格要求的应用。UDP则提供了一种不可靠的、无连接的服务,适合对传输速度和实时性要求较高的场景。
二、AI 出题
(1)题目
-
OSI 七层模型中,哪一层负责为不同数据类型的应用提供网络服务?
- A. 物理层
- B. 数据链路层
- C. 表示层
- D. 应用层
-
TCP/IP 协议族中,哪一项技术用于在网络层进行数据包路由?
- A. TCP
- B. UDP
- C. IP
- D. Ethernet
-
在TCP/IP模型中,ARP协议工作在哪一层?
- A. 应用层
- B. 传输层
- C. 网络层
- D. 链路层
-
哪种协议保证了数据的顺序传输和可靠传输?
- A. ICMP
- B. TCP
- C. UDP
- D. IP
-
UDP的特点是什么?
- A. 面向连接
- B. 可靠传输
- C. 快速传输
- D. 基于字节流
-
OSI模型的会话层的主要功能是什么?
- A. 建立、管理和终止会话
- B. 数据加密
- C. 路由选择
- D. 错误检测
-
TCP连接的三次握手指的是什么?
- A. 三次数据传输
- B. 三次密码交换
- C. 三次连接和确认过程
- D. 三次速率控制
-
IP地址分为哪两个部分?
- A. 网络地址和主机地址
- B. 主机地址和子网掩码
- C. 子网掩码和广播地址
- D. 网关地址和DNS地址
-
在TCP/IP模型中,哪一层负责提供端到端的通信服务?
- A. 应用层
- B. 传输层
- C. 网络层
- D. 链路层
-
DNS解析的过程是在TCP/IP模型的哪一层进行的?
- A. 应用层
- B. 传输层
- C. 网络层
- D. 链路层
(2)答案和解析
-
答案: D. 应用层。
解析: OSI模型的应用层为不同类型的网络应用提供了访问OSI环境的手段。 -
答案: C. IP。
解析: IP协议负责在网络层进行数据包的路由选择。 -
答案: D. 链路层。
解析: ARP(Address Resolution Protocol)协议工作在链路层,负责将IP地址转换为物理地址。 -
答案: B. TCP。
解析: TCP(
传输控制协议)提供可靠的、面向连接的数据传输服务,保证数据的顺序传输和可靠传输。
-
答案: C. 快速传输。
解析: UDP(用户数据报协议)的特点是无连接和不可靠,但由于减少了确认过程,所以传输速度较快。 -
答案: A. 建立、管理和终止会话。
解析: OSI模型的会话层负责在两个应用进程之间建立、管理和终止会话。 -
答案: C. 三次连接和确认过程。
解析: TCP连接的三次握手包括:客户端向服务器发送连接请求、服务器向客户端发送同意连接的确认、客户端再次确认。 -
答案: A. 网络地址和主机地址。
解析: IP地址由网络地址和主机地址两部分组成,用于标识网络上的每一个接口。 -
答案: B. 传输层。
解析: TCP/IP模型的传输层负责提供端到端的通信服务,确保数据正确传输。 -
答案: A. 应用层。
解析: DNS(Domain Name System)解析过程发生在应用层,它负责将域名转换为IP地址。
三、真题
