wordpress主题站模板沈阳网站定制
需求:将本地的图片上传到服务器或者云存储中,考虑之后,这里我选的是上传到又拍云云存储。
技术背景:
前端:Vue+Ajax
后端:SpringBoot
存储:又拍云云存储
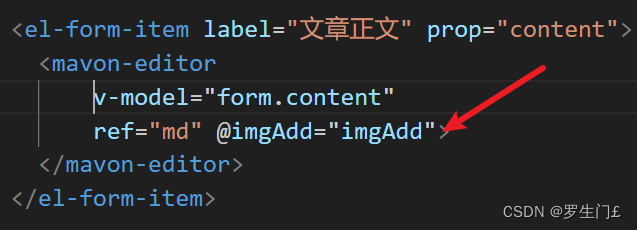
原理:Mavon-Editor编辑器有两个重要的属性和事件
ref="md"
@imgAdd="imgAdd"
所以需要将用到Mavon-Editor编辑器的组件中添加上这个属性和事件。
然后在方法中定义imgAdd函数
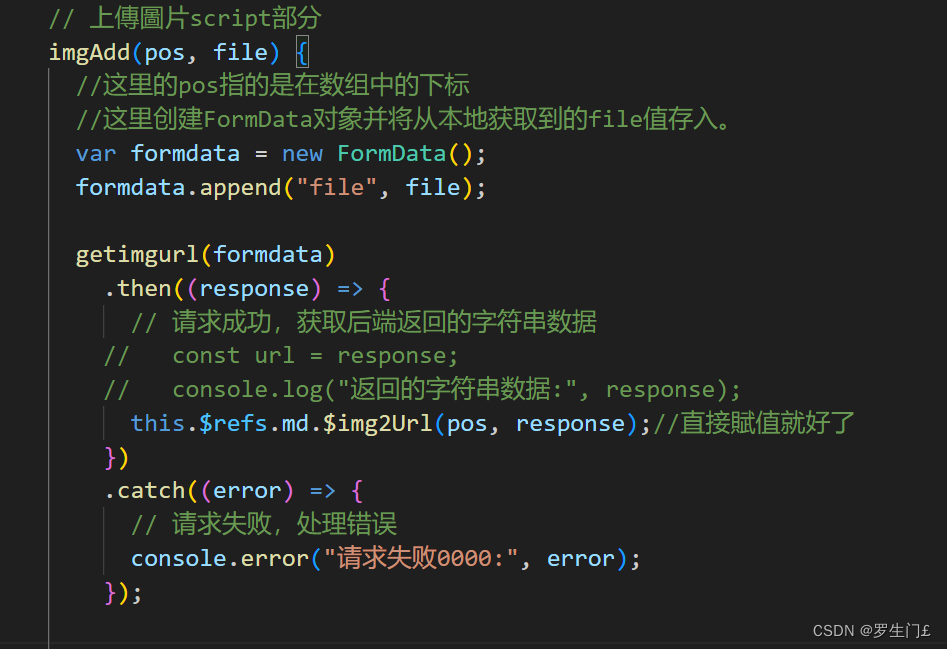
代码片段:
// 上傳圖片script部分imgAdd(pos, file) {//这里的pos指的是在数组中的下标//这里创建FormData对象并将从本地获取到的file值存入。var formdata = new FormData();formdata.append("file", file);getimgurl(formdata).then((response) => {// 请求成功,获取后端返回的字符串数据// const url = response;// console.log("返回的字符串数据:", response);this.$refs.md.$img2Url(pos, response);//直接賦值就好了}).catch((error) => {// 请求失败,处理错误console.error("请求失败0000:", error);});},
其中请求路径是你自己的后端
例如:http:localhost:8080/admin/xxx

后端需要做的:
1:导包
<!-- 又拍云配置--><dependency><groupId>com.upyun</groupId><artifactId>java-sdk</artifactId><version>4.2.3</version></dependency>
2:编写控制层处理前端请求
import com.UpYun;
import com.upyun.UpException;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.UUID;/*** 功能描述** @author:* @date: 2023年08月20日 15:37*/
@RestController
@RequestMapping("/admin")
@CrossOrigin(origins = "*", methods = {RequestMethod.GET, RequestMethod.POST, RequestMethod.PUT, RequestMethod.DELETE},allowedHeaders = {"Content-Type", "Authorization"})
public class ImgUpload {@Value("${upload.upyun.bucket-name}")private String bucketName;@Value("${upload.upyun.username}")private String username;@Value("${upload.upyun.password}")private String password;//上面的可以直接写死,不需要注入,@PostMapping("imgAdd")// 这个路径就是前端发post请求的路径public String uploadImg( MultipartFile file) throws UpException, IOException {// 拼接文件名
// System.out.println("进来了"+file);String trueFileName =file.getOriginalFilename();
// String suffix = trueFileName .substring(trueFileName .lastIndexOf("."));String fileName = UUID.randomUUID().toString()+trueFileName;// 上传到又拍云UpYun upYun=new UpYun(bucketName,username,password);
// UpYun upYun=new UpYun("空间名","操作员名称","操作员密码");String dirPath="/img/blog-img/";// 为每个文章创建了一个文件夹boolean mkDir = upYun.mkDir(dirPath);if(mkDir){
// System.out.println(dirPath+fileName);upYun.writeFile(dirPath+fileName,file.getBytes(),false);String url="https://你的域名"+dirPath+fileName;System.out.println("url: "+url.toString());return url;}else {return "后端:图片上传失败";}}}
主要思想:就是前端将本地上传的文件通过发送Ajax请求传递给后台,后台将图片上传到云存储中,然后再向前端返回图片存储的路径,这样就能正常显示在界面上了。