网站架构分析怎么写电脑培训速成班多少钱
HAL库中USART外设配置流程及库函数讲解
一说到串口通信,及必须说一下aRS-232/485协议。232协议标准物理接口就是我们常用的DB9串口线

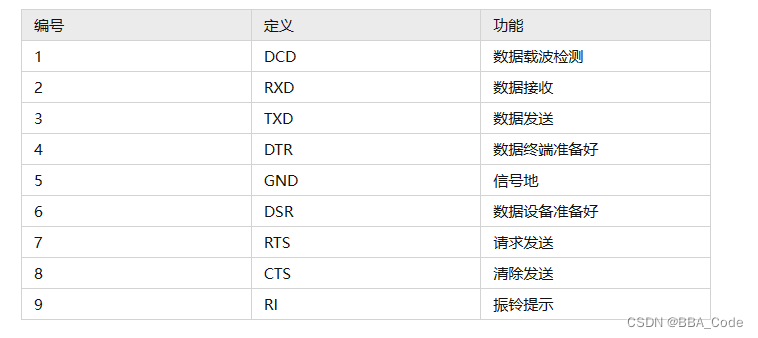
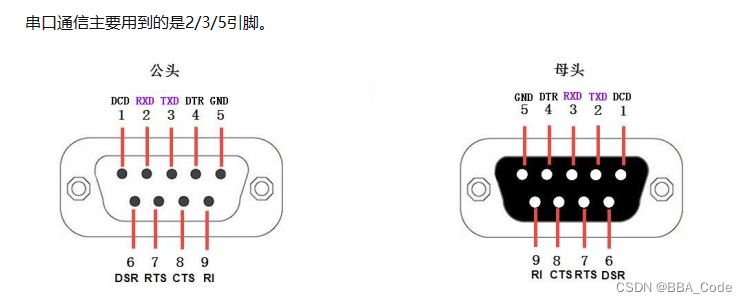
RS-232电平:
逻辑1:-15~-3
逻辑0: +3~+15
COMS电平:
逻辑1:3.3
逻辑0: 0v
TTL电平
逻辑1:5v
逻辑0:0v
电平转换问题:
TTL和COMS电平不能和232电平直接通信,会烧坏单片机。
经过电平转换芯片
常见转换芯片
MAX232
串口通信一般三根线:两个设备之间TX,RX必须交叉连接,。
现在电脑一般都没有DB9接口了,STM32一般都用USB口与电脑通信,开发板连接串口模块,USB插入电脑。
若开发板中没有板载电平转换芯片,要借助串口转换模块。
注意
现在电脑中一般已经没有了串口外设,现在要使用串口,要安装驱动用USB来模拟串口,所以电脑中需要安装对应芯片驱动CH340
USART/UART异步通信配置步骤:
HAL库初始化USART:
bsp_usart.c
#include "./usart/bsp_debug_usart.h"UART_HandleTypeDef UartHandle;
//extern uint8_t ucTemp; /*** @brief DEBUG_USART GPIO 配置,工作模式配置。115200 8-N-1* @param 无* @retval 无*/
void DEBUG_USART_Config(void)
{ UartHandle.Instance = DEBUG_USART;UartHandle.Init.BaudRate = DEBUG_USART_BAUDRATE;UartHandle.Init.WordLength = UART_WORDLENGTH_8B;UartHandle.Init.StopBits = UART_STOPBITS_1;UartHandle.Init.Parity = UART_PARITY_NONE;UartHandle.Init.HwFlowCtl = UART_HWCONTROL_NONE;UartHandle.Init.Mode = UART_MODE_TX_RX;HAL_UART_Init(&UartHandle);/*使能串口接收断 */__HAL_UART_ENABLE_IT(&UartHandle,UART_IT_RXNE);
}/*** @brief UART MSP 初始化 * @param huart: UART handle* @retval 无*/
void HAL_UART_MspInit(UART_HandleTypeDef *huart)
{ GPIO_InitTypeDef GPIO_InitStruct;DEBUG_USART_CLK_ENABLE();DEBUG_USART_RX_GPIO_CLK_ENABLE();DEBUG_USART_TX_GPIO_CLK_ENABLE();/**USART1 GPIO Configuration PA9 ------> USART1_TXPA10 ------> USART1_RX *//* 配置Tx引脚为复用功能 */GPIO_InitStruct.Pin = DEBUG_USART_TX_PIN;GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;GPIO_InitStruct.Pull = GPIO_PULLUP;GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_HIGH;HAL_GPIO_Init(DEBUG_USART_TX_GPIO_PORT, &GPIO_InitStruct);/* 配置Rx引脚为复用功能 */GPIO_InitStruct.Pin = DEBUG_USART_RX_PIN;GPIO_InitStruct.Mode=GPIO_MODE_AF_INPUT; //模式要设置为复用输入模式! HAL_GPIO_Init(DEBUG_USART_RX_GPIO_PORT, &GPIO_InitStruct); HAL_NVIC_SetPriority(DEBUG_USART_IRQ ,0,1); //抢占优先级0,子优先级1HAL_NVIC_EnableIRQ(DEBUG_USART_IRQ ); //使能USART1中断通道
}/***************** 发送字符串 **********************/
void Usart_SendString(uint8_t *str)
{unsigned int k=0;do {HAL_UART_Transmit(&UartHandle,(uint8_t *)(str + k) ,1,1000);k++;} while(*(str + k)!='\0');}
//重定向c库函数printf到串口DEBUG_USART,重定向后可使用printf函数
int fputc(int ch, FILE *f)
{/* 发送一个字节数据到串口DEBUG_USART */HAL_UART_Transmit(&UartHandle, (uint8_t *)&ch, 1, 1000); return (ch);
}//重定向c库函数scanf到串口DEBUG_USART,重写向后可使用scanf、getchar等函数
int fgetc(FILE *f)
{ int ch;HAL_UART_Receive(&UartHandle, (uint8_t *)&ch, 1, 1000); return (ch);
}/*********************************************END OF FILE**********************/bsp_usart.h
#ifndef __DEBUG_USART_H
#define __DEBUG_USART_H#include "stm32f1xx.h"
#include <stdio.h>//串口波特率
#define DEBUG_USART_BAUDRATE 115200//引脚定义
/*******************************************************/
#define DEBUG_USART USART1
#define DEBUG_USART_CLK_ENABLE() __HAL_RCC_USART1_CLK_ENABLE();#define DEBUG_USART_RX_GPIO_PORT GPIOA
#define DEBUG_USART_RX_GPIO_CLK_ENABLE() __HAL_RCC_GPIOA_CLK_ENABLE()
#define DEBUG_USART_RX_PIN GPIO_PIN_10#define DEBUG_USART_TX_GPIO_PORT GPIOA
#define DEBUG_USART_TX_GPIO_CLK_ENABLE() __HAL_RCC_GPIOA_CLK_ENABLE()
#define DEBUG_USART_TX_PIN GPIO_PIN_9#define DEBUG_USART_IRQHandler USART1_IRQHandler
#define DEBUG_USART_IRQ USART1_IRQn
/************************************************************/void Usart_SendString(uint8_t *str);
void DEBUG_USART_Config(void);
int fputc(int ch, FILE *f);
int fgetc(FILE *f);
extern UART_HandleTypeDef UartHandle;
#endif /* __USART1_H */mian.c
int main(void)
{HAL_Init(); /* 配置系统时钟为72 MHz */ SystemClock_Config();/*初始化USART 配置模式为 115200 8-N-1,中断接收*/DEBUG_USART_Config();/*调用printf函数,因为重定向了fputc,printf的内容会输出到串口*/printf("欢迎使用野火开发板\n"); /*自定义函数方式*/Usart_SendString( (uint8_t *)"自定义函数输出:这是一个串口中断接收回显实验\n" );while(1){ }
}
HAL库USART外设驱动函数:
/** @addtogroup UART_Exported_Functions_Group2* @{*/
/* IO operation functions *******************************************************/
HAL_StatusTypeDef HAL_UART_Transmit(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size, uint32_t Timeout);
HAL_StatusTypeDef HAL_UART_Receive(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size, uint32_t Timeout);
HAL_StatusTypeDef HAL_UART_Transmit_IT(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size);
HAL_StatusTypeDef HAL_UART_Receive_IT(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size);
HAL_StatusTypeDef HAL_UART_Transmit_DMA(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size);
HAL_StatusTypeDef HAL_UART_Receive_DMA(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size);
HAL_StatusTypeDef HAL_UART_DMAPause(UART_HandleTypeDef *huart);
HAL_StatusTypeDef HAL_UART_DMAResume(UART_HandleTypeDef *huart);
HAL_StatusTypeDef HAL_UART_DMAStop(UART_HandleTypeDef *huart);
/* Transfer Abort functions */
HAL_StatusTypeDef HAL_UART_Abort(UART_HandleTypeDef *huart);
HAL_StatusTypeDef HAL_UART_AbortTransmit(UART_HandleTypeDef *huart);
HAL_StatusTypeDef HAL_UART_AbortReceive(UART_HandleTypeDef *huart);
HAL_StatusTypeDef HAL_UART_Abort_IT(UART_HandleTypeDef *huart);
HAL_StatusTypeDef HAL_UART_AbortTransmit_IT(UART_HandleTypeDef *huart);
HAL_StatusTypeDef HAL_UART_AbortReceive_IT(UART_HandleTypeDef *huart);void HAL_UART_IRQHandler(UART_HandleTypeDef *huart);
void HAL_UART_TxCpltCallback(UART_HandleTypeDef *huart);
void HAL_UART_TxHalfCpltCallback(UART_HandleTypeDef *huart);
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart);
void HAL_UART_RxHalfCpltCallback(UART_HandleTypeDef *huart);
void HAL_UART_ErrorCallback(UART_HandleTypeDef *huart);
void HAL_UART_AbortCpltCallback (UART_HandleTypeDef *huart);
void HAL_UART_AbortTransmitCpltCallback (UART_HandleTypeDef *huart);
void HAL_UART_AbortReceiveCpltCallback (UART_HandleTypeDef *huart);
/**
HAL_StatusTypeDef HAL_UART_Receive_IT(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size)
作用:以中断的方式接收指定字节的数据
形参1是UART_ HandleTypeDef结构体类型指针变量
形参2是指向接收数据缓冲区
形参3是要接收的数据大小,以字节为单位
HAL_StatusTypeDef HAL_UART_Transmit(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size, uint32_t Timeout)
作用:以阻塞的方式发送指定字节的数据
形参1 : UART_ HandleTypeDef 结构体类型指针变量
形参2:指向要发送的数据地址
形参3:要发送的数据大小,以字节为单位
形参4:设置的超时时间,以ms单位