网站联系方式设置要求百度竞价托管运营
Spring Validation概述
在开发中,我们经常遇到参数校验的需求,比如用户注册的时候,要校验用户名不能为空、用户名长度不超过20个字符、手机号是合法的手机号格式等等。如果使用普通方式,我们会把校验的代码和真正的业务处理逻辑耦合在起,而且如果未来要新增一种校验逻辑也需要在修改多个地方。而spring validation允许通过注解的方式来定义对象校验规则,把校验和业务逻辑分离开,让代码编写更加方便。Spring Validation其实就是对Hibernate Validator进一步的封装,方便在Spring中使用。
在Spring中有多种校验的方式
第一种是通过实现org.springframework.validation.Validator接口,然后在代码中调用这个类第二种是按照Bean Validation方式来进行校验,即通过注解的方式
第三种是基于方法实现校验
第四种实现自定义校验
通过实现Validator接口实现
创建子模块 spring6-validator
引入依赖
<dependencies><dependency><groupId>org.hibernate.validator</groupId><artifactId>hibernate-validator</artifactId><version>7.0.5.Final</version></dependency><dependency><groupId>org.glassfish</groupId><artifactId>jakarta.el</artifactId><version>4.0.1</version></dependency></dependencies>创建实体类,定义属性,创建对应的set与get方法
public class Person {private String name;private int age;public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}
}创建类,实现接口,实现接口的方法,编写校验逻辑
supports方法用来表示此校验用在哪个类型上
validate是设置校验逻辑的地点,其中ValidatorUtils,是Spring封装的校验工具类,帮助快速实现校验
public class PersonValidator implements Validator {@Overridepublic boolean supports(Class<?> clazz) {//supports方法用来表示此校验用在哪个类型上return Person.class.equals(clazz);}//校验规则@Overridepublic void validate(Object target, Errors errors) {//validate是设置校验逻辑的地点,其中ValidatorUtils,是Spring封装的校验工具类,帮助快速实现校验//name不能为空ValidationUtils.rejectIfEmpty(errors,"name","name.empty","name is null");//age 不能小于0 不能大于100Person p = (Person) target;if (p.getAge() < 0){errors.rejectValue("age","age.value.error","age < 0");} else if (p.getAge() > 200) {errors.rejectValue("age","age.value.old","age > 200");}}
}完成测试
//校验测试
public class TestPerson {public static void main(String[] args) {//创建person对象Person person = new Person();//创建person对应databinderDataBinder binder = new DataBinder(person);//设置 校验器binder.setValidator(new PersonValidator());//调用方法执行校验binder.validate();//输出校验结果BindingResult result = binder.getBindingResult();System.out.println(result.getAllErrors());}
}Bean Validation注解实现
使用Bean Validation校验方式,就是如何将Bean Validation需要使用的javax.validation.ValidatorFactory 和javax.validation.Validator注入到容器中。
spring默认有一个实现类LocalValidatorFactoryBean,它实现了上面Bean Validation中的接口,并且也实现了org.springframework.validation.Validator接口。
创建配置类ValidationConfig,配置LocalValidatorFactoryBean
@Configuration
@ComponentScan("com.yogurt.spring6.validator.two")
public class ValidationConfig {@Beanpublic LocalValidatorFactoryBean validator(){return new LocalValidatorFactoryBean();}
}创建实体类,定义属性,创建对应的set与get方法,在属性上面使用注解设置校验规则
常用注解说明
@NotNull 限制必须不为null
@NotEmpty 只作用于字符串类型,字符串不为空,并且长度不为0@NotBlank 只作用于字符串类型,字符串不为空,并且trim0后不为空串@DecimalMax(value) 限制必须为一个不大于指定值的数字
@DecimalMin(value) 限制必须为一个不小于指定值的数字
@Max(value) 限制必须为一个不大于指定值的数字
@Min(value)限制必须为一个不小于指定值的数字限制必须符合指定的正则表达式@Pattern(value)
@size(max,min) 限制字符长度必须在min到max之间
@Email 验证注解的元素值是Email,也可以通过正则表达式和flag指定自定义的email格式
public class User {@NotNullprivate String name;@Min(0)@Max(150)private int age;public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}
}在属性上面使用注解设置校验规则

创建校验器
用原生:import jakarta.validation.Validator;
@Service
public class MyValidation1 {@Autowiredprivate Validator validator;private boolean validatorByUserOne(User user){Set<ConstraintViolation<User>> validate = validator.validate(user);return validate.isEmpty();}
}用spring框架中:import org.springframework.validation.Validator;
@Service
public class MyValidation2 {@Autowiredprivate Validator validator;public boolean validatorByUserTwo(User user){BindException bindException = new BindException(user, user.getName());validator.validate(user,bindException);return bindException.hasErrors();}
}完成测试
原生测试:
@Testpublic void testValidationOne(){ApplicationContext context = new AnnotationConfigApplicationContext(ValidationConfig.class);MyValidation1 validation1 = context.getBean(MyValidation1.class);User user = new User();//user.setName("luck");//user.setAge(20);boolean message = validation1.validatorByUserOne(user);System.out.println(message);}正常结果
spring框架测试:
@Testpublic void testValidationTwo(){ApplicationContext context = new AnnotationConfigApplicationContext(ValidationConfig.class);MyValidation2 validation2 = context.getBean(MyValidation2.class);User user = new User();
// user.setName("luck");
// user.setAge(20);boolean message = validation2.validatorByUserTwo(user);System.out.println(message);}
}报错:
java.lang.IllegalArgumentException: Object name must not be null
修改-->设置姓名和年龄:
@Testpublic void testValidationTwo(){ApplicationContext context = new AnnotationConfigApplicationContext(ValidationConfig.class);MyValidation2 validation2 = context.getBean(MyValidation2.class);User user = new User();user.setName("luck");user.setAge(20);boolean message = validation2.validatorByUserTwo(user);System.out.println(message);}
}基于方法实现校验
创建配置类ValidationConfig
@Configuration
@ComponentScan("com.yogurt.spring6.validator.three")
public class ValidationConfig {@Beanpublic MethodValidationPostProcessor validationPostProcessor(){return new MethodValidationPostProcessor();}
}
创建实体类,定义属性,创建对应的set与get方法,在属性上面使用注解设置校验规则
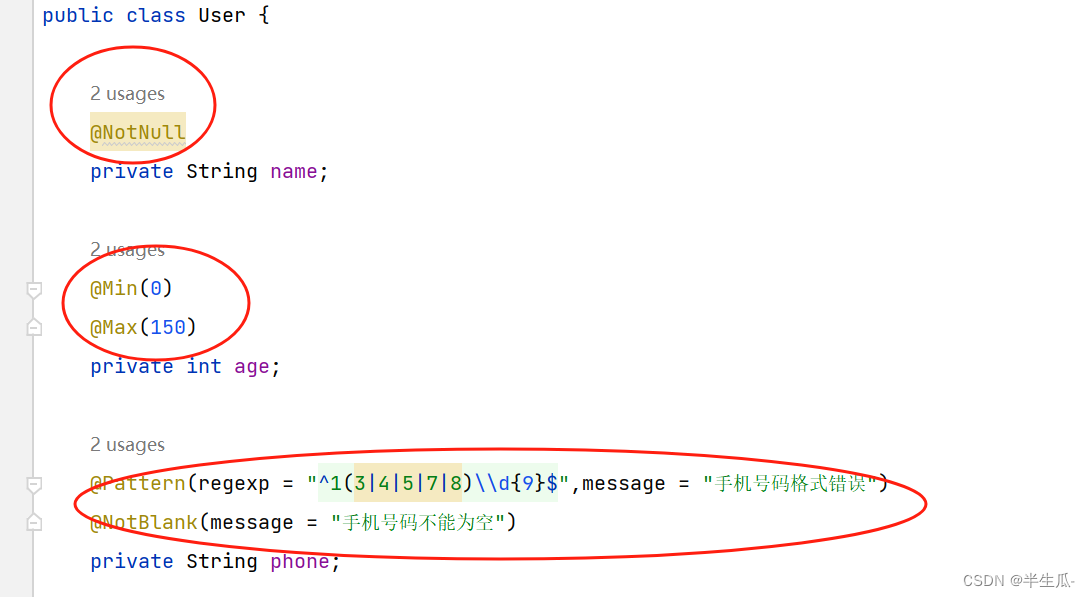
public class User {@NotNullprivate String name;@Min(0)@Max(150)private int age;@Pattern(regexp = "^1(3|4|5|7|8)\\d{9}$",message = "手机号码格式错误")@NotBlank(message = "手机号码不能为空")private String phone;public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getPhone() {return phone;}public void setPhone(String phone) {this.phone = phone;}
}
在属性上面使用注解设置校验规则
创建校验器
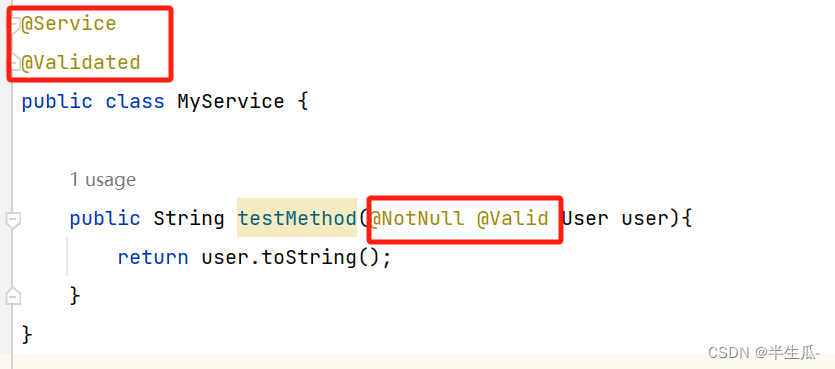
@Service
@Validated
public class MyService {public String testMethod(@NotNull @Valid User user){return user.toString();}
}
完成测试
public class TestUser {public static void main(String[] args) {ApplicationContext context = new AnnotationConfigApplicationContext(ValidationConfig.class);MyService service = context.getBean(MyService.class);User user = new User();//user.setName("lucy");//user.setPhone("15545451223");service.testMethod(user);}
}
报错:Exception in thread "main" jakarta.validation.ConstraintViolationException: testMethod.arg0.name: 不能为null, testMethod.arg0.phone: 手机号码不能为空
修改-->设置姓名和手机号:
public class TestUser {public static void main(String[] args) {ApplicationContext context = new AnnotationConfigApplicationContext(ValidationConfig.class);MyService service = context.getBean(MyService.class);User user = new User();user.setName("lucy");user.setPhone("15545451223");service.testMethod(user);}
}