做网站要学哪些wordpress站群seo
前言
在现代Web开发中,图像处理是一个不可或缺的部分。
前端开发者经常需要处理图像,以确保它们在不同的设备和分辨率上都能保持良好的显示效果。
sharp.js是一个高性能的Node.js模块,它利用了libvips库,提供了快速且高效的图像处理能力。
本文将介绍sharp.js的基本使用和一些进阶技巧。
官网:https://sharp.pixelplumbing.com/
github:https://github.com/lovell/sharp
简介
sharp.js是一个基于 Node-API 的模块,它能够将大型图像转换为更小、更适合网络传输的格式,如JPEG、PNG、WebP、GIF和AVIF。
它支持所有支持 Node-API v9的 JavaScript 运行时环境,包括 Node.js 、Deno 和 Bun 。
使用sharp.js进行图像缩放的速度比使用 ImageMagick 和 GraphicsMagick 的最快设置快4到5倍。
基本使用
我们准备了一张原图

首先,确保你已经安装了Node.js版本18.17.0或更高版本。
然后,你可以通过npm或yarn安装sharp.js:
npm install sharp
# 或者
yarn add sharp
接下来,你可以使用以下代码来加载一个图像并将其缩放到指定的尺寸:
const sharp = require('sharp');sharp('input.png').resize(300, 200).toFile('output.jpg').then(() => console.log('Image resized and saved!')).catch(err => console.error('Error resizing image:', err));

这段代码将加载input.jpg文件,将其缩放到300x200像素,然后保存为output.jpg。
进阶使用
sharp.js不仅支持缩放,还支持压缩、旋转、裁剪、合成等操作。
以下是一些进阶用法的示例:
- 压缩图像:
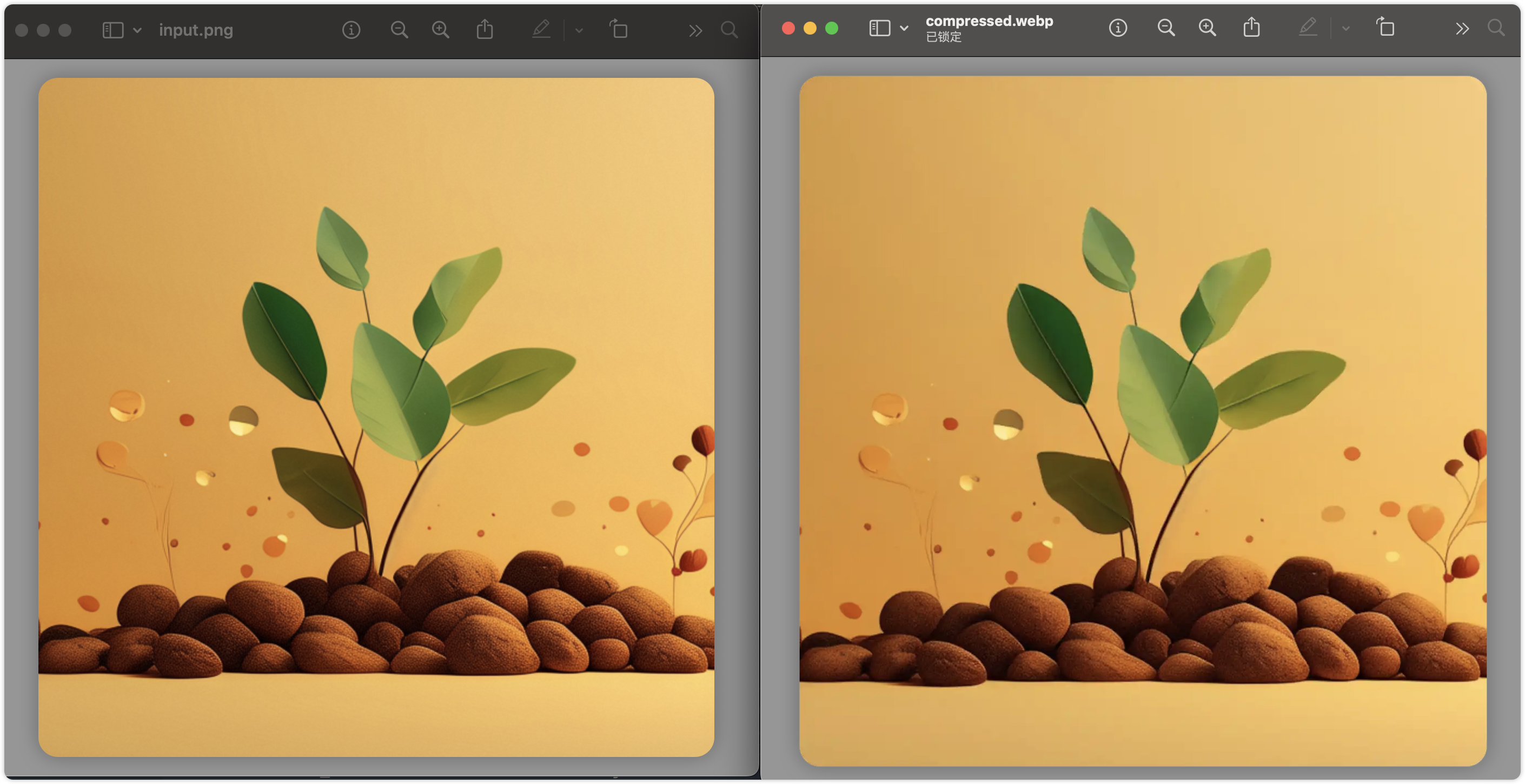
sharp('input.png').webp({ quality: 50 }) // 使用WebP格式并设置质量为50.toFile('compressed.webp')
这行代码把一张2M的图片压缩到了32kb,对比效果如下:
- 旋转图像:
sharp('input.png').rotate(90) // 顺时针旋转90度.toFile('rotated.jpg');

- 裁剪图像:
sharp('input.png').extract({ left: 100, top: 100, width: 200, height: 200 }).toFile('cropped.jpg');

- 图像合成:水印等场景
// 合成图片
sharp('input.png').composite([{ input: './logo.png', gravity: 'center' },]).toFile('combined.png');

总结
以上的图片处理能力,按理说是可以在 electron 中使用的,这样的话不就可以依赖这个库做一个本地的图片处理工具么。
不过这种涉及文件流处理的库应该引用了一些系统级的库,估计在 electorn 中使用不会那么简单,如果只是简单的图片处理的话,纯前端的能力已经足够。
sharp.js是一个强大的图像处理库,它提供了快速且高效的图像处理功能,非常适合需要处理大量图像的Web应用。
它支持多种图像操作,并且易于使用。
– 欢迎点赞、关注、转发、收藏【我码玄黄】,各大平台同名。