做网站是先买域名还是智能制造工程
1. Linux
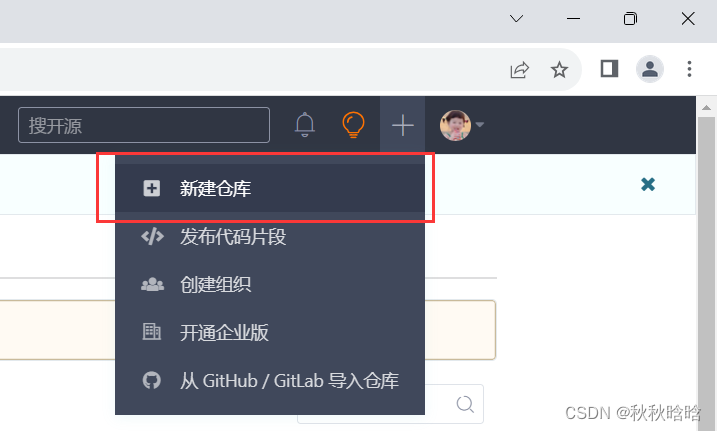
1.1 创建远程仓库

1.2 安装git
sudo yum install -y git1.3 克隆远程仓库到本地

git clone 地址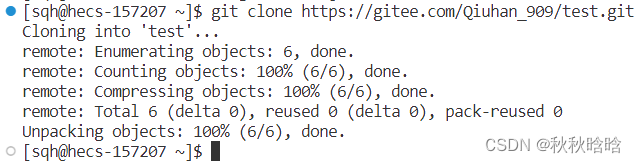
1.4 将文件添加到git的暂存区(git三板斧之add)
git add 文件名 # 将指定文件添加到git的暂存区
git add . # 添加新文件和修改过的文件不包括删除的文件1.5 将暂存区的内容提交到本地仓库(git三板斧之commit)
git commit -m "日志信息"如果是第一次提交,需要配置邮箱和用户名。
# 配置全局的邮箱和用户名,会应用到所有的git仓库
# 如果只想对当前项目生效而不影响其他项目,去掉--global
git config --global user.email "you@example.com"
git config --global user.name "Your Name"# 查看已经配置成功的邮箱和用户名
git config user.email
git config user.name![]()
1.6 将本地仓库的内容推送到远程仓库(git三板斧之push)
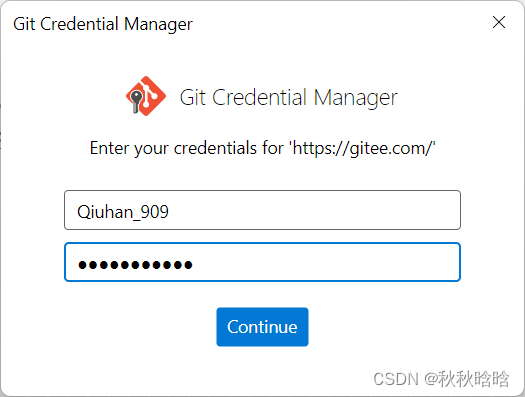
git push提示输入gitee账号的用户名(@后面的那一串,不包括@,不是上面配置的用户名)和密码,然后就完成了。

1.7 查看仓库的日志信息
git log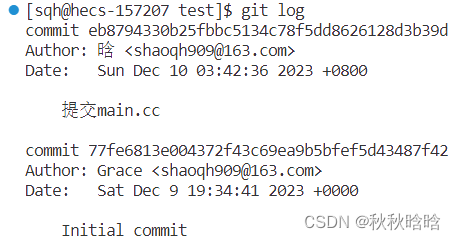
1.8 查看仓库的状态
git status
1.9 删除文件
git rm 文件名
git rm -r 目录名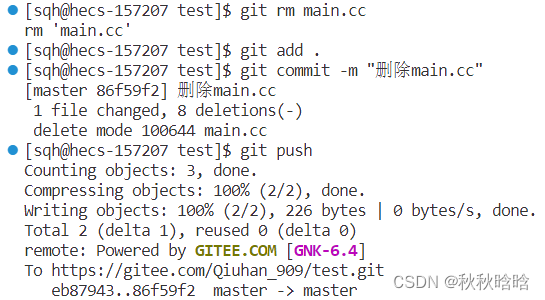
1.10 删除本地仓库
rm -rf .git2. Windows
2.1 创建远程仓库
1.2 安装Git和TortoiseGit
Git
先安装Git,一直NEXT。
TortoiseGit – Windows Shell Interface to Git
再安装小乌龟,一直NEXT,直到让你配置用户名和邮箱,和Llinux下用git config --global配置是类似的。然后再一直NEXT。

1.3 克隆远程仓库到本地

比如说,想把远程仓库克隆到A文件夹,打开A文件夹——在文件夹内空白处右击鼠标——显示更多选项——Git Clone


1.4 修改.gitignore
用记事本打开.gitignore,在后面加上
*.sln
*.vcxproj
*.filters
*.user
*.suo
*.db
*.ipch
Debug/
.vs
Release/
忽略不想要的文件和文件夹,防止它们上传到远程仓库。
1.5 将文件添加到git的暂存区(git三板斧之add)
打开仓库那个文件夹——在文件夹内空白处右击鼠标——显示更多选项——TortoiseGit——ADD

然后一直OK。
1.6 将暂存区的内容提交到本地仓库(git三板斧之commit)
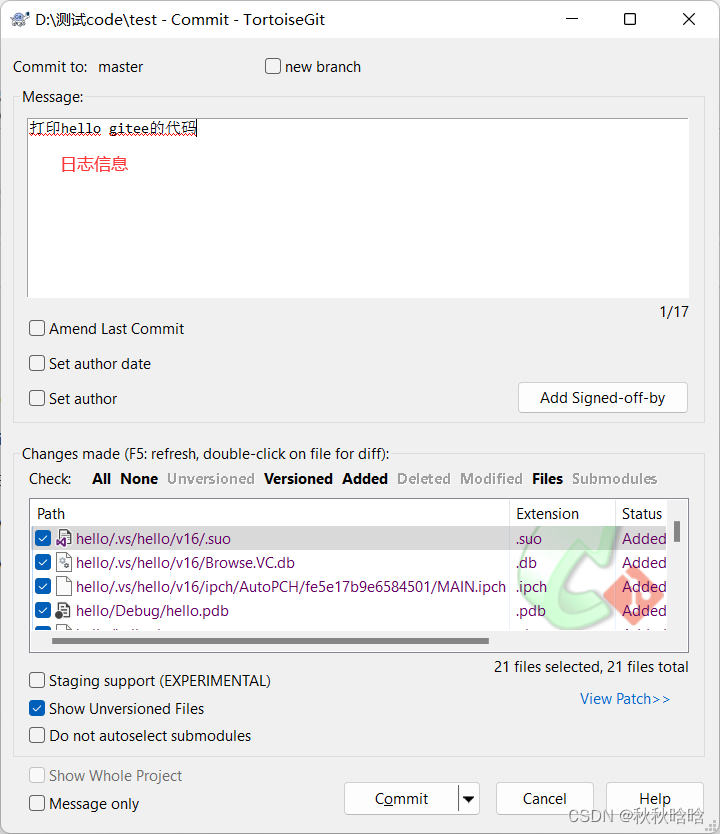
1.7 将本地仓库的内容推送到远程仓库(git三板斧之push)

提示输入gitee账号的用户名(@后面的那一串,不包括@,不是上面配置的用户名)和密码,然后就完成了。