织梦网站最新漏洞入侵东台建设局官方网站
目录
一、前言
二、 什么是操作系统
💦操作系统的引入
💦操作系统的概念理解
💦操作系统设计的目的与定位
💦总结
二、操作系统之上之下分别有什么
三、深度理解操作系统的“管理”
💦场景理解
💦操作系统(OS) 的“管理”
✨操作系统如何进行管理?
🍎向下对硬件做管理
🍐向上对用户提供服务
✨操作系统管理的目的
四、共勉
一、前言
在学习了【Linux基础】之后,我们将开启【Linux系统编程】的学习。既然是系统编程,那我们首先肯定需要了解---系统。系统有怎样的体系结构(冯 • 诺依曼体系结构),系统如进行软硬件资源管理(操作系统)。只有了解系统,才能够更好的掌握 ---- 系统编程
上一次已经讲过了 冯 • 诺依曼体系结构 :冯 · 诺依曼体系结构
所以本次博客将从-----操作系统讲起!!
二、 什么是操作系统
💦操作系统的引入
我们上面所讲到的冯诺依曼体系中的各大部件可以理解为硬件,在冯诺依曼体系之上,还有一堆概念叫做软件
在冯诺依曼体系结构中,因为有【存储器】的存在,所以可以把外设的数据预加载到内存当中,然后供CPU进行读取,但是文件中数据非常多,那此时我想提出以下几个问题:
- 既然要预加载,那是要加载哪一部分数据呢?
- 预加载的时候如果内存不够了怎么办?
- CPU在执行对应的数据时,如何快速地找到你预加载的数据?
- 计算机在进行某种计算的时候,是不是把一个任务直接跑完才跑下一个,还是多个任务同时在跑?
- 数据计算完后可以将其重定向到文件当中,在特定的路径下就可以看到所写入的文件内容,可是我们怎么去快速地找到这个文件呢? —— 有目录,但是谁给你维护的这个目录呢?
以上这些工作是无法通过硬件来完成的,而是要通过---软件(操作系统)---来完成
💦操作系统的概念理解
【概念】:操作系统是系统最基本最核心的软件,属于系统软件的组成部分,用于控制和管理整个计算机的硬件和软件资源
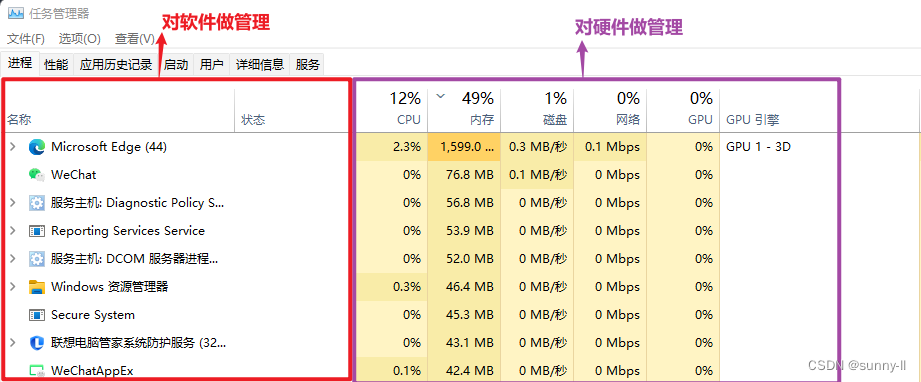
此时我们先简单的了解以下操作系统是个什么?
后续详细讲解操作系统的功能。
操作系统包括:
- 内核 Kernel(操作系统最核心的部分,包含进程管理,内存管理,文件管理,驱动管理等)
- 其他程序(例如函数库,shell 程序等等)
💦操作系统设计的目的与定位
那此时就有同学会疑问,操作系统被设计出来的真正用途是什么?
首先来看看下面这张图,是一整个计算机内部的软硬件系统架构【后面系统调用细述】
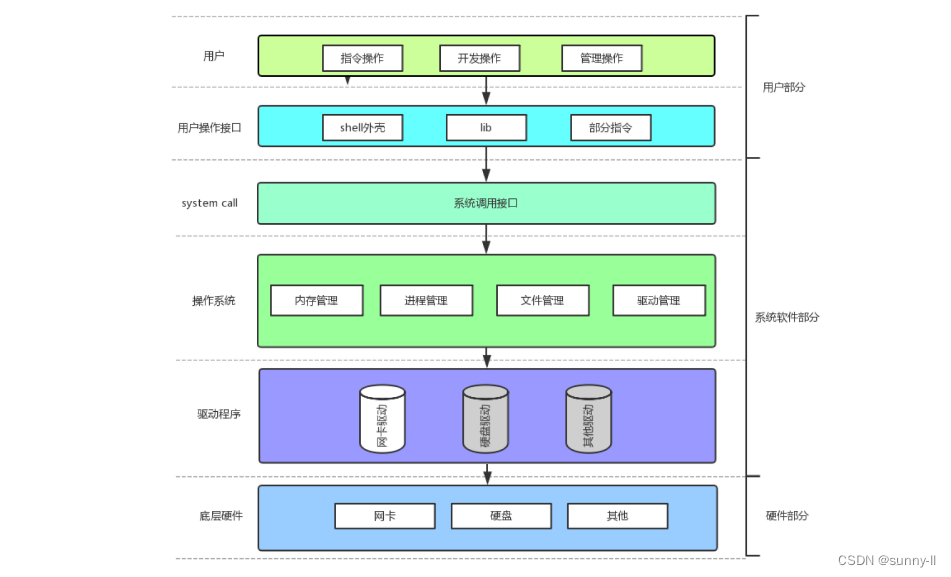
可以明确地看出,【操作系统】是位于整个系统架构的中间层,所以你可以理解它是核心所在,也就是我们常说的
C位,在上面我们也有提到,对于操作系统而言,它可以对上管理软件,对下管理硬件,这就是它被设计出来的目的:
- 与硬件交互,管理所有的软硬件资源
- 为用户程序(应用程序)提供一个良好的执行环境
- 既然它那么重要,那我们就给它一个定位:一款纯正的“搞管理”的软件
💦总结
学习操作系统前,先弄明白三个问题:
【问题一】:操作系统是什么?
- 进行软硬件资源管理的软件。
【问题二】:为什么会存在操作系统?
- 方便用户使用,减少了用户使用计算机的成本。
【问题三】:设计操作系统的目的?
对上,给用户程序(应用程序)提供一个稳定高效的运行环境。
对下,与硬件交互,管理好所有的软硬件资源(充分高效的使用软硬件资源)。
二、操作系统之上之下分别有什么
首先,我们肉眼可见的就是计算机实物,也就是计算机底层的硬件。这些硬件看似是一个个罗列出来的,但实际在底层都遵守冯诺依曼的组织形式。

而单单只有这些硬件是不够的,还需要有一个软件来对这些硬件进行管理。例如,内存何时从输入设备读取数据?读取多少数据?内存何时刷新缓冲区到输出设备?是按行刷新还是全刷新?这些都是由软件进行管理的,而这个软件就是操作系统(Operator System)。
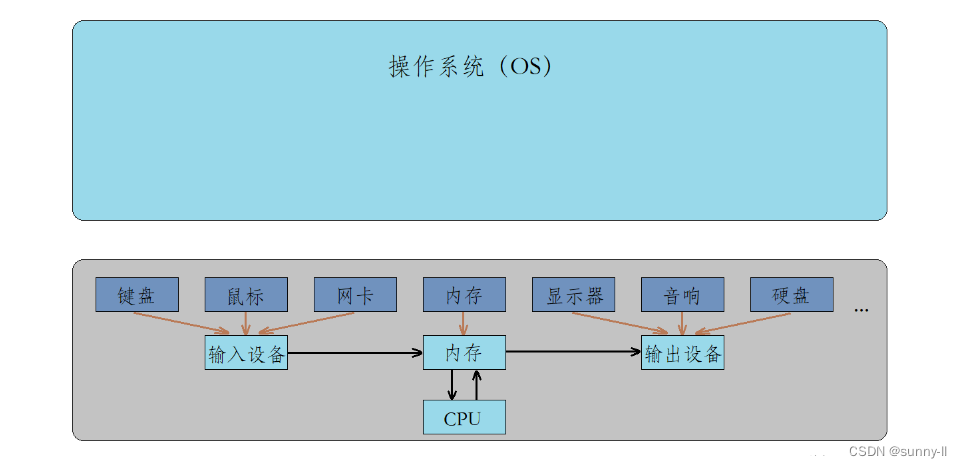
此时这里有一个问题:难道操作系统直接和底层硬件打交道吗?
- 举个例子,如果操作系统自己来完成键盘的读取操作,那么只要你的键盘读取方式进行了改变,那么操作系统的内核源代码就需要进行重新编译,这对操作系统来说维护成本太高了。
- 于是我们又在操作系统与底层硬件之间增加了一层驱动层,驱动层的主要工作就是单独去控制底层硬件的。例如,键盘有键盘驱动,网卡有网卡驱动,硬盘有硬盘驱动,磁盘有磁盘驱动。驱动简单来说就是去访问某个硬件,访问这个硬件的读、写以及硬件当前的状态等等,驱动层就是直接和硬件打交道的。而驱动一般是由硬件制造厂商提供的,或是由操作系统相关的模块进行开发的(例如网卡)。
此时操作系统就只需关心何时读取数据,而不用关心数据是如何读取的了,也就是完成了操作系统与硬件之间的解耦。
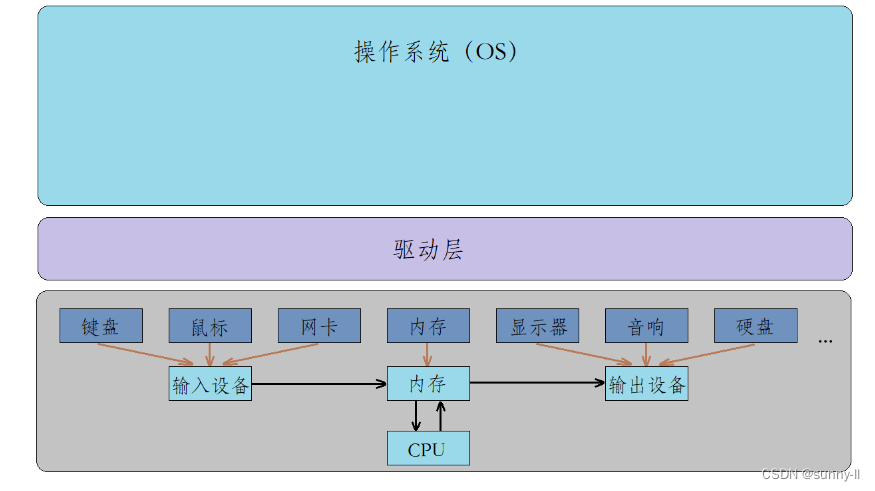
那操作系统究竟管理些什么呢?操作系统主要进行以下四项管理:
- 内存管理:内存分配、内存共享、内存保护以及内存扩张等等。
- 驱动管理:对计算机设备驱动驱动程序的分类、更新、删除等操作。
- 文件管理:文件存储空间的管理、目录管理、文件操作管理以及文件保护等等。
- 进程管理:其工作主要是进程的调度。

而操作系统再往上就是我们所处的位置(用户),在这里我们就可以用命令行或是图形化界面进行各种操作,这一层被称为用户层。

但操作系统为了保护自己,对上只暴露了一些接口,而不会让用户直接访问操作系统,这一系列接口被称为系统调用接口。
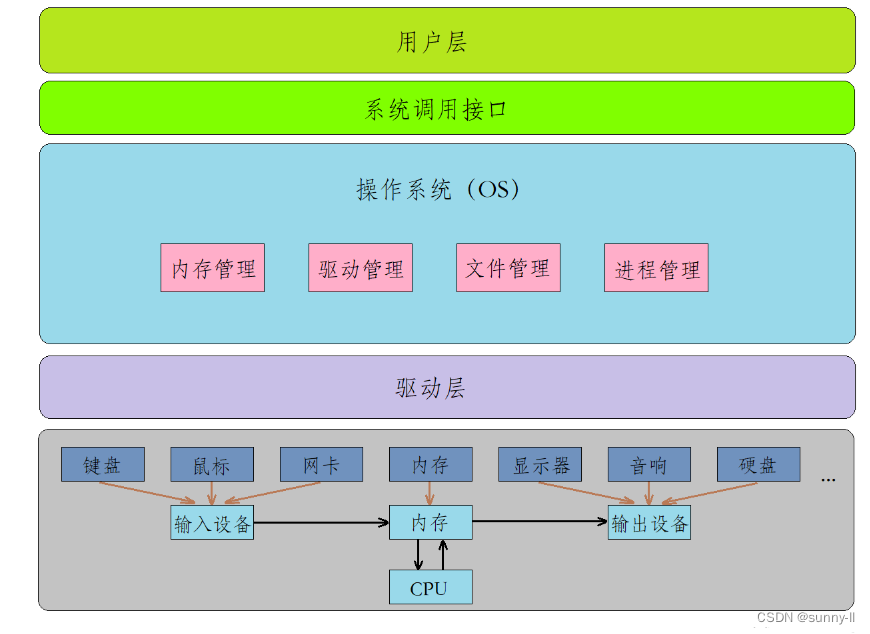
但这些系统调用接口对我们普通用户来说使用成本又太高了,因为要使用系统调用前提条件是你得对系统有一定了解。所以在系统调用接口之上又构建出了一批库,例如libc和libc++。实际上在语言级别上使用的各种库,就是封装了系统调用接口的,我们就是通过调用这些库当中的各种函数(例如printf和scanf)进行各种程序的编写。

至此,我们已经了解了计算机内部的软硬件系统架构和操作系统对上,对下的管理。
三、深度理解操作系统的“管理”
我们在上面已经讲过,操作系统是一款纯正的”搞管理的软件“----对软硬件资源管理的软件。那究竟是怎么”管理“呢?要想学好操作系统,那么就必须正确理解到底什么是管理。本小节讲会通过一些现实的场景案例带读者来进行理解。
💦场景理解
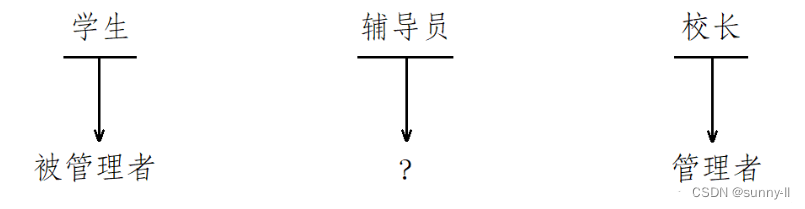
说起管理,如果读者是一个大学生,一定体会过管理和被管理的不同,如果你只是一名普通的学生,也没什么职务,可能你只有被管理的份;但若是你在班里面或者学生会担任一些职务的话,就会了解到管理别人是什么感觉,但你也只能管管学生,放眼学校,比你权利大的人多的是,例如:辅导员、校长
很明显,校长在这三个人当中是管理者,学生是被管理者,那么辅导员充当什么角色呢?
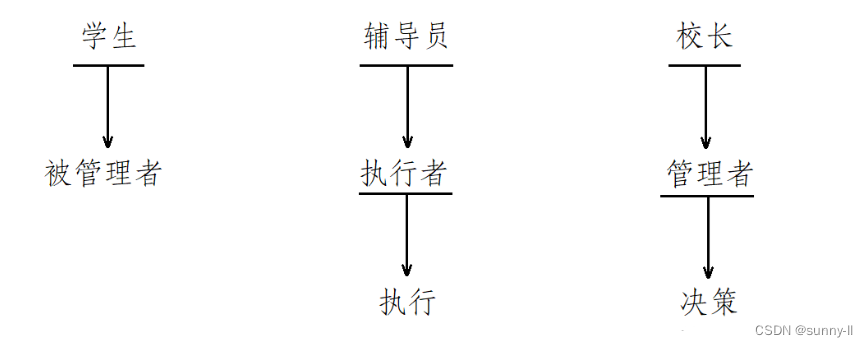
仔细想想,实际上完成任何一件事都要经过两个过程,首先是决定要不要做这件事或是如何做这件事(决策),然后就是去做这件事情(执行)。校长作为管理者来管理学生,校长实际上就是那个做决策的人,但是校长作出决策后并不需要自己来执行,而是让辅导员去执行,所以辅导员的主要任务就是执行管理者的决策,我们通常将其称为执行者。
虽然说校长是管理学生的,但是我们在学校一般情况下是看不到校长本人的,那么校长是如何做到在不看到我们的情况下对我们进行管理的呢?
举个例子,现在校长要求辅导员将计算机成绩排名前十的学生的各科资料以及平时表现记录拿过来,他将从这十名同学之中选出三名学生参加本次的编程大赛,当辅导员将资料拿来后校长选出三名学生说:“就这三个了,你找个老师对这三名学生进行一下强化训练,然后参加本次的编程大赛。”然后校长就什么也不管了。
在这个过程中,校长根本没有见过这三名同学,就对其进行了管理,他根据的是什么?没错,他根据的是数据。
实际上,学校将我们每个学生的各种信息都进行了管理,基本信息、成绩信息以及健康信息等等。
每这么一套信息就描述了一名学生,校长通过对这些信息的管理就能做到对学生的管理。这么一套信息在C语言当中我们称之为抽象结构体,而在C++当中又叫做面向对象(先对众多信息进行描述)。
当学生的数量多起来了,校长就可以将全部学生的信息组织起来,当然组织的方式有很多种(链表、顺序表、树),而每种组织方式都有其自己的优势,于是就有了一门课程专门教我们管理数据的方式,那就是数据结构。这里我们假设校长以双链表的形式将学生的信息组织起来。
此时校长对各个学生的管理,实际上就变成了对这个双链表的增删查改。当有新生时直接向该双链表加入一个结点,当学生毕业后直接将学生信息从该双链表当中移除即可。
总结一下:管理者管理被管理者,实际上是先将被管理者的各种信息进行描述,然后再将多个被管理者的描述信息根据某种数据结构组织起来,最后管理者管理被管理者实际上就是对数据结构的管理。
👉一句话,管理的本质就是:先描述,再组织👈


⭐得出结论:
- 管理者和被管理者,其实是不需要直接沟通的!
- 管理的意义:对被管理对象的数据做管理!!
- 管理的本质:👉一句话,管理的本质就是:先描述,再组织👈
✨小结:
- 本节我们主要理解的是操作系统如何对软硬件做管理,那它是怎么做管理的呢?其实归纳起来就是我们上面所说六个字:先描述,再组织。那对于硬件来说,其实和我们所描述的学生是同一个道理,也有它自己的属性,比如说这个硬件的名称是什么、编号是什么、归类是什么、状态是什么,我们使用最基础的【C语言】就可以去描述这些属性,构成一个个的结点,使用【数据结构】就可以将这些离散的结点组织起来,更好地做数据的管理和修改,即我们上面对学生信息的管理变成了对链表的增删查改
- 因此对于上面这一系列的过程,
描述的过程就是【面向对象】的封装过程,组织的过程就是【数据结构】的操作过程。所以为什么我们要学习语言呢?为什么我们要学习数据结构呢?本质上我们未来所写的软件或多或少都和管理有关- 所以语言帮我们完成描述的过程,数据结构帮我们完成组织的过程,只有理解了先描述再组织,才能理解管理的本质,进而去理解操作系统;换言之,想要理解操作系统,就必须得懂语言和数据结构!
💦操作系统(OS) 的“管理”
✨操作系统如何进行管理?
🍎向下对硬件做管理
上面说了这么半天,继续回归我们开头所讲的校长、辅导员、学生,我们便可以重新去定义一下它们之间的关系
-
校长【发布决策】 ⇒ 操作系统
-
辅导员【执行决策】 ⇒ 硬件驱动
-
学生【参与执行】 ⇒ 硬件

- 对于操作系统和硬件我们上面都有提到过了,不过这里的硬件驱动可能有些读者不太明白,我来讲一讲这个
一般我们每一种硬件设备都会为其配置一个驱动程序,鼠标、键盘、网卡、声卡、显卡都具备驱动程序
那有了这些驱动程序后,操作系统就可以管理到下面的硬件了,就和校长有了辅导员之后便很好地对学生做管理一样。首先它会通过各种驱动程序对各种硬件的信息做提取,然后将这些信息全部抽象,面向对象式地将其封装为一个结构体或者类,然后填充设备结构体,构造设备结点,然后将这些结点以某种数据结构管理起来,然后对操作系统对设备的管理就转换为了对链表的增删查改

🍐向上对用户提供服务
- 计算机的底层有相应的硬件和驱动程序,操作系统内核对下可以管理好软硬件,同样也要管理进程。并且可以对外提供服务。
- 操作系统并不相信任何的用户,它不会将自己任何的数据结构、代码逻辑……直接暴露给用户,为的是防止用户恶意修改操作系统,所以操作系统是通过系统调用的方式,对外提供接口服务!类似于银行的工作人员提供一个一个小的窗口来给我们服务。Linux操作系统是用C语言写的,这里所谓的“接口”,本质就是C函数!。我们学习系统编程,本质就是在学习这里的系统接口。
- 系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库(用户操作接口),有了库,就很有利于更上层用户或者开发者进行二次开发。
✨操作系统管理的目的
在上一小节中我们谈论到的都是操作系统对下,也就是对硬件的管理,那一开始我有说起过它是一个对软硬件资源进行管理的软件,但是为什么要对它们进行管理呢?就像校长为什么要管理好我们呢?本小节来谈谈这个话题
- 要知道,对于一款操作系统来说,它的生态取决于它的使用人数,如果使用它的人多了,那么它自己也就会被广泛地使用起来,就像Linux一样,因为有其开源社区的存在,它是一块开源的OS,而且安全、可靠,所以使用的人才会这么多,不过这也要取决于用户是否用得舒心
- 为什么这么说呢?加个比方,有一天你下课了准备回宿舍打开电脑玩原神,怪打得好好的,但是电脑五分钟黑屏一次,八分钟蓝屏一次,那你的使用体验感一定不会很好。此时你一定会选择重装系统或者干脆换一个系统
因此操作系统必须管理好当前机子的软硬件,给用户一个良好的体验感才可以留住用户
【总结一下】:
- 操作系统通过对下管理好软硬件资源,这是它的手段;对上给用户提供 安全、稳定、高效、功能丰富 的执行环境,让用户有一个最佳体验,这就是目的!
四、共勉
以下就是我对【Linux系统编程】操作系统的理解,如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对【Linux系统编程】进程的理解,请持续关注我哦!!! 