集运网站建设西安网络公司

什么是 Blinko ?
Blinko是一个创新的开源项目,专为想要快速捕捉和整理瞬间想法的个人而设计。Blinko允许用户在灵感迸发的瞬间无缝记录想法,确保不会错过任何创意火花。
Blinko 的设计初衷是让笔记记录变得更简单,让用户专注于内容本身,而不会被繁琐的管理任务所困扰。Blinko 帮助用户轻松捕捉和管理他们的想法,设计上分为两个核心部分:“闪念” 和 “笔记” 。
“闪念” 专为记录灵光一闪而打造,用户无需担心格式或复杂操作,即可即刻记下即兴想法。这些记录可设置为每隔一段时间自动清除,确保内容不会过度堆积,从而保持该部分的整洁和高效。
“笔记” 部分提供了更有条理的管理系统,用户可以使用标签对笔记进行分类,并利用批量操作轻松地组织和分类大量笔记。
🚀主要功能:
-
AI 增强的笔记检索 🤖:借助
Blinko的先进AI驱动的RAG(检索增强生成)技术,您可以使用自然语言查询快速搜索和访问您的笔记,轻松找到所需内容。 -
数据拥有权 🔒:您的隐私至关重要。所有笔记和数据都安全存储在您自托管的环境中,确保您对信息的完全控制。
-
高效快速 🚀:即时捕捉想法,并以纯文本形式存储,方便访问,完全支持
Markdown格式,便于快速格式化和无缝共享。 -
轻量架构,强大性能 💡:基于
Next.js构建,Blinko提供流畅、轻量的架构,具备强大的性能,同时不牺牲速度或效率。 -
开放协作 🔓:作为一个开源项目,
Blinko欢迎社区的贡献。所有代码透明且可在GitHub上获取,促进合作精神和持续改进。 -
完全免费 🎉:
Blinko是且将始终是免费的,没有隐藏费用或锁定在付费墙后的高级功能。
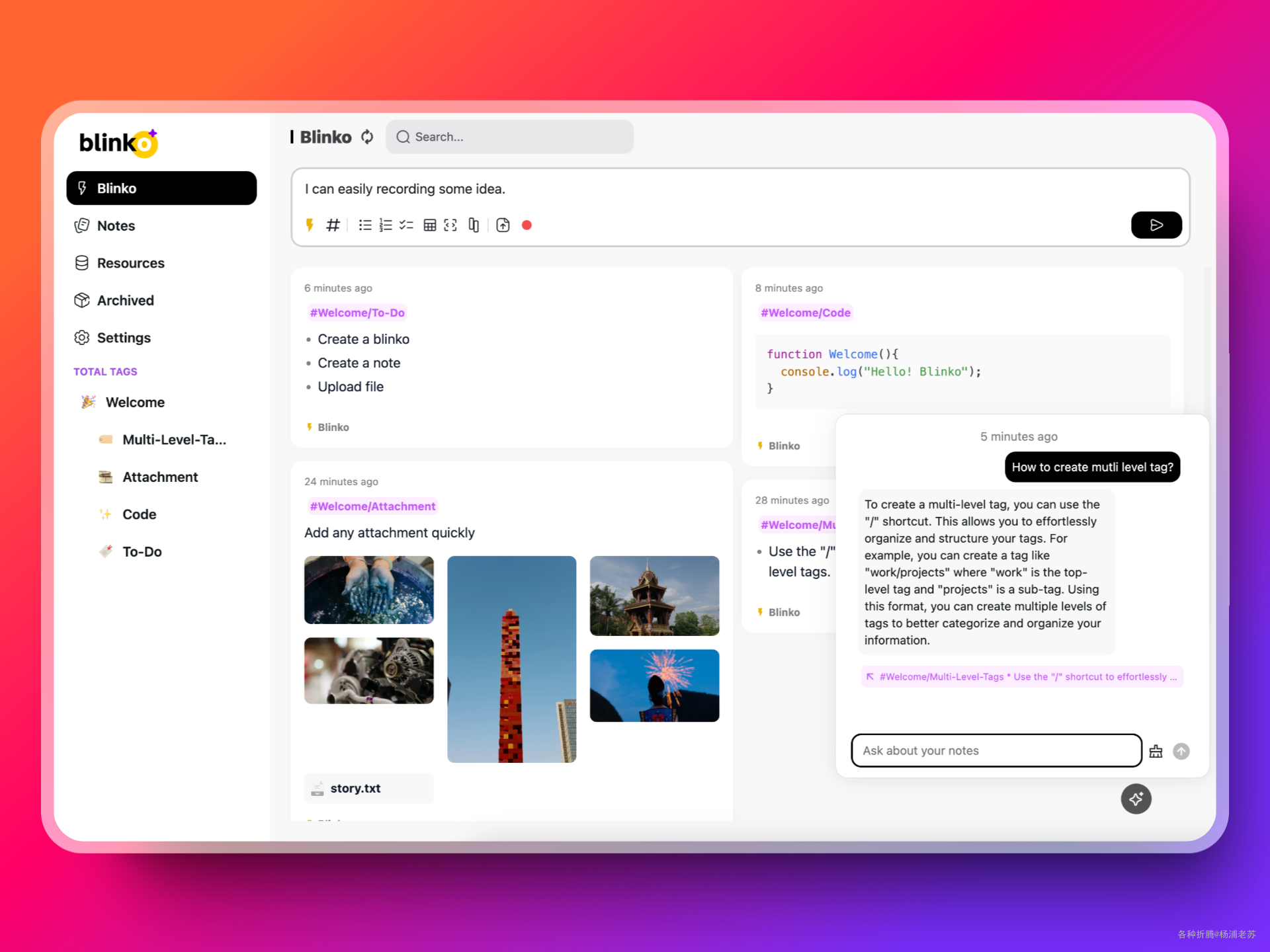
如果不想安装,可以去看看官方的 Live Demo
- 地址:https://blinko-demo.vercel.app
- 账号:
blinko - 密码:
blinko
安装
在群晖上以 Docker 方式安装。
本文写作时,
latest版本对应为0.0.26;
采用 docker-compose 安装,将下面的内容保存为 docker-compose.yml 文件
version: '3'services:blinko-website:image: blinkospace/blinko:latestcontainer_name: blinko-website# restart: unless-stoppedenvironment:NODE_ENV: production# NEXTAUTH_URL: http://localhost:1111# NEXT_PUBLIC_BASE_URL: http://localhost:1111NEXTAUTH_SECRET: my_ultra_secure_nextauth_secretDATABASE_URL: postgresql://postgres:mysecretpassword@postgres:5432/postgresdepends_on:postgres:condition: service_healthy# Make sure you have enough permissions.volumes:- ./data:/app/.blinko restart: alwayslogging:options:max-size: "10m"max-file: "3"ports:- 1111:1111healthcheck:test: ["CMD", "curl", "-f", "http://localhost:1111/"]interval: 30s timeout: 10s retries: 5 start_period: 30s postgres:image: postgres:14container_name: blinko-postgresrestart: always# ports:# - 5435:5432volumes: - ./db:/var/lib/postgresql/dataenvironment:POSTGRES_DB: postgresPOSTGRES_USER: postgresPOSTGRES_PASSWORD: mysecretpasswordTZ: Asia/Shanghaihealthcheck:test:["CMD", "pg_isready", "-U", "postgres", "-d", "postgres"]interval: 5stimeout: 10sretries: 5
- 容器
blinko-postgres的环境变量
| 可变 | 值 |
|---|---|
POSTGRES_DB | 指定要创建的数据库名称 |
POSTGRES_USER | 定义 PostgreSQL 数据库的用户名 |
POSTGRES_PASSWORD | 设置用于连接 PostgreSQL 数据库的密码 |
TZ | 设置时区 |
- 容器
blinko-website的环境变量
| 可变 | 值 |
|---|---|
NODE_ENV | 设置 Node.js 的运行环境。通常设为 production 用于生产环境 |
NEXTAUTH_URL | 指定 NextAuth.js 的回调 URL,用于处理身份验证。在生产环境中应更改为实际域名 |
NEXT_PUBLIC_BASE_URL | 公开的基础 URL,客户端可以访问,用于构建 API 请求的基础路径。在生产环境中也应设置为实际域名 |
NEXTAUTH_SECRET | 设置用于加密会话和生成 JWT 的秘密字符串 |
DATABASE_URL | 定义数据库连接字符串,用于连接 PostgreSQL 数据库。格式为 postgresql://用户名:密码@主机:端口/数据库名 |
然后执行下面的命令
# 新建文件夹 blinko 和 子目录
mkdir -p /volume1/docker/blinko/{data,db}# 进入 blinko 目录
cd /volume1/docker/blinko# 将 docker-compose.yml 放入当前目录# 一键启动
docker-compose up -d
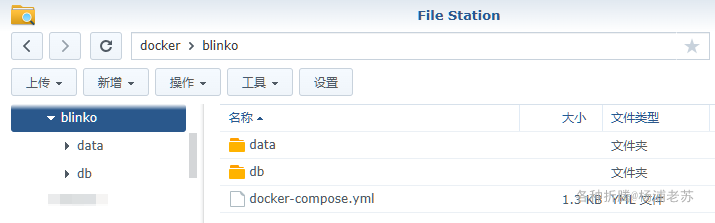
运行
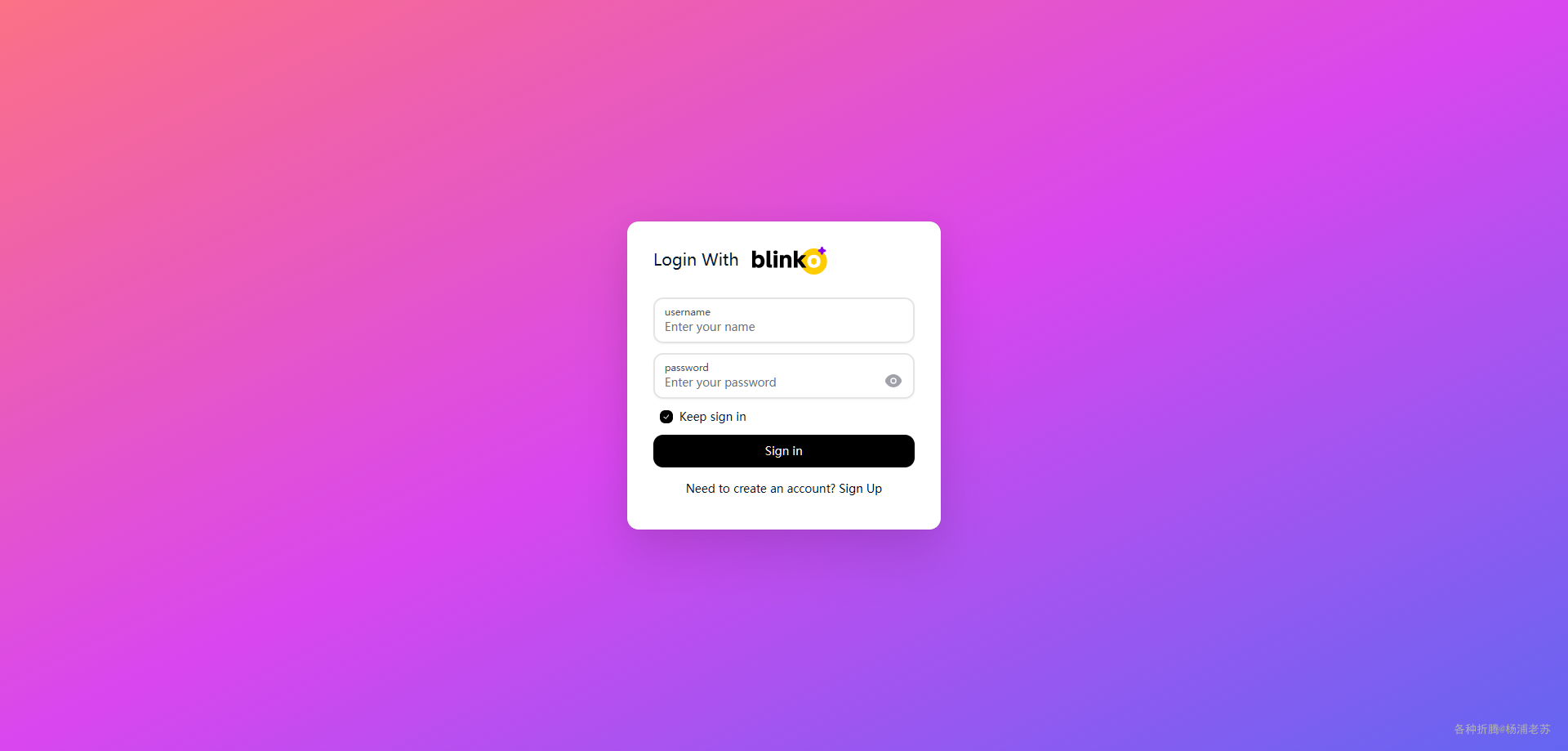
在浏览器中输入 http://群晖IP:1111 就能看到登录界面
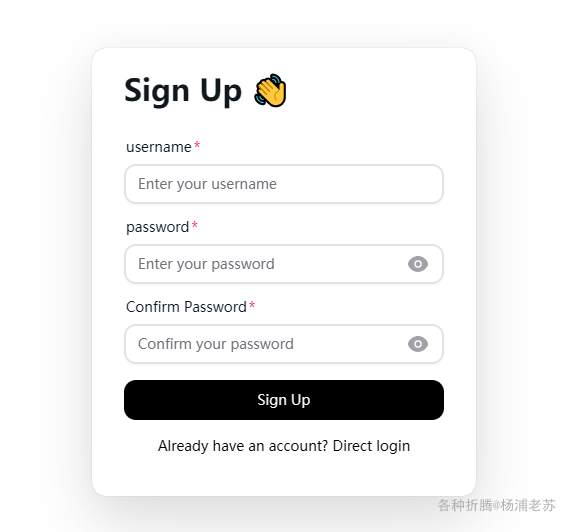
第一次需要点 Sign Up 注册账号
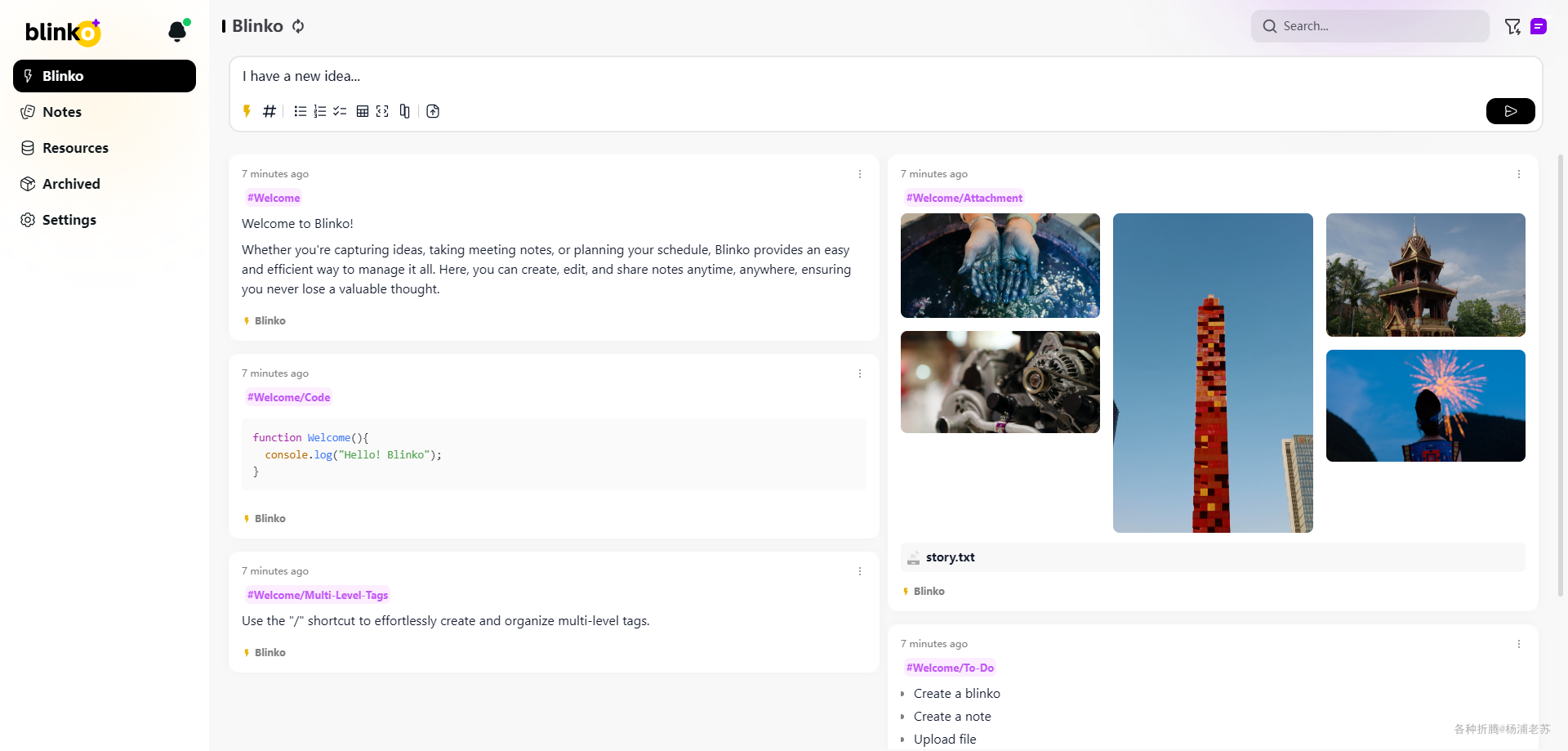
登录成功后的主界面
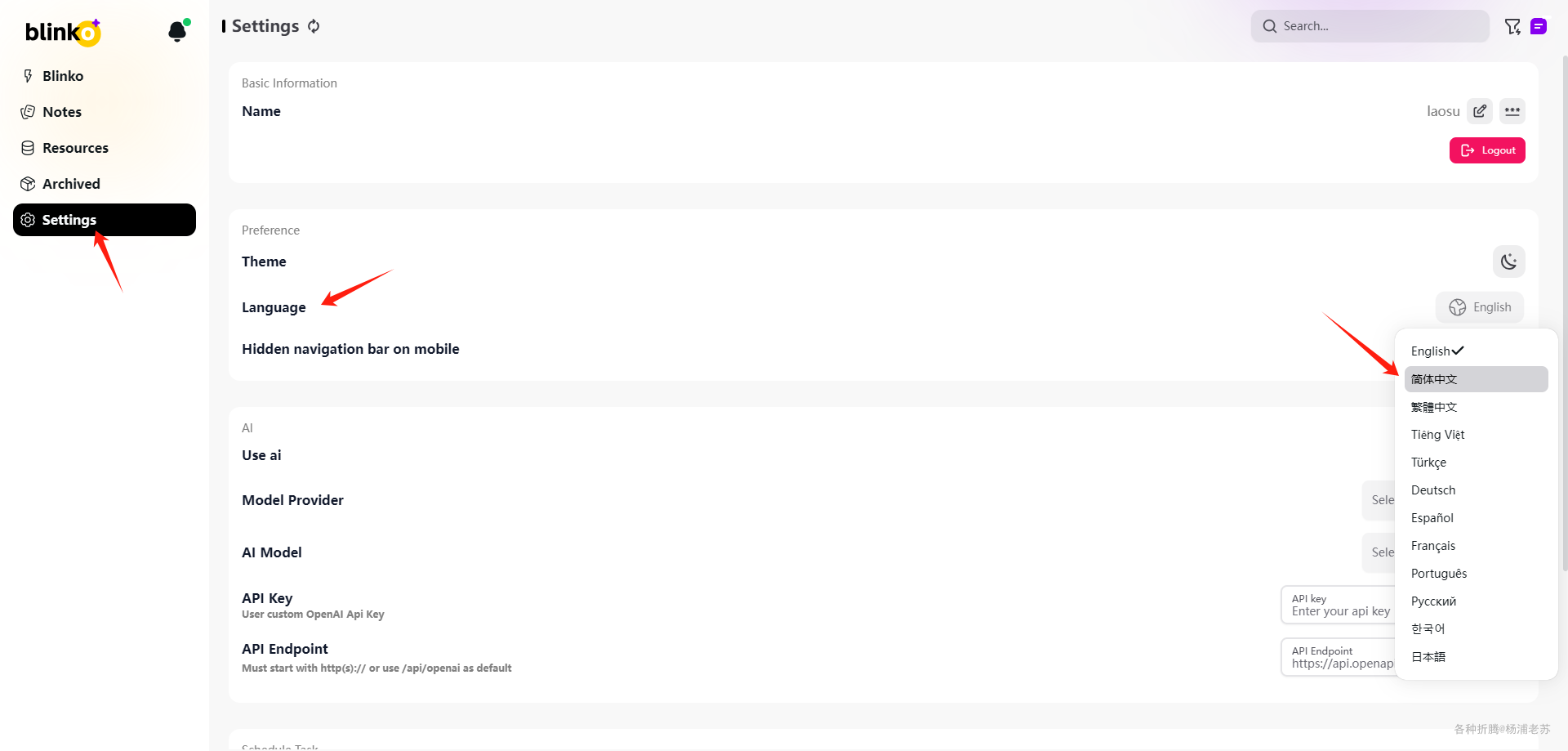
设置中文
Settings --> Language 中找到 简体中文
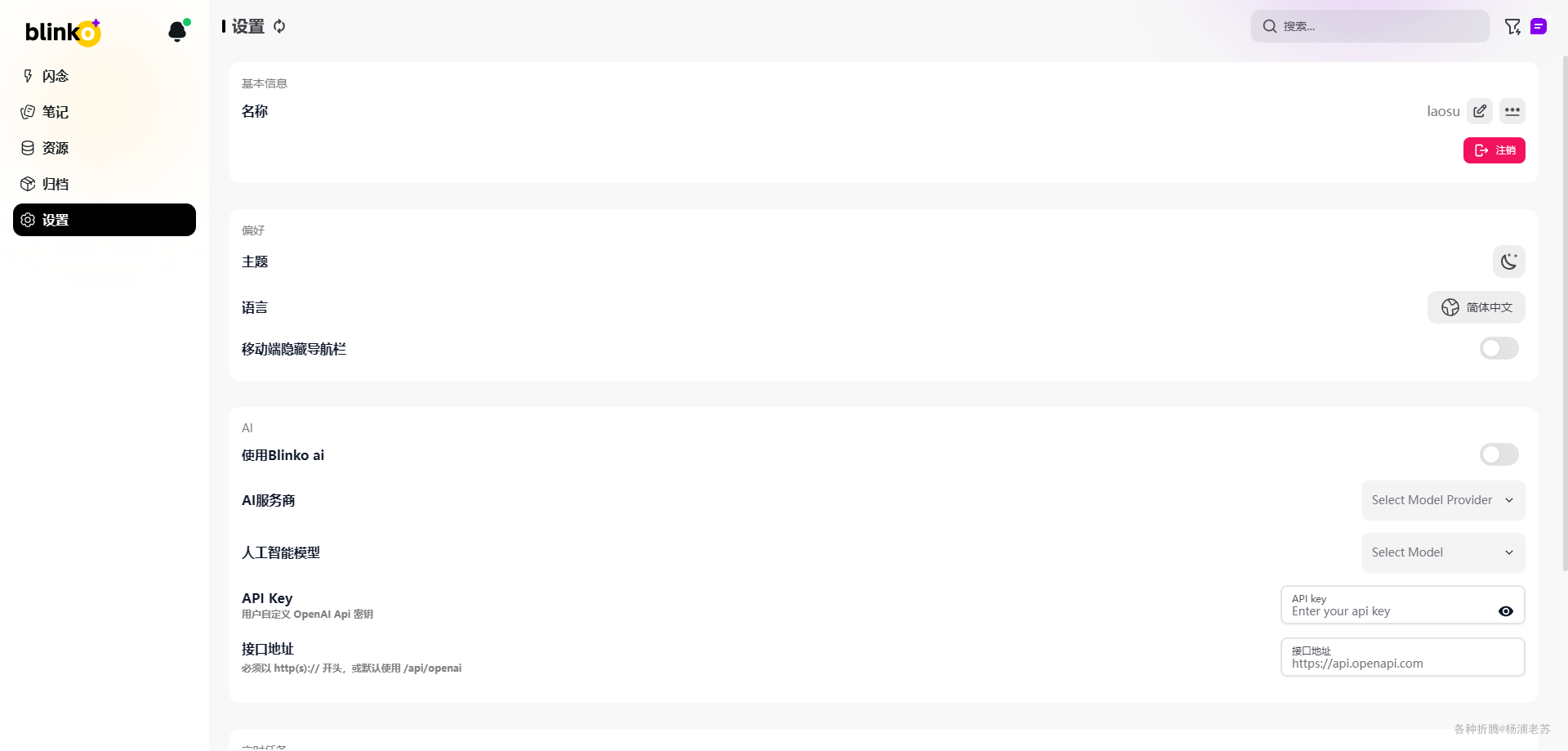
不需要刷新
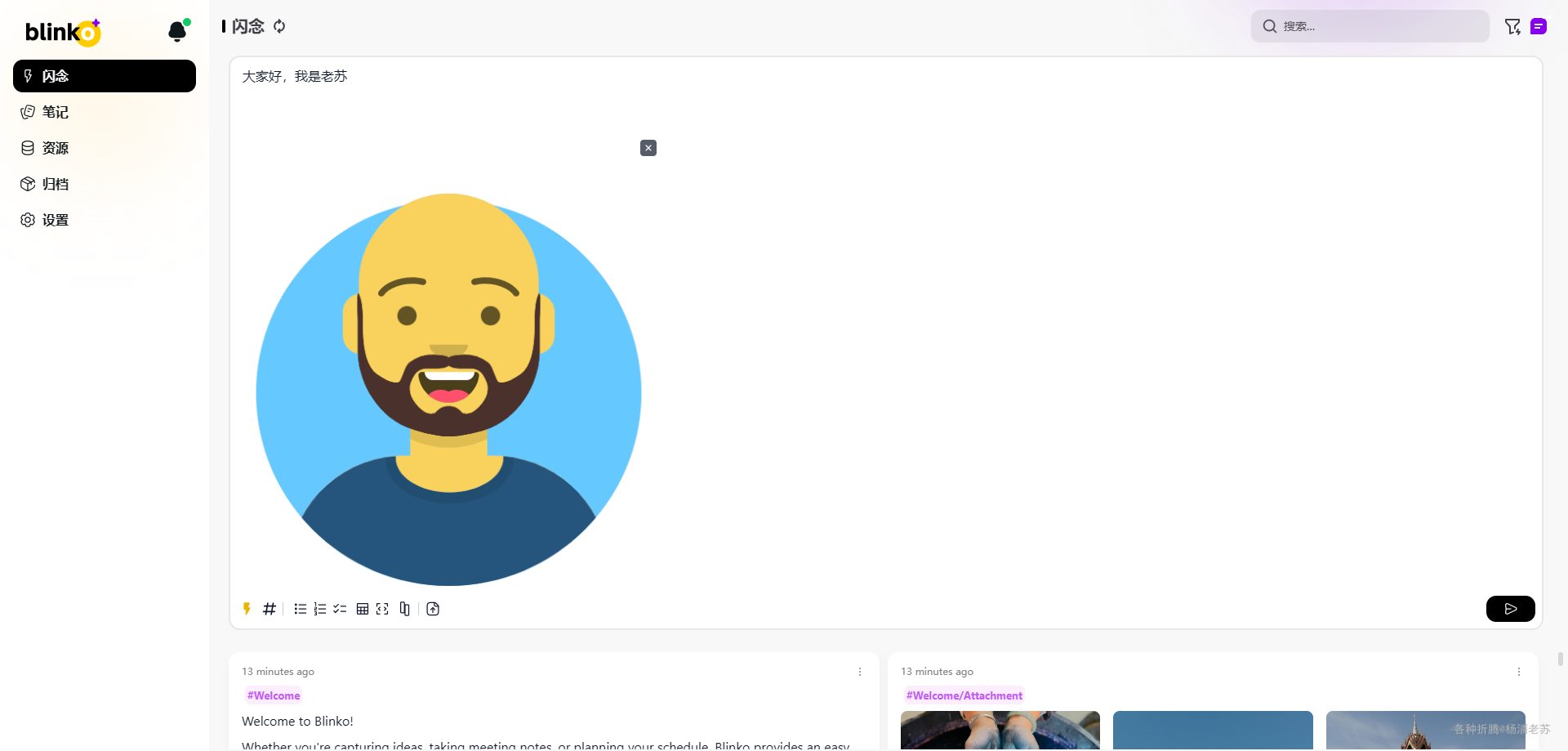
现在回到 闪念,可以开始记录你的新想法
链接能够直接提取 title 等信息
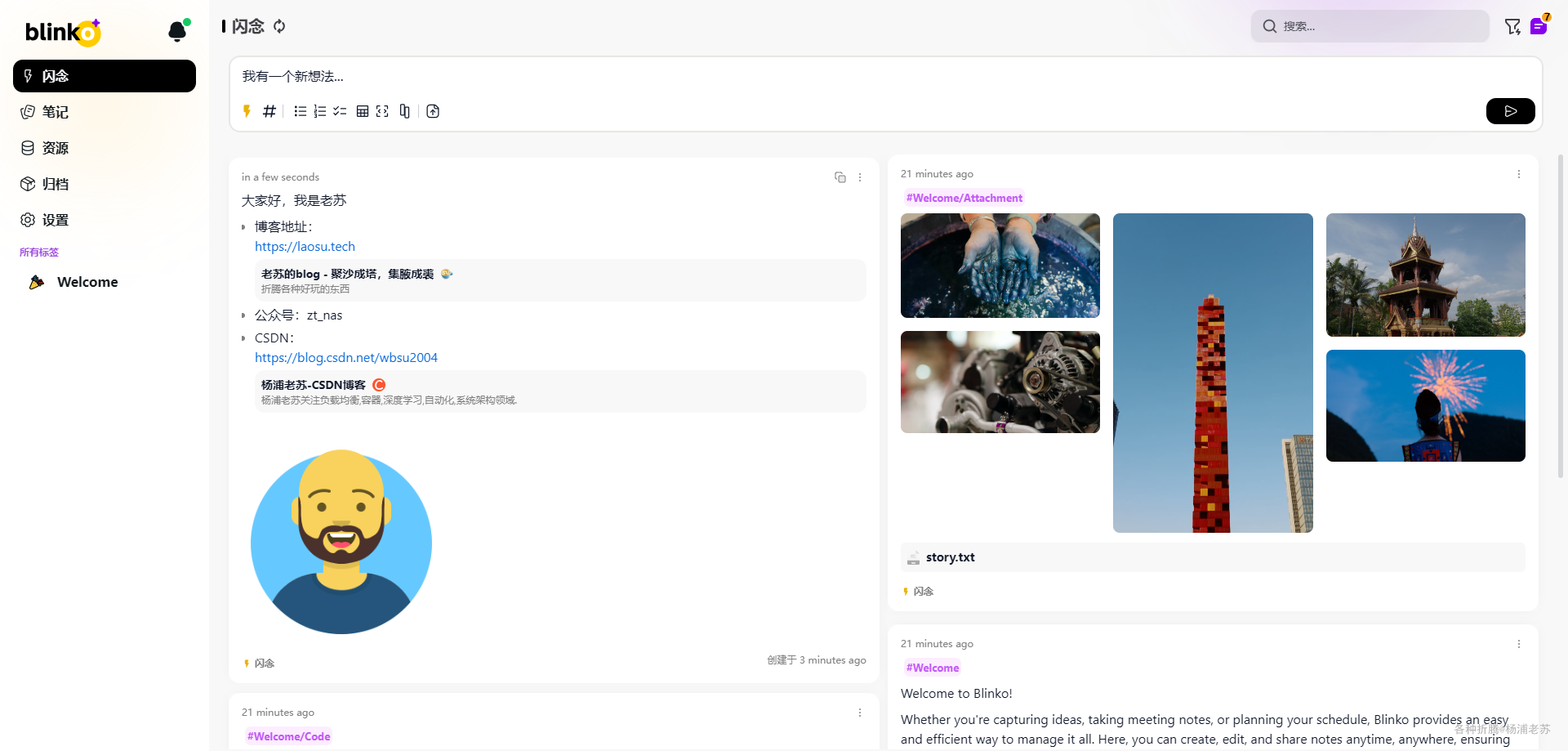
支持右键菜单
手机上的效果相当哇塞
AI 驱动(失败)
默认情况下,AI 并没有启用
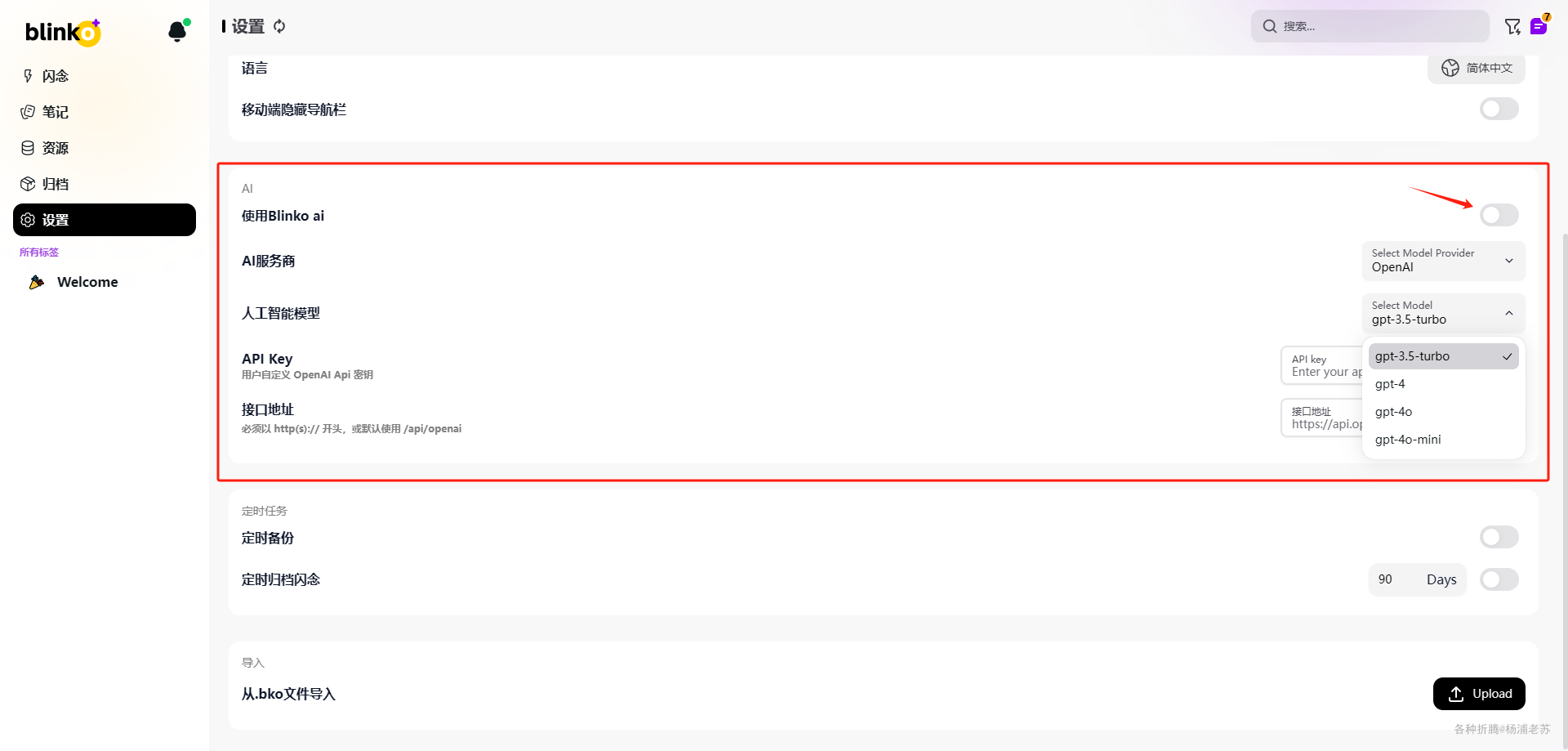
虽然 AI服务商 只能是 OpenAI,但因为可以输入 接口地址,所以老苏打算用其他的 AI 来模拟 OpenAI
文章传送门:
- 长文本大模型API服务kimi-free-api
- 大模型接口管理和分发系统One API
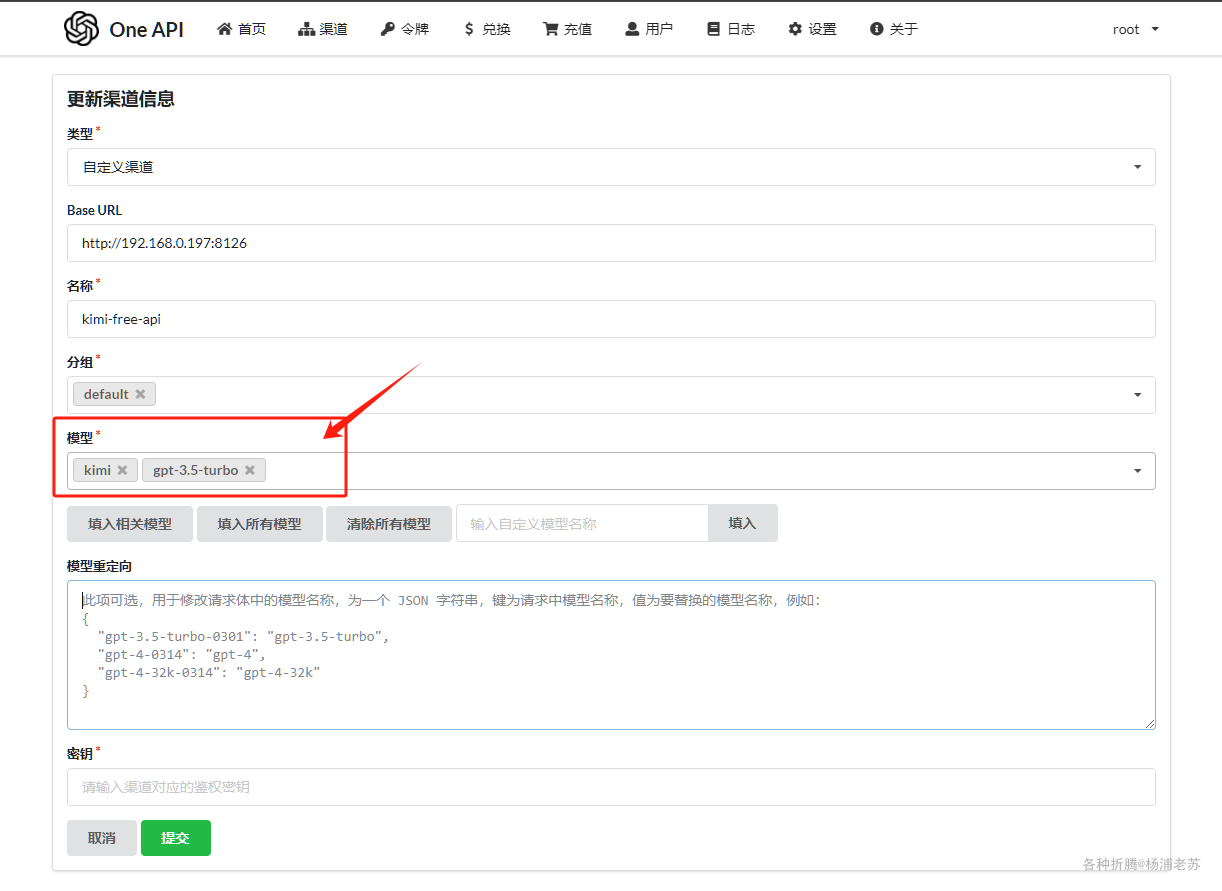
- 使用
Blinko ai:启用; AI服务商:只能选OpenAI;人工智能模型:选择gpt-3.5-turbo,因为One API中模型只设置了kimi和gpt-3.5-turbo;API Key:用One API的令牌;- 接口地址:用
One API的地址;但是要注意,要求必须用https开头,格式为https://域名/v1;
设置完成后
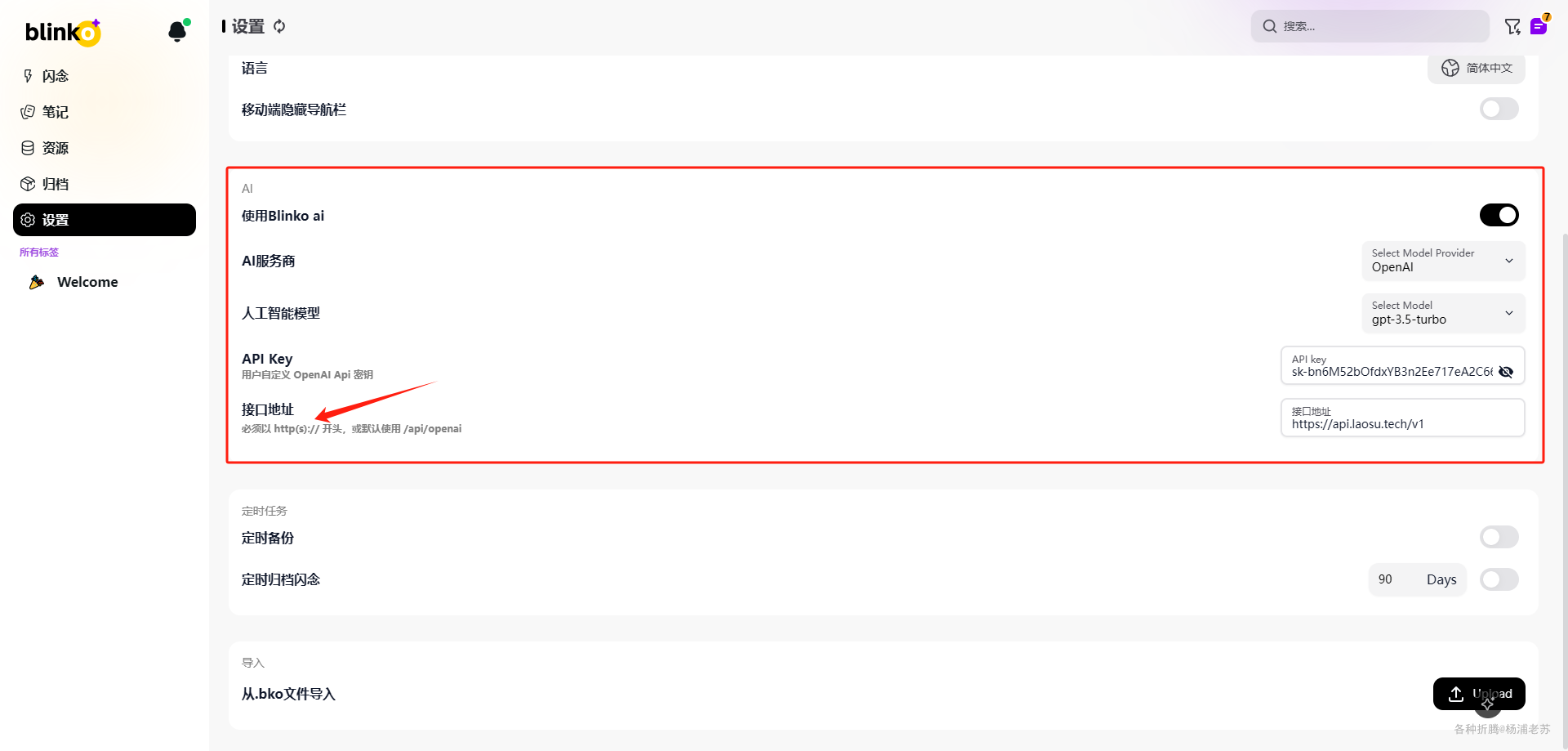
回到首界面,右下角会多出一个图标
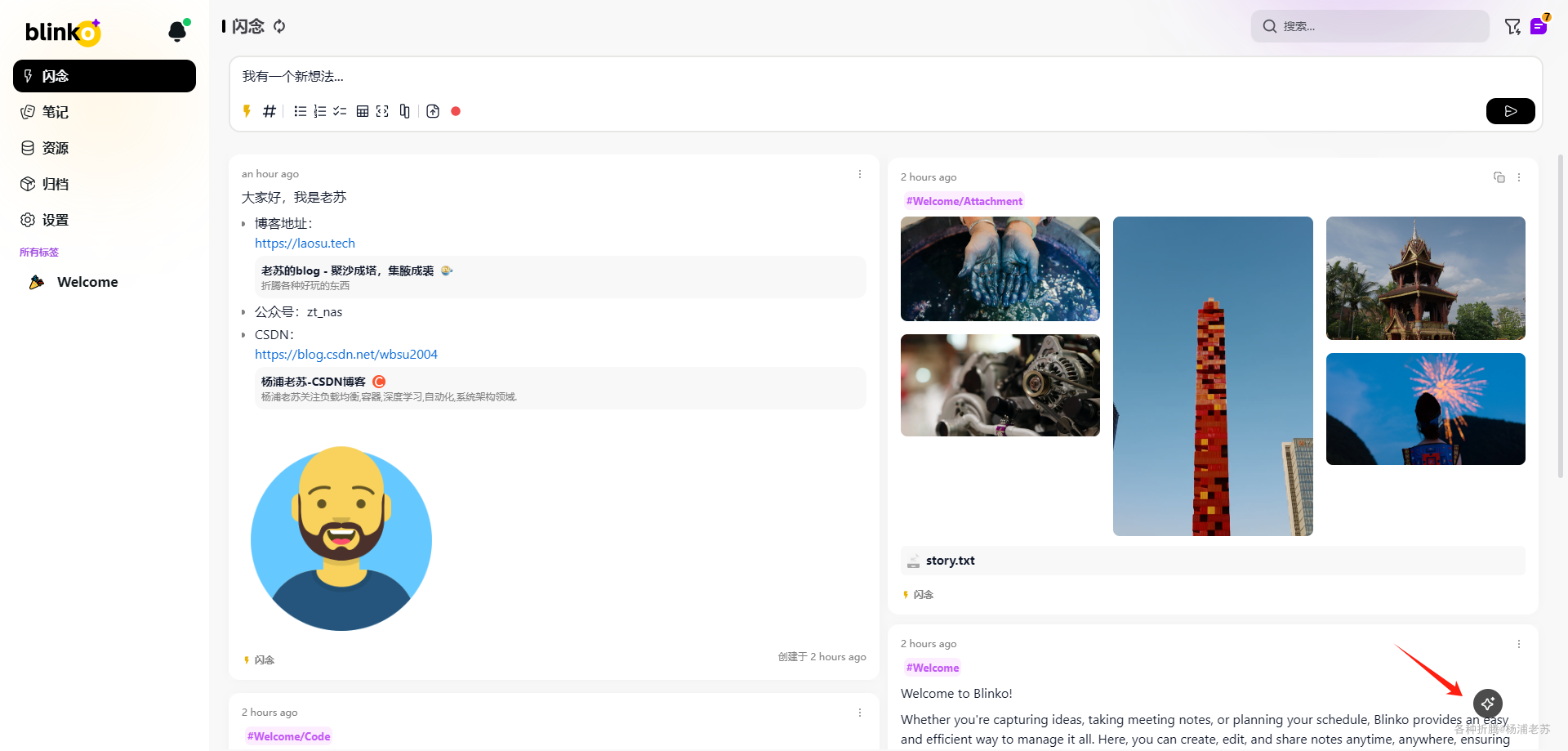
但是聊天时,返回了错误
Error: Error: Error: 503 当前分组 default 下对于模型 text-embedding-ada-002 无可用渠道 (request id: 2024111016093058572008963658571)
说明还需要用到 Embedding 模型。继续用 M3E 来模拟 text-embedding-ada-002
文章传送门:开源文本嵌入模型M3E
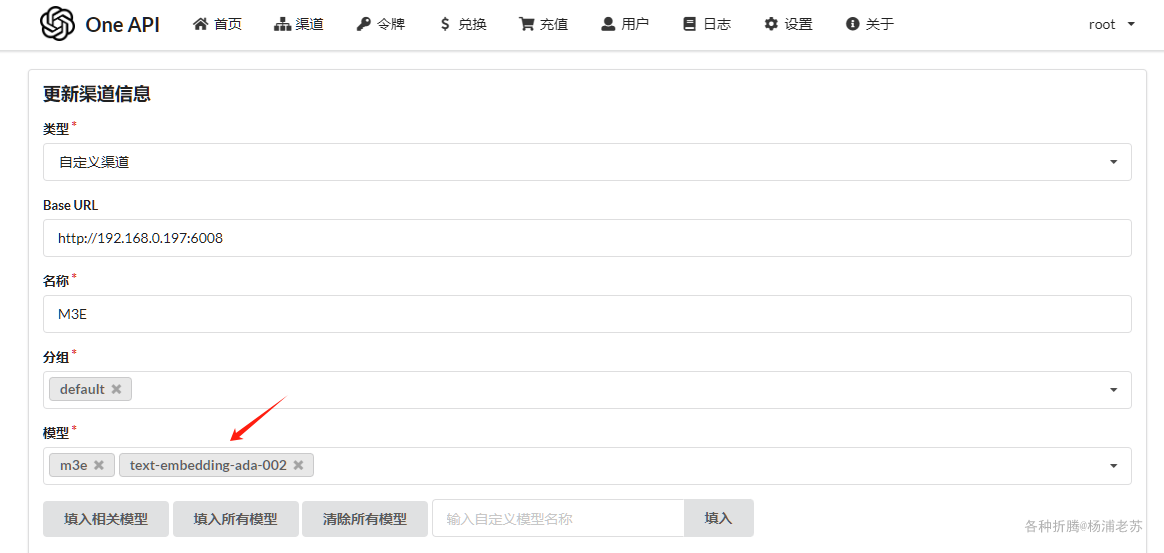
这次返回了另一个错误
Error: Error: 422 bad response status code 422 (request id: 2024111017481662117653978385149)
M3E 容器中的日志更明确
172.17.0.1:33778 - "POST /v1/embeddings HTTP/1.1" 422 Unprocessable Entity
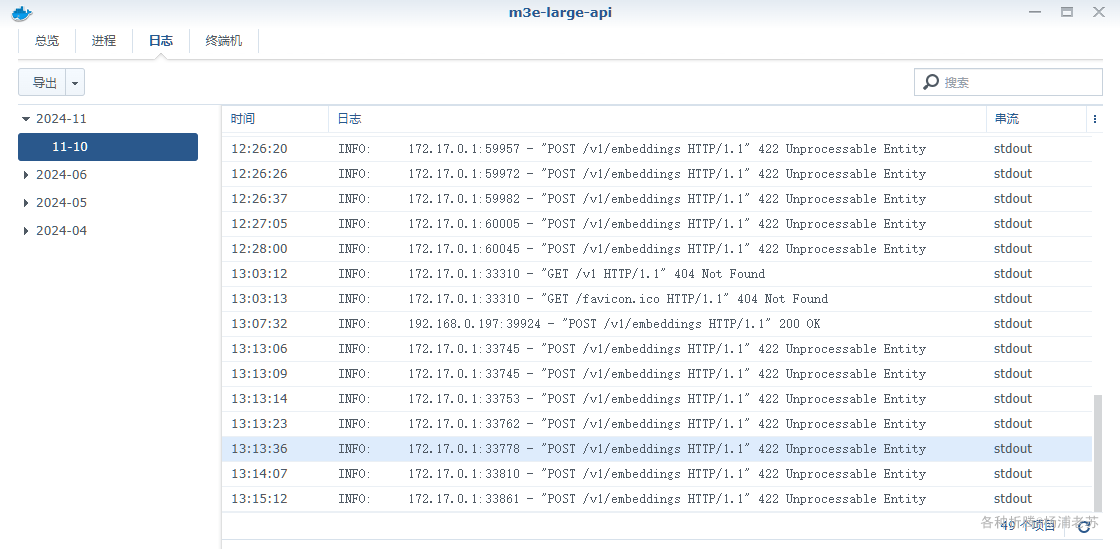
说明请求的格式正确,但是由于含有语义错误,无法响应。看来虽然都是嵌入式模型,但两者存在差异。
暂时没想到怎么解决这个问题,或者等待作者支持其他的 AI模型吧。
即便暂时用不上 AI 搜索,Blinko 从设计理念上,也不失为一款很好的轻量级笔记软件。
参考文档
blinko-space/blinko: An open-source, self-hosted personal note tool prioritizing privacy, built using TypeScript .
地址:https://github.com/blinko-space/blinko
Blinko HomePage
地址:https://blinko-doc.vercel.app/
Blinko live demo
地址:https://blinko-demo.vercel.app