哪些网站可以做免费推广网站怎么做边框
1. 简介
状态栏 StatusStrip,默认在软件的最下方,用于显示系统时间、版本、进度条、账号、角色信息、操作位置信息等

可以在状态栏中添加的控件类型有:StatusLabel、ProgressBar、DropDownButton、SplitButton
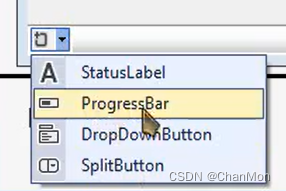
2. 属性
| 属性 | 解释 |
|---|---|
| (Name) | 控件ID,在代码里引用的时候会用到 |
| Enabled | 控件是否启用 |
| Dock | 定义要绑定到容器的控件边框,默认是bottom |
| Items | 项的集合,可以添加的项的类型有:StatusLabel、ProgressBar、DropDownButton、SplitButton 这些项的属性和ToolStrip类似:ToolStrip 工具栏 |
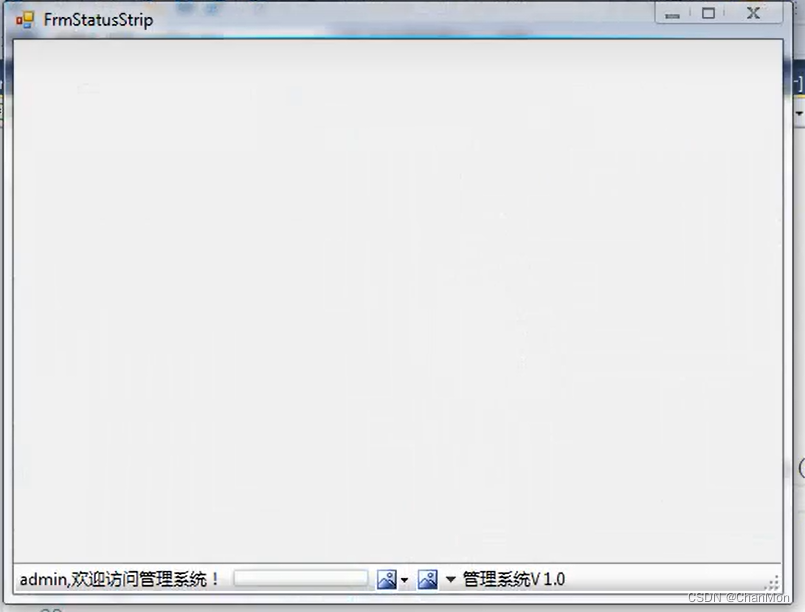
3. 示例
- 往窗体界面拖一个状态栏控件
- 往状态栏控件中拖一个StatusLabel1、一个ProgressBar、一个DropDownButton、一个SplitButton、一个StatusLabel2
- 在加载窗体的时候设置 StatusLabel1 的内容 和 StatusLabel2 的内容

- 运行
参考:2023年C#之WinForm零基础教程50讲