不同网站模块分析红色网站建设的作用和意义

👏作者简介:大家好,我是爱发博客的嗯哼,爱好Java的小菜鸟
🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
📝社区论坛:希望大家能加入社区共同进步
🧑💼个人博客:智慧笔记
📕系列专栏:Redis
文章目录
- 前言
- 一、问题前引
- 二、缓存穿透
- 1. 问题描述
- 2. 问题解决
- 2.1 缓存空数据
- 2.2 布隆过滤器
- 三、缓存击穿
- 1. 问题描述
- 2. 问题解决
- 2.1 设置逻辑过期
- 2.2 设置互斥锁
- 四、缓存雪崩
- 1. 问题描述
- 2. 问题解决
- 2.1 设置随机过期时间
- 2.2 缓存高可用
- 总结
- 结语
前言
一聊到redis,必不可少的就是缓存三兄弟的问题,即缓存穿透、缓存击穿和缓存雪崩,这三个问题在业务场景中相对来说比较常见的,也是比较基础的三种问题。那么这三种问题是如何引起的,并且应该如何解决,就是本章探讨的话题。
一、问题前引
大家都知道,Redis一般搭配MySQL来使用,来充当缓存处理一些业务数据。但为什么要Redis用来充当缓存呢,不能直接使用MySQL吗?
当然是可以的,但是对于一些请求量大并发次数高的场景就有问题了。
MySQL是基于磁盘的,请求查询速度偏慢,所以就需要一个基于内存的速度快的工具来缓存这些数据,Redis就应运而生了。而且当大量请求到来时,只有MySQL的话,有可能承受不住大量请求导致MySQL宕机,此时就会影响到整个服务器,所以Redis此时又充当了一个保护缓冲的作用。
二、缓存穿透
1. 问题描述
缓存穿透主要体现在穿透两个字上,穿透即为穿过缓存,打到数据库上。
当一个请求访问的时候,此时Redis没有缓存该数据,然后去数据库查询该数据也查询到,说明没有该数据。
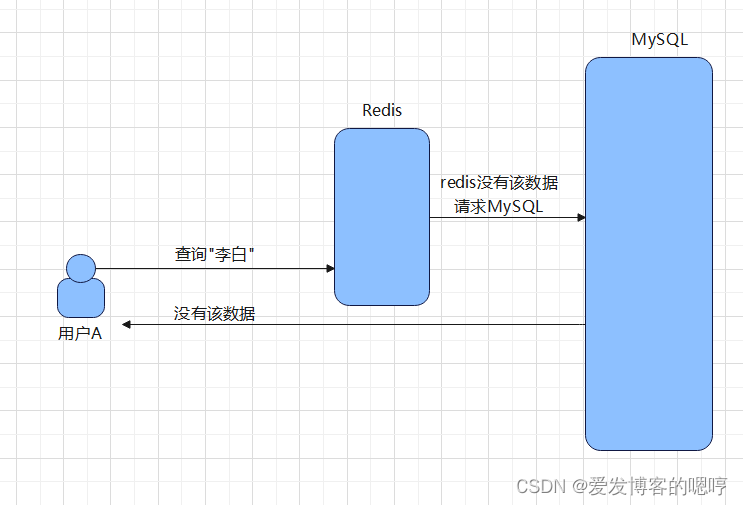
此时你或许还不以为然,不就一个空数据吗?多稀罕啊。
但如果该请求是恶意请求,此时无数条请求同时访问,缓存中没有,全部都会打在数据库上,刚好还是类似于
select * from table where name = "李白"
表中有1000万条数据,name字段也没有创建索引。这时候问题是不是就大了?服务器稍微差一点,就会直接宕机。
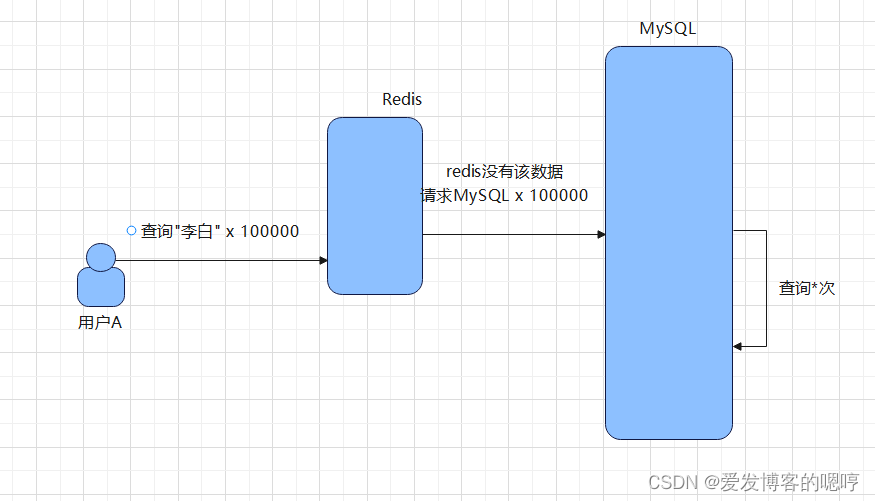
这时你或许该问了,那该如何解决呢?不要急,机智的程序猿肯定有应对之法。
2. 问题解决
2.1 缓存空数据
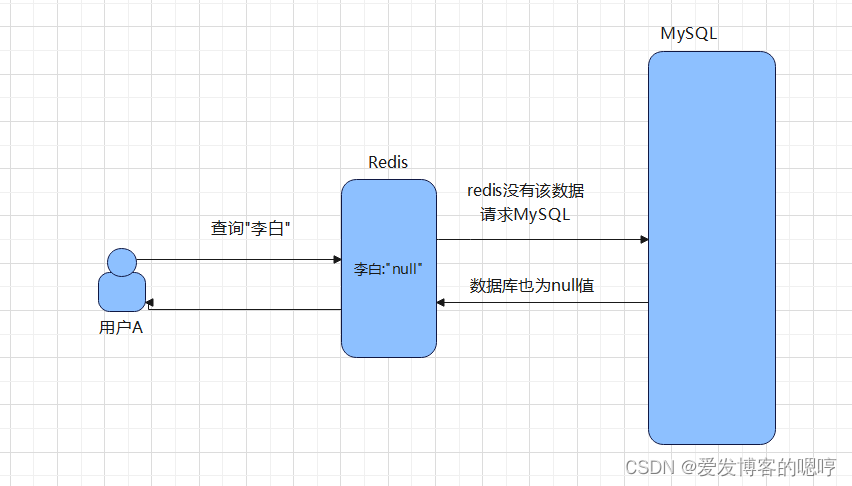
如果此时将请求的数据缓存起来,是不是就可以避免请求打到数据库了?
你现在或许又要问了,空数据怎么缓存呢?没错,就是缓存空数据。
如果请求的数据查询数据为空的话,就将该数据为空值缓存到Redis中,以后每次请求都直接访问Redis,查询到该数据,直接返回空值。这样就避免恶意请求全部打到数据库了。
2.2 布隆过滤器
不了解布隆过滤器的同学可以看这篇文章硬核 | Redis 布隆(Bloom Filter)过滤器原理与实战
布隆过滤器 (Bloom Filter)是由 Burton Howard Bloom 于 1970 年提出,它是一种 space efficient 的概率型数据结构,用于判断一个元素是否在集合中。
当布隆过滤器说,某个数据存在时,这个数据可能不存在;当布隆过滤器说,某个数据不存在时,那么这个数据一定不存在。
哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希表的 1/8 或 1/4 的空间复杂度就能完成同样的问题。
布隆过滤器可以插入元素,但不可以删除已有元素。
其中的元素越多,false positive rate(误报率)越大,但是 false negative (漏报)是不可能的。
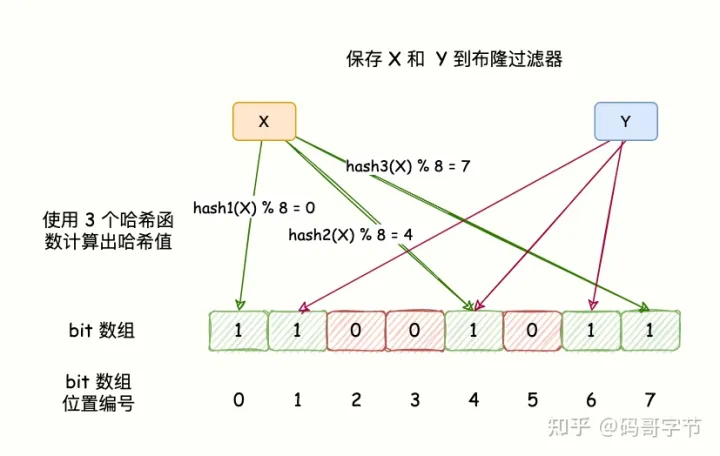
布隆过滤器原理
BloomFilter 的算法是,首先分配一块内存空间做 bit 数组,数组的 bit 位初始值全部设为 0。
加入元素时,采用 k 个相互独立的 Hash 函数计算,然后将元素 Hash 映射的 K 个位置全部设置为 1。
检测 key 是否存在,仍然用这 k 个 Hash 函数计算出 k 个位置,如果位置全部为 1,则表明 key 存在,否则不存在。
如下图所示:
三、缓存击穿
1. 问题描述
缓存击穿一般常见于电商场景,在双十一和六一八这种大促活动中,缓存中会缓存一些热点数据,随时都有大量的请求访问这个数据。
当某个时刻这个数据突然过期,大量请求就会集中打到MySQL数据库中。
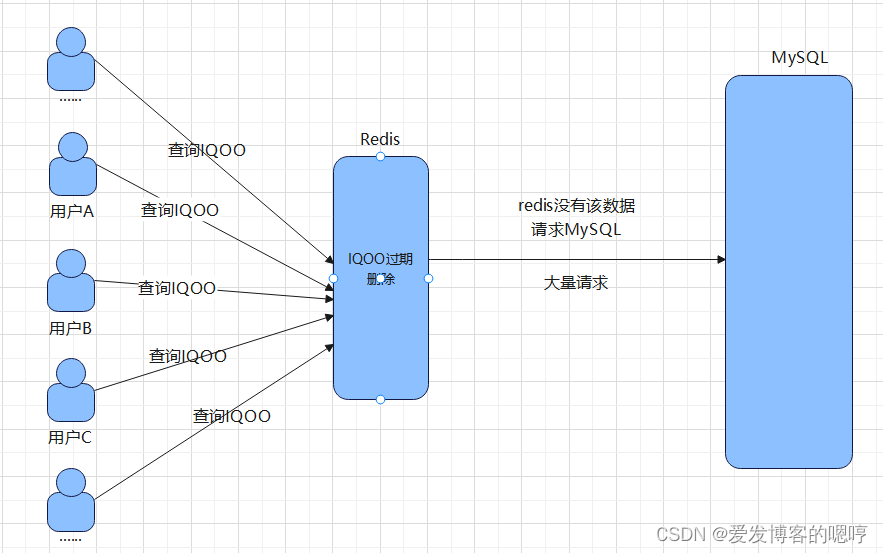
如何解决这个问题呢?
2. 问题解决
该问题导致的原因是因为该缓存数据过期了,但却有大量请求访问该数据;
有两条思路去解决:
- 不让该数据过期
- 不让大量请求访问数据库
2.1 设置逻辑过期
热点数据随时都会有变化,不设置过期时间的话会导致更多问题,不能因此失彼。
但可以换一个思路,在数据过期时无缝衔接一个新数据,在请求看来这就是没有过期时间的一个数据。
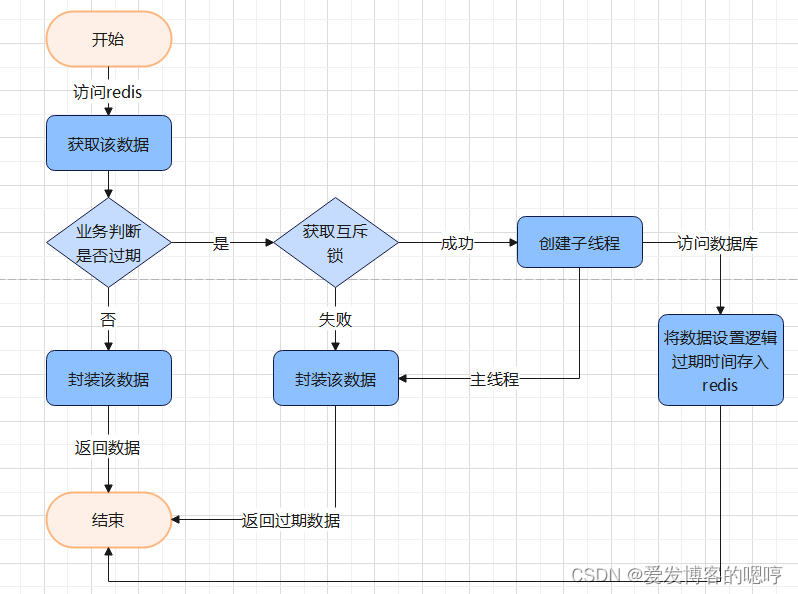
此时如果大量请求访问该数据,刚好该数据缓存逻辑过期,但没有设置物理过期时间,所以数据并不会被redis清除。
此时由业务代码去判断,该缓存是否过期,如果过期则获取互斥锁新建一个子线程去访问数据库重新设置缓存,主线程返回过期数据,没有获取互斥锁的都返回过期数据。
完整代码如下:
//逻辑过期public Shop queryWithLogicalExpire(Long id) {String key = CACHE_SHOP_KEY + id;//1.从redis查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);//2.判断是否存在if (StrUtil.isBlank(shopJson)) {//3.未命中return null;}//4.命中,需要先把json反序列化为对象RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);Shop shop = (Shop) redisData.getData();LocalDateTime expireTime = redisData.getExpireTime();//5.判断是否过期if (expireTime.isAfter(LocalDateTime.now())) {//5.1还未过期return shop;}//5.2已经过期,需要缓存重建//6.缓存重建//6.1获取互斥锁String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);//6.2判断是否获取锁成功if (isLock) {// 6.3成功,开启独立线程,实现缓存重建CACHE_REBUILD_EXECUTOR.submit(() -> {try {//重建缓存this.saveShop2Redis(id, 20L);} catch (Exception e) {e.printStackTrace();} finally {//释放锁unlock(lockKey);}});}//6.4返回过期的店铺信息//7.返回return shop;}2.2 设置互斥锁
怎么才能不让大量数据去访问数据库呢?
或许大家已经想到了,上面设置逻辑过期用到过的一个功能:互斥锁。
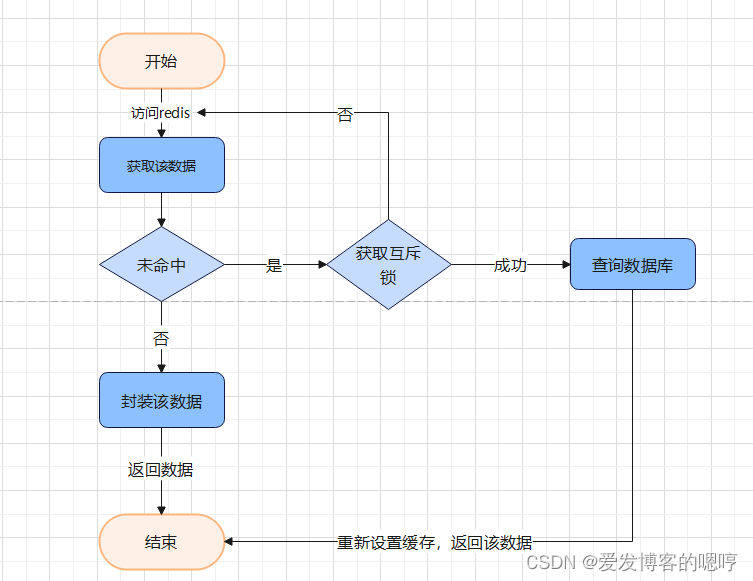
请求首先访问缓存,如果命中的话,直接返回该数据。
如果未命中的话,则去获取互斥锁,获取成功则查询数据库重新设置缓存,获取失败,则重试获取缓存数据。
完整代码如下:
/*** 通过互斥锁机制查询商铺信息* @param key*/private Shop queryShopWithMutex(String key, String cityCode) {Shop shop = null;// 1.查询缓存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判断缓存是否有数据if (StringUtils.isNotBlank(shopJson)) {// 3.有,则返回shop = JSONObject.parseObject(shopJson, Shop.class);return shop;}// 4.无,则获取互斥锁String lockKey = RedisConstants.LOCK_SHOP_KEY + shopCode;Boolean isLock = tryLock(lockKey);// 5.判断获取锁是否成功try {if (!isLock) {// 6.获取失败, 休眠并重试Thread.sleep(100);return queryShopWithMutex(key, shopCode);}// 7.获取成功, 查询数据库shop = baseMapper.getByCode(shopCode);// 8.判断数据库是否有数据if (shop == null) {// 9.无,则将空数据写入redisstringRedisTemplate.opsForValue().set(key, "", RedisConstants.CACHE_NULL_TTL, TimeUnit.MINUTES);return null;}// 10.有,则将数据写入redisstringRedisTemplate.opsForValue().set(key, JSONObject.toJSONString(shop), RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);} catch (Exception e) {throw new RuntimeException(e);} finally {// 11.释放锁unLock(lockKey);}// 12.返回数据return shop;}
关于两种方案,各有各的优缺点
- 逻辑过期: 及时性高,但数据不是最新数据,适合最终一致性的业务
- 互斥锁: 一致性高,但会有数据延迟,适合强一致性的业务
四、缓存雪崩
1. 问题描述
缓存雪崩可以简单的理解为大范围的缓存击穿。
有两个可能引起缓存雪崩问题:
- 有大量的热门缓存同时失效。会导致大量的请求,访问数据库。而数据库很有可能因为扛不住压力,而直接挂掉。
- 缓存服务器down机了,可能是机器硬件问题,或者机房网络问题。造成了整个缓存的不可用。

总结
缓存穿透、缓存击穿和缓存雪崩是三种与缓存相关的常见问题,它们的概念和影响有所不同。
关于Redis缓存三兄弟的问题及解决主要就是以下几个方面:
缓存穿透:
-
缓存穿透指的是对于一个不存在于缓存和数据库中的数据的请求,每次请求都会穿过缓存层直接访问数据库。
-
恶意的攻击者可以通过构造不存在的数据请求,导致大量请求直接访问数据库,增加数据库负载压力。
-
解决缓存穿透可以采用存储空数据和合适的校验技术,例如使用布隆过滤器等技术,在缓存层进行初步过滤,避免无效请求直接访问数据库。
缓存击穿:
-
缓存击穿指的是在高并发情况下,一个热点数据过期或失效时,大量请求同时涌入数据库,造成数据库压力激增。
-
由于热点数据没有命中缓存,而直接访问数据库,使得缓存无法发挥作用,增加了数据库的负载。
-
解决缓存击穿可以采取设置热点数据永不过期,或者使用互斥锁等机制来控制只有一个线程去加载数据。
缓存雪崩:
- 缓存雪崩指的是在某个时间点,缓存中的大量数据同时失效或过期或者缓存服务宕机,导致大量请求直接访问后端数据库,造成数据库压力过大。
- 当缓存中的数据集中过期或失效时,没有缓存可用,导致大量请求直接访问数据库,可能引起数据库负载激增甚至崩溃。
- 解决缓存雪崩可以采用合理的缓存失效时间设置、使用高可用架构等方式来减少缓存失效的风险。
当然能解决的方式有很多,这里只是列举出来常见的解决方法。如果有更好的建议可以发在评论区。
结语
每个人都有自己独特的才华和潜能,在这个广袤的世界上,你的存在是有意义的。无论你是谁,你的背景如何,你所处的环境怎样,只要你敢于跨出舒适区,付出努力,追求卓越,你就能够开创属于自己的辉煌。
我们下期见。
每一次努力都是一次进步,即使进展缓慢,也要坚持不懈。
往期文章推荐:
- 消息中间件相关面试题
- Java集合相关面试题
- Java集合详解
- 微服务相关面试题
- redis相关面试题
- 图解 Paxos 算法
- Spring相关面试题
- Mysql相关面试题