邢台提供网站建设公司电话免费搭建服务器
1.交换机结构
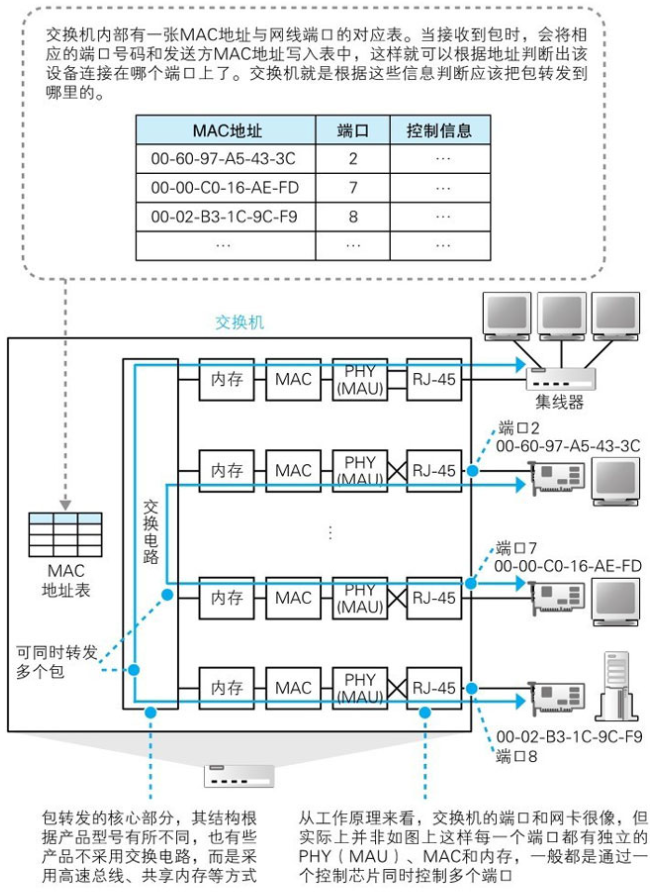
(1)网线接口和后面的电路部分加在一起称为一个端口,也就是说交换机的一个端口就相当于计算机上的一块网卡。
如果在计算机上安装多个网卡,并让网卡接收所有网络包,再安装具备交换机功能的软件,那计算机也就可以作为一台交换机了。
(2)交换机的工作方式和网卡不同。网卡本身具有MAC地址,通过核对收到的包的接收方MAC地址判断是不是发给自己的,如果不是发给自己的则丢弃;相对地,交换机的端口不核对接收方MAC地址,而是直接接收所有的包并存放到缓冲区中。交换机的端口也不具有MAC地址。
一些集成了更多功能的交换机的端口可能会有MAC地址
(3)交换机的全双工模式可以同时发送和接收信号,集线器不具备这样的功能,因此交换机可以隔离冲突域,而集线器不可以
交换机也并不是固定为全双工模式,有一种自动协商的功能会让连接双方提前相互告知各自支持的工作模式,从而选择一个最佳方案,这时交换机就可能工作在半双工模式下
(4)交换机可以同时转发多路数据,而集线器不可以
2.交换机自动维护MAC地址表
2.1收到包自动记录
交换机收到某台设备发来的网络包时,就会在MAC表中记录该设备的连接的端口号及其MAC地址,这样当其他设备要与该设备通信时就可以找到它了
2.2定时删除记录
为了防止某些设备从端口断开导致通信失败,交换机会在大约几分钟后删除MAC地址表的记录。
如果在交换机删除MAC地址表记录以前就发生了通信错误,那只需重启交换机即可。
一些具备管理功能的交换机也可以手动维护MAC地址表
3.交换机的两种特殊操作
3.1当数据包的目的端口和其源端口相同
交换机会直接丢弃这个包,以避免通信错误
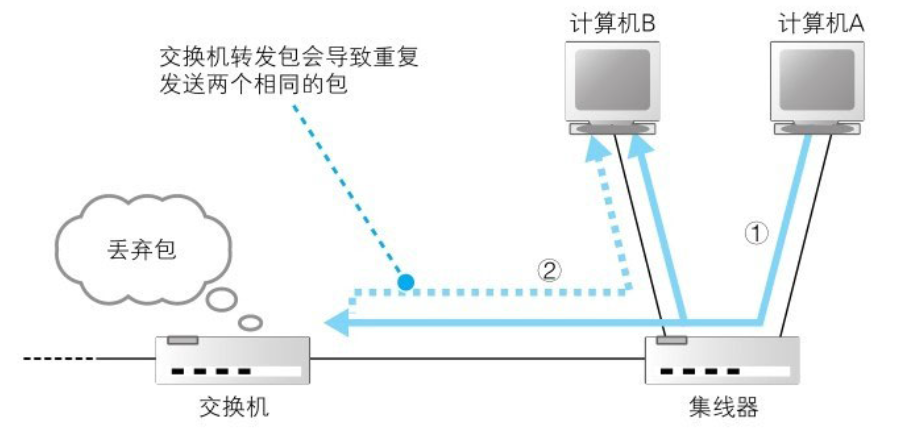
3.2当找不到MAC地址时
这时交换机会向除了源端口的所有端口转发此数据。相应的接收者会接收这个包,其他设备会忽略这个包。接收者收到数据包会发送响应信息,这时交换机就可以在MAC地址表中记录它的MAC地址了
*如果接收方地址是一个广播地址(ip:全255,MAC:全F),交换机也会向除了源端口的所有端口转发此数据