洛阳市住房和城乡建设局网站seo的优化技巧有哪些
文章目录
- 1、使用efak 创建 主题 my_topic1 并建立6个分区并给每个分区建立3个副本
- 2、创建生产者发送消息
- 3、application.yml配置
- 4、创建消费者监听器
- 5、创建SpringBoot启动类
- 6、屏蔽 kafka debug 日志 logback.xml
- 7、引入spring-kafka依赖
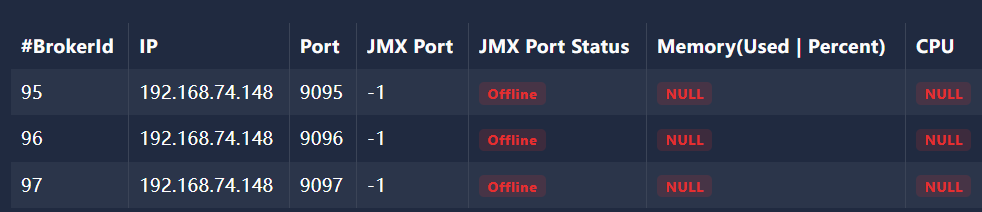
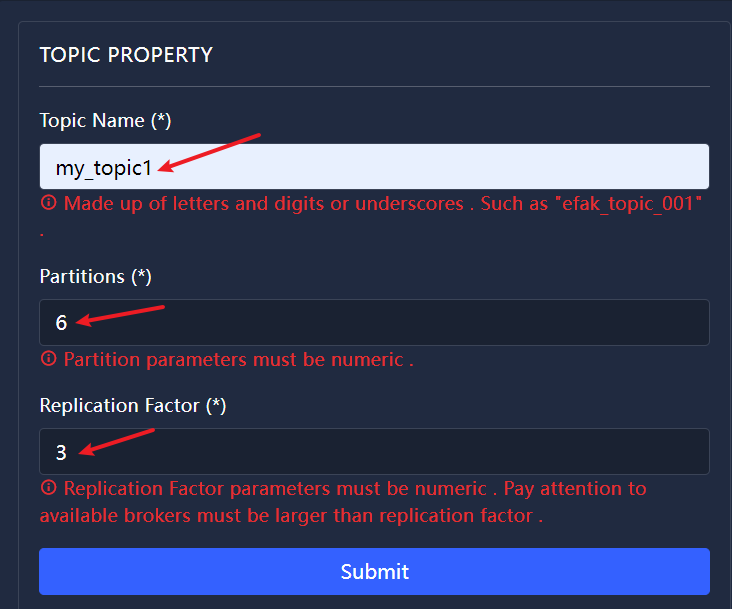
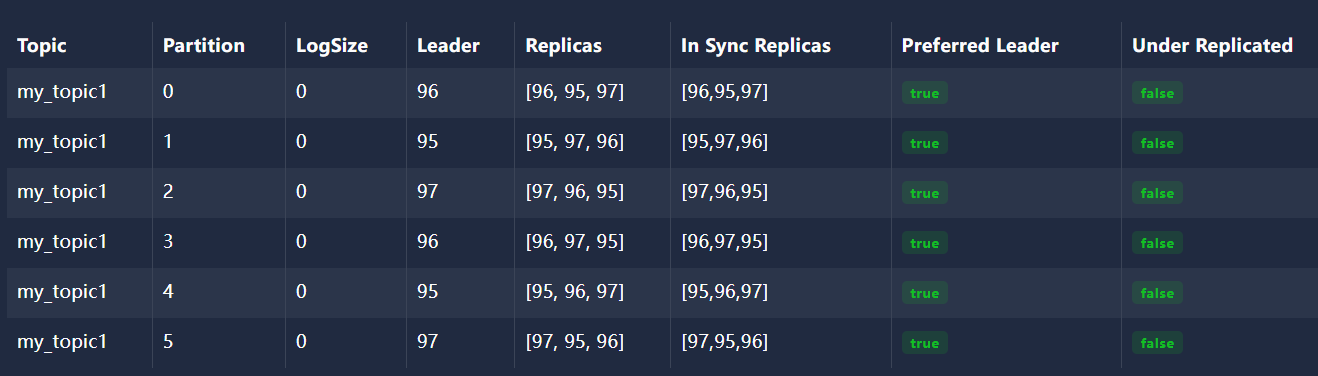
1、使用efak 创建 主题 my_topic1 并建立6个分区并给每个分区建立3个副本

2、创建生产者发送消息
[root@localhost ~]# kafka-console-producer.sh --bootstrap-server 192.168.74.148:9095,192.168.748:9096,192.168.74.148:9097 --topic my_topic1
>1
>2
>3
>
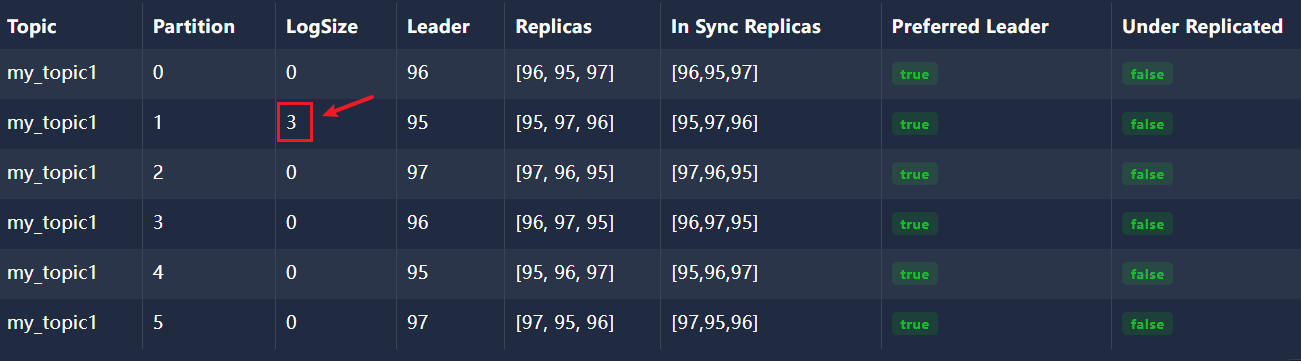
[[{"partition": 1,"offset": 0,"msg": "1","timespan": 1717592203289,"date": "2024-06-05 12:56:43"},{"partition": 1,"offset": 1,"msg": "2","timespan": 1717592204046,"date": "2024-06-05 12:56:44"},{"partition": 1,"offset": 2,"msg": "3","timespan": 1717592204473,"date": "2024-06-05 12:56:44"}]
]
3、application.yml配置
server:port: 8120# v1
spring:Kafka:bootstrap-servers: 192.168.74.148:9095,192.168.74.148:9096,192.168.74.148:9097consumer:# read-committed读事务已提交的消息 解决脏读问题isolation-level: read-committed # 消费者的事务隔离级别:read-uncommitted会导致脏读,可以读取生产者事务还未提交的消息# 消费者是否自动ack :true自动ack 消费者获取到消息后kafka提交消费者偏移量enable-auto-commit: true # ??????offset# 消费者提交ack时多长时间批量提交一次auto-commit-interval: 1000# 消费者第一次消费主题消息时从哪个位置开始auto-offset-reset: earliest #指定Offset消费:earliest | latest | nonekey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer4、创建消费者监听器
package com.atguigu.spring.kafka.consumer.listener;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class MyKafkaListener {@KafkaListener(topics ={"my_topic1"},groupId = "my_group1")public void onMessage(ConsumerRecord<String, String> record) {System.out.println("消费者获取到消息:topic = "+ record.topic()+",partition:"+record.partition()+",offset = "+record.offset()+",key = "+record.key()+",value = "+record.value());}}5、创建SpringBoot启动类
package com.atguigu.spring.kafka.consumer;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;// Generated by https://start.springboot.io
// 优质的 spring/boot/data/security/cloud 框架中文文档尽在 => https://springdoc.cn
@SpringBootApplication
public class SpringKafkaConsumerApplication {public static void main(String[] args) {SpringApplication.run(SpringKafkaConsumerApplication.class, args);}}6、屏蔽 kafka debug 日志 logback.xml
<configuration> <!-- 如果觉得idea控制台日志太多,src\main\resources目录下新建logback.xml
屏蔽kafka debug --><logger name="org.apache.kafka.clients" level="debug" />
</configuration>7、引入spring-kafka依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.0.5</version><relativePath/> <!-- lookup parent from repository --></parent><!-- Generated by https://start.springboot.io --><!-- 优质的 spring/boot/data/security/cloud 框架中文文档尽在 => https://springdoc.cn --><groupId>com.atguigu</groupId><artifactId>spring-kafka-consumer</artifactId><version>0.0.1-SNAPSHOT</version><name>spring-kafka-consumer</name><description>spring-kafka-consumer</description><properties><java.version>17</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
此时启动SpringKafkaConsumerApplication,控制台会打印数据
. ____ _ __ _ _/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \\\/ ___)| |_)| | | | | || (_| | ) ) ) )' |____| .__|_| |_|_| |_\__, | / / / /=========|_|==============|___/=/_/_/_/:: Spring Boot :: (v3.0.5)消费者获取到消息:topic = my_topic1,partition:1,offset = 0,key = null,value = 1
消费者获取到消息:topic = my_topic1,partition:1,offset = 1,key = null,value = 2
消费者获取到消息:topic = my_topic1,partition:1,offset = 2,key = null,value = 3
如果此时重新启动SpringKafkaConsumerApplication,控制台将不会打印数据,因为已经消费过数据
. ____ _ __ _ _/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \\\/ ___)| |_)| | | | | || (_| | ) ) ) )' |____| .__|_| |_|_| |_\__, | / / / /=========|_|==============|___/=/_/_/_/:: Spring Boot :: (v3.0.5)