深圳住房建设局网站颍上网站建设

目录
防火墙的定义
防火墙的功能
防火墙的特性
防火墙的必要性
防火墙的优点
防火墙的局限性
防火墙的分类
分组过滤防火墙
优点:
缺点:
应用代理防火墙
优点
缺点
状态检测防火墙
优点
缺点
防火墙的定义
防火墙的本义原是指古代人们房屋之间修建的墙,这道墙可以防止火灾发生的时候蔓延到别的房屋,如下图所示

在互联网上,防火墙是一种非常有效的网络安全系统,通过它可以隔离风险区域(Internet或有一定风险的网络)与安全区域(局域网)的连接,同时不会妨碍安全区域对风险区域的访问,网络防火墙结构如图所示
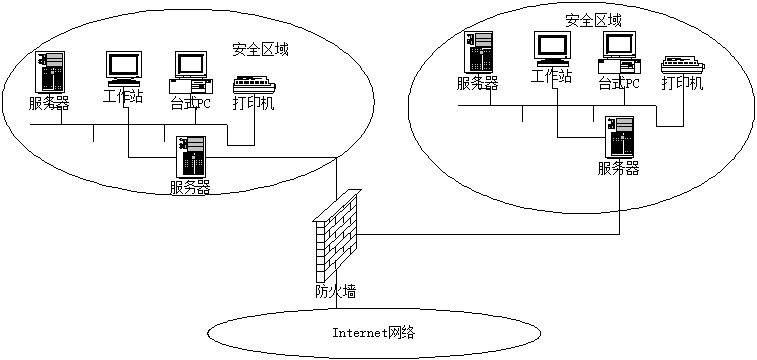
防火墙一般放置在被保护网络的边界,要使防火墙起到安全防御作用,必须做到三点:
- 使所有进出被保护网络的通信数据流必须经过防火墙
- 所有通过防火墙的通信必须经过安全策略的过滤或者防火墙的授权
- 防火墙本身也必须是不可被侵入的
防火墙的功能
根据不同的需要,防火墙的功能有比较大差异,但是一般都包含以下三种基本功能:
- 可以限制未授权的用户进入内部网络,过滤掉不安全的服务和非法用户
- 防止入侵者接近网络防御设施
- 限制内部用户访问特殊站点
由于防火墙假设了网络边界和服务,因此适合于相对独立的网络,例如Intranet(内部网)等种类相对集中的网络。Internet上的Web网站中,超过三分之一的站点都是有某种防火墙保护的,任何关键性的服务器,都应该放在防火墙之后
防火墙的特性
防火墙的必要性
随着世界各国信息基础设施的逐渐形成,国与国之间变得“近在咫尺”。Internet已经成为信息化社会发展的重要保证,深入到国家的政治、军事、经济、文教等诸多领域。 许多重要的政府宏观调控决策、商业经济信息、银行资金转帐、股票证券、能源资源数据、科研数据等重要信息都通过网络存贮、传输和处理。因此,难免会遭遇各种主动或被动的攻击。 例如信息泄漏、信息窃取、数据篡改、数据删除和计算机病毒等。因此,网络安全已经成为迫在眉睫的重要问题,没有网络安全就没有社会信息化
防火墙的优点
- 防火墙对内部网实现了集中的安全管理,可以强化网络安全策略,比分散的主机管理更经济易行
- 防火墙能防止非授权用户进入内部网络
- 防火墙可以方便地监视网络的安全性并报警。 可以作为配置网络地址转换的地点,利用NAT技术,可以缓解地址空间的短缺,隐藏内部网的结构
- 由于所有的访问都经过防火墙,防火墙是审计和记录网络访问和使用的最佳地方
防火墙的局限性
没有万能的网络安全技术,防火墙也不例外。防火墙有以下三方面的局限:
- 防火墙不能防范网络内部的攻击。比如:防火墙无法禁止变节者或内部间谍将敏感数据拷贝到软盘上
- 防火墙也不能防范那些伪装成超级用户或诈称新雇员的黑客们劝说没有防范心理的用户公开其口令,并授予其临时的网络访问权限
- 防火墙不能防止传送己感染病毒的软件或文件,不能期望防火墙去对每一个文件进行扫描,查出潜在的病毒
防火墙的分类
常见的防火墙有三种类型:
- 分组过滤防火墙
- 应用代理防火墙
- 状态检测防火墙
分组过滤防火墙
分组过滤(Packet Filtering):也叫作包过滤防火墙,作用在协议组的网络层和传输层,根据分组包头源地址、目的地址和端口号、协议类型等标志确定是否允许数据包通过,只有满足过滤逻辑的数据包才被转发到相应的目的地的出口端,其余的数据包则从数据流中丢弃。
数据包过滤可以在网络层截获数据。使用一些规则来确定是否转发或丢弃所各个数据包。 通常情况下,如果规则中没有明确允许指定数据包的出入,那么数据包将被丢弃
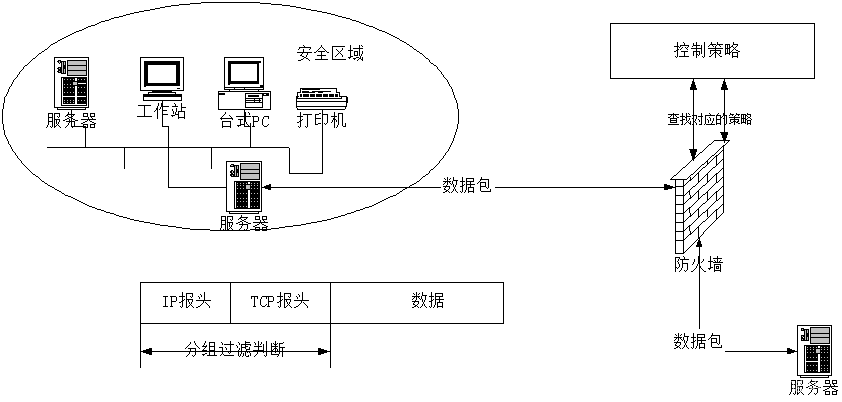
防火墙审查每个数据包,以确定其是否与某条包过滤规则相匹配。 过滤规则基于IP转发所使用的包头信息,包括IP源/目的地址,内部协议(TCP/UDP/ICMP)、TCP/UDP目的端口号和ICMP消息类型等。 如果规则匹配失败,用户配置的默认参数会决定转发还是丢弃数据包。
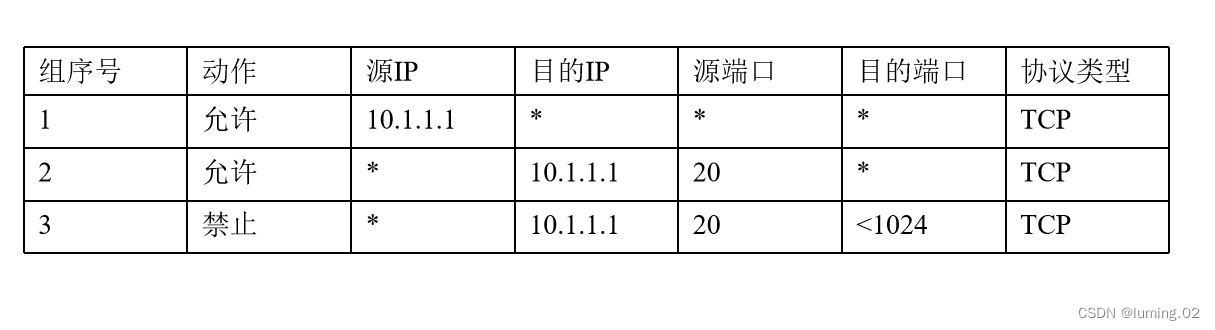
一个可靠的分组过滤防火墙依赖于规则集,下表列出了几条典型的规则集:
- 第一条规则:主机10.1.1.1任何端口访问任何主机的任何端口,基于TCP协议的数据包都允许通过
- 第二条规则:任何主机的20端口访问主机10.1.1.1的任何端口,基于TCP协议的数据包允许通过
- 第三条规则:任何主机的20端口访问主机10.1.1.1小于1024的端口,如果基于TCP协议的数据包都禁止通过
优点:
- 无需修改客户机和主机上的程序。因为工作在网络层和传输层,与应用层无关
- 可以和现成的路由器集成,也可以软件实现
缺点:
- 不能区分出数据包的好坏
- 需要广泛的TCP/IP知识
- 需要创建大量规则,工作量大
- 基于IP包头中的信息进行过滤容易受到欺骗攻击,例如伪造IP地址等
应用代理防火墙
应用代理(Application Proxy):也叫应用网关(Application Gateway),它作用在应用层,其特点是完全“阻隔”网络通信流,通过对每种应用服务编制专门的代理程序,实现监视和控制应用层通信流的作用。实际中的应用网关通常由专用工作站实现。
应用代理是运行在防火墙上的一种服务器程序,防火墙主机可以是一个具有两个网络接口的双重宿主主机,也可以是一个堡垒主机。 代理服务器被放置在内部服务器和外部服务器之间,用于转接内外主机之间的通信,它可以根据安全策略来决定是否为用户进行代理服务。代理服务器运行在应用层,因此又被称为“应用网关”。
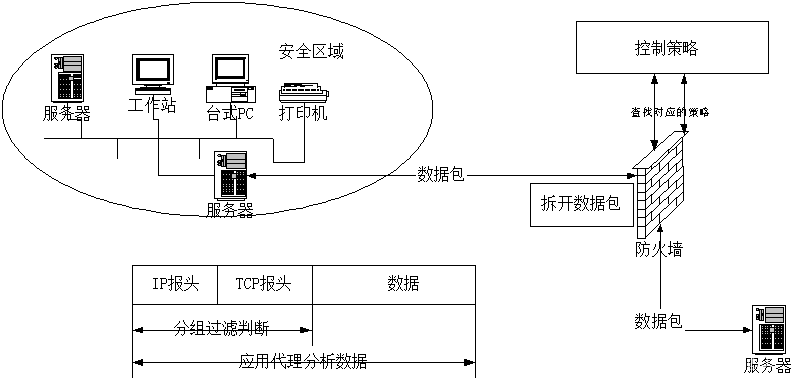
应用代理防火墙通过编程来弄清用户应用层的流量,并能在应用层提供访问控制。而且,还可记录所有应用程序的访问情况,记录和控制所有进出流量,代理服务器会像一堵墙一样挡在内部用户和外界之间,从外部只能看到该代理服务器而无法获知任何的内部资源
代理服务器指代表客户处理与服务器连接请求的程序。 当代理服务器接收到用户对某站点的访问请求后,便会检查该请求是否符合规则,如果规则允许用户访问该站点的话,代理服务器会像一个客户一样去那个站点取回所需信息再转发给客户,代理服务器通常都拥有一个高速缓存,这个缓存存储着用户经常访问的站点内容,在下一个用户要访问同一站点时,服务器就不用重复地获取相同的内容,直接将缓存内容发出即可,既节约了时间也节约了网络资源
可以使用代理来控制实际的数据流:例如,一个应用代理可以限制FTP用户只能从Internet上获取文件,而不能将文件上传至Internet。 如果网络管理员没有为某种应用安装代理程序,那么该项服务就不支持并不能通过防火墙系统来转发
优点
- 具有代理服务的应用网关可被配置成唯一可以被外部网络可视的主机,这样就可以保护内部主机免受外部主机的攻击
- 一些代理服务器提供高速的缓存功能,在应用网关上可以强制执行用户身份认证
- 代理工作在客户机与真实服务器之间,完全控制会话,所以可提供详细的日志
- 在应用网关上可以使用第三方提供的身份认证和日志记录系统
- 能灵活、完全地控制进出流量和内容,能过滤数据内容以及能为用户提供透明的加密机制
缺点
- Internet服务的代理版本总是要滞后其标准版本,对于一个新的或者不常用的服务,很难找到可靠的代理版本
- 代理服务器具有解释应用层命令的功能(如解释FTP命令、Telnet命令等),因此可能需要提供很多种不同的代理服务器(如FTP代理服务器、Telnet代理服务器),并且所能提供的服务和可伸缩性是有限的
- 解释应用层命令的代理服务器,需要定制用户进程,这就给用户的使用带来了不便
- 一些服务是很难进行代理的,比如某些数据交流很复杂的服务,要同时用到tcp和udp协议
- 代理建立了一个网络的服务瓶颈,因为它要检查每一个数据包。因此速度较路由器慢,且对用户不透明
状态检测防火墙
状态检测(Status Detection):直接对分组里的数据进行处理,并且结合前后分组的数据进行综合判断,然后决定是否允许该数据包通过
状态检测防火墙在网络层有一个执行网络安全策略的检查引擎截获数据包并抽取出与应用层状态有关的信息,并以此为依据决定对该连接是接受还是拒绝。 检查引擎在不影响网络正常工作的前提下,采用抽取相关数据的方法对网络通信的各层实施监测,抽取部分数据,即状态信息 状态检测防火墙克服了包过滤防火墙和应用代理服务器的局限性,不仅仅检测“to”和“from”的地址,而且不要求每个访问的应用都有代理。
状态检测防火墙同包过滤技术一样,它能够检测通过IP地址、端口号以及TCP标记,过滤进出的数据包。 允许受信任的客户机和不受信任的主机建立直接连接,不依靠与应用层有关的代理,而是依靠某种算法来识别进出的应用层数据,这些算法通过己知合法数据包的模式来比较进出数据包,这样从理论上就能比应用级代理在过滤数据包上更有效。 此外,它还可监测RPC和UDP端口信息,而包过滤和代理都不支持此类端口。
优点
安全性:状态检测防火墙工作在数据链路层和网络层之间,它从这里截取数据包,因为数据链路层是网卡工作的真正位置,网络层是协议栈的第一层,这样防火墙确保了截取和检查所有通过网络的原始数据包
性能:状态检测防火墙工作在协议栈的较低层,通过防火墙的所有的数据包都在低层处理,而不需要协议栈的上层处理任何数据包,这样减少了高层协议头的开销
扩展性:状态检测防火墙不区分每个具体的应用,只是根据从数据包中提取出的信息、对应的安全策略及过滤规则处理数据包
当有一个新的应用时,它能动态产生新的应用的新的规则,而不用另外写代码,所以具有很好的伸缩性和扩展性
能够支持多种协议和应用程序,并可以很容易地实现应用和服务的扩充
缺点
包过滤防火墙得以进行正常工作的一切依据都在于过滤规则的实施,但又不能满足建立精细规则的要求,并不能分析高级协议中的数据
应用网络关防火墙的每个连接都必须建立在为之创建的有一套复杂的协议分析机制的代理程序进程上,这会导致数据延迟的现象
状态检测防火墙虽然继承了包过滤防火墙和应用网关防火墙的优点,克服了它们的缺点,但它仍只是检测数据包的第三层信息,无法彻底的识别数据包中大量的垃圾邮件、广告以及木马程序等等