怎么注册网站账号平台app如何推广
你可能遇到过这样的地形:悬崖陡峭的一侧的纹理拉伸得如此之大,以至于看起来不切实际。 也许你有一个程序化生成的世界,你无法对其进行 UV 展开和纹理处理。

推荐:用 NSDT编辑器 快速搭建可编程3D场景
三平面映射(Triplanar Mapping)提供了一种优雅的技术来解决这些问题,并为你提供来自任何角度或任何复杂形状的逼真纹理。 在本文中我们将了解该技术,查看代码,并了解使用三平面映射时的一些优点、缺点和其他可能性。
1、地形纹理化的UV问题
最常见的问题是纹理拉伸,尤其是在地形方面。 问题在于正在纹理化的对象的 UV 坐标。 对于地形,UV 坐标分布在网格中,在 X-Y 平面上均匀分布,如下所示:
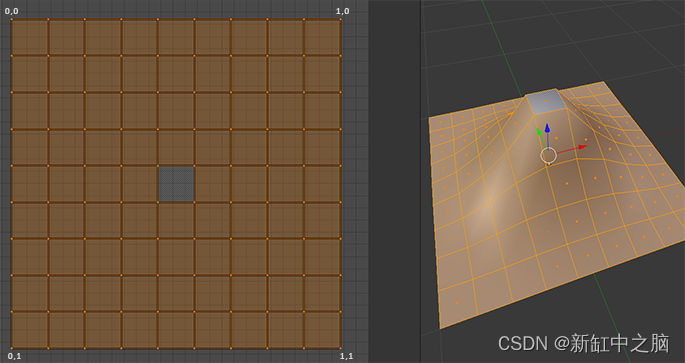
上图中的UV 布局未考虑地形的高度差并导致拉伸。 你可以采取措施,通过仔细展开 UV 坐标来均匀陡峭多边形的区域,但这会导致结果不太理想。 你仍然有扭曲的纹理,并且一些图块(例如中间的图块)被压缩。
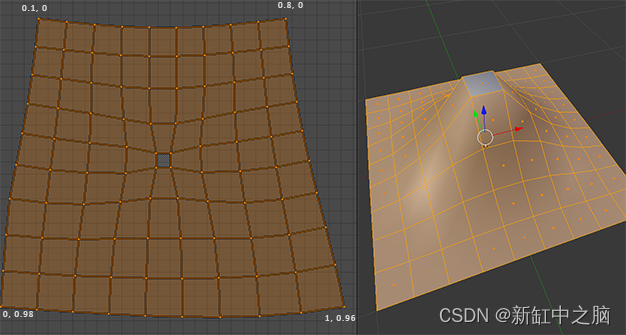
你也可能无法展开网格物体 UV 坐标:可以通过程序生成地形或形状。 也许你的形状中有一个洞穴系统或洞。
我们可以使用三平面映射技术(也称为“三平面纹理”)来解决这些问题。
2、基于Triplanar映射的地形纹理化
首先,让我们再次查看应用了三平面映射的地形:

使用三平面映射的地形
现在好多了! 拉伸消失了,陡峭的斜坡看起来更加真实。
Triplanar映射通过在 3 个不同的方向(X、Y 和 Z 轴)上渲染纹理 3 次来实现此目的。 想象一个盒子。 首先,纹理从正 X 轴向下投影到负 X 轴。 面向 X 轴方向的任何片段(几何体的像素)都会应用纹理。 Y轴和Z轴也进行同样的处理。
这些渲染混合在一起。 因此,一半面向 X 轴、一半面向 Z 轴的片段将占用一半的 X 轴渲染和一半的 Z 轴渲染。 如果片段的 90% 面向 X 轴,则它会接收 90% 的 X 轴渲染,而仅接收 10% 的 Z 轴渲染。 就像拿3个喷雾罐,从顶部、侧面、正面喷射。

从 3 个角度投射的纹理
所有这些都是在材质的片段着色器中完成的。 它本质上对几何体进行 3 次纹理处理,每个方向一次,然后混合结果。
Triplanar映射根本不使用 UV 坐标。 相反,它使用实际的世界坐标。 知道了这一点,我们来看看代码。
第一部分计算每个方向的混合因子:
// in wNorm is the world-space normal of the fragment
vec3 blending = abs( wNorm );
blending = normalize(max(blending, 0.00001)); // Force weights to sum to 1.0
float b = (blending.x + blending.y + blending.z);
blending /= vec3(b, b, b);
这里它采用片段的世界空间法线(它将被标准化,并且每个分量将在 -1 和 1 的范围内),我们将其设为绝对值。 我们不关心法线是否面向 -X 或 X,只要它位于 X 轴即可。 如果我们确实担心绝对方向,我们就会从前、后、左、右、上、下绘制形状; 比我们需要的多3倍。
接下来我们强制它在 0 到 1 的范围内,因此我们最终得到每个轴分量的百分比乘数。 如果法线在 Y 轴上朝上,我们得到的 Y 值为 1,它会得到所有 Y 轴绘画,而其他轴的值为 0,不会得到任何结果。
这是最困难的部分。 接下来,我们将三个混合值 (x,y,z) 与该纹理坐标处的纹理混合。 请记住,纹理坐标位于世界空间中:
vec4 xaxis = texture2D( rockTexture, coords.yz);
vec4 yaxis = texture2D( rockTexture, coords.xz);
vec4 zaxis = texture2D( rockTexture, coords.xy);
// blend the results of the 3 planar projections.
vec4 tex = xaxis * blending.x + xaxis * blending.y + zaxis * blending.z;
我们终于得到它了。 tex是片段的最终颜色,从 3 个轴混合 3 次。
将比例因子应用于纹理会非常方便,因为你无疑会想要缩放它:
// in float scale
vec4 xaxis = texture2D( rockTexture, coords.yz * scale);
vec4 yaxis = texture2D( rockTexture, coords.xz * scale);
vec4 zaxis = texture2D( rockTexture, coords.xy * scale);
vec4 tex = xaxis * blending.x + xaxis * blending.y + zaxis * blending.z;
3、法线的处理方法
如果你使用三平面映射和法线贴图,还需要对片段着色器中的法线应用相同的过程,如下所示:
vec4 xaxis = texture2D( rockNormalTexture, coords.yz * scale);
vec4 yaxis = texture2D( rockNormalTexture, coords.xz * scale);
vec4 zaxis = texture2D( rockNormalTexture, coords.xy * scale);
vec4 tex = xaxis * blending.x + xaxis * blending.y + zaxis * blending.z;
小技巧:
可以创建 getTriPlanarBlend() 函数来计算漫反射、法线和镜面纹理的混合。
4、Triplanar映射的问题
你将遇到的第一个问题是性能。 几何体的片段将被渲染 3 次,每个方向一次。 这意味着颜色和照明计算(法线)将被重复然后混合。 如果已经有空闲帧问题,可能不想使用三平面映射。
下一个重大问题是 45 度角的混合,尤其是在使用纹理泼溅的地方不同纹理重叠的情况。 你可以从角点再执行 4 次渲染,但这样做所带来的性能损失可能不值得。 你可以尝试与深度图混合,这是一种有时用于纹理泼溅的技术。
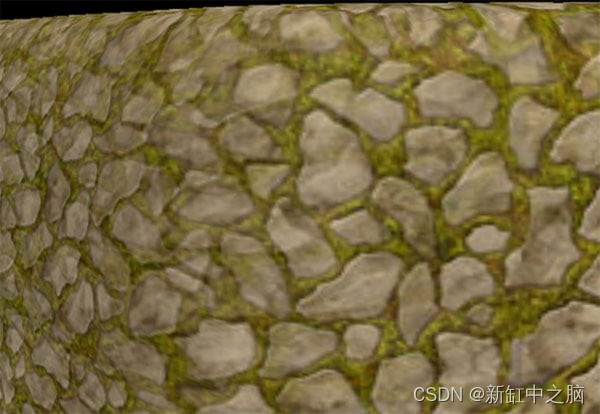
可见的透明重叠
5、结束语
现在我们理解了三平面贴图的工作原理及其用途。 但它还有许多其他应用程序,可以稍微改变它以产生有趣的结果。
如前所述,程序化地形是该技术的良好候选者。 洞穴、悬崖和复杂的熔岩隧道现在很容易纹理化。 你甚至可以根据一些随机或伪随机(噪声)例程来影响使用的纹理。 标高甚至坡度可以决定使用什么纹理。
通过修改例程以仅从顶部(y 轴)投影纹理并将混合值牢固地限制在可接受的范围内,即 10%,那么你可以在场景中所有物体的顶部渲染雪。 使用相同的技术,原子爆炸可以烧焦从某个世界坐标原点辐射出的所有物体,但基于原点的角度并使用暗烧纹理。
原文链接:地形纹理Triplanar映射 — BimAnt