教做饮品的网站wordpress 速度太慢
工训中心的牛马实验
1.实验目的:
1) 认识开关电路,掌握按键状态判别、开关电路中逻辑电平测量、逻辑值和逻辑函数电路。
2) 掌握按键信号抖动简单处理方法。
3) 实现按键计数电路。
2.实验资源:
HBE硬件基础电路实验箱、示波器、万用表
按键开关(4端子)、带自锁按钮开关(6端子,单刀双掷)、74LS160芯片
3.实验任务
1)认识开关电路,掌握按键状态判别、开关电路中逻辑电平测量、逻辑值和逻辑函数电路。
阅读教材P19 2.逻辑值与电压值。
【*】万用表蜂鸣档判断按键开关好坏,何处端子间接触与断开状态。
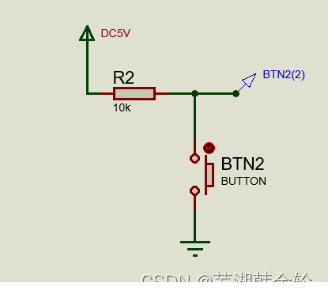
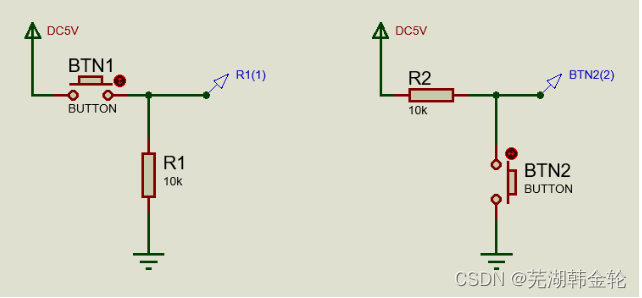
【*】搭建两种【按键开关电路】,万用表DC电压档测量并记录按键开和关状态测量点电压值,同时以“高电平为1,低电平为0”规则指出各自电路中开关什么时候输入逻辑1或0。

【*】选按钮型电平开关实现带LED灯显示开关电路。请说明灯状态所指示的开关状态,通过测点电压值简述理由(直流电压源输入3.3V)。

2) 掌握按键信号抖动简单处理方法。
请首先阅读手持示波器的使用方法。
手持示波器可以通过设置触发电平,捕捉非周期性的突发信号波形
用示波器观察【按键开关电路】抖动,掌握【简单硬件消抖 0.1uf 和 1uf后统计20次中出现抖动次数】处理方法,测量简单处理后波形。
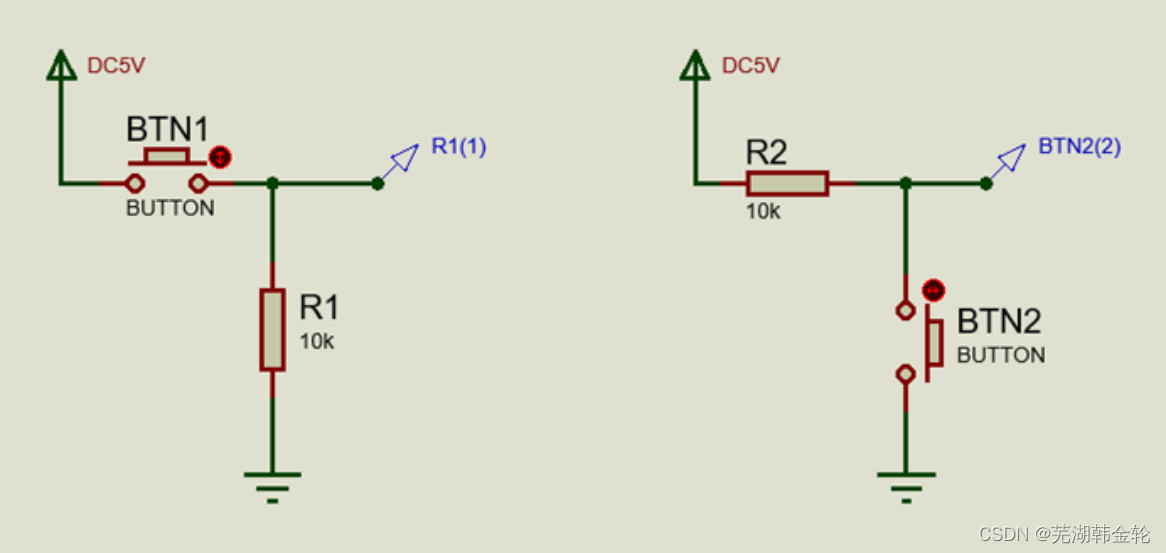
【*】左图,示波器设定为单通道捕获,正常模式,下降沿触发。多次按键按下动作记录信号下降沿抖动现象出现次数和时间长度。
【*】右图,示波器设定为单通道捕获,正常模式,下降沿触发。多次按键释放动作记录信号上升沿抖动现象出现次数和时间长度。

简单硬件消抖处理方法:
【*】右图上按键两端子间依次单独并联0.01uf、0.1uf 和0.47uf电容后,分别统计10次中未出现抖动次数并记录处理后波形,简述按键开关信号处理前后变化和电容值影响。
3) 实现按键计数电路。
【*】如图,选择合适的C1电容,按键开关消抖后信号能通过计数器检验电路,说明检验步骤。

4.实验过程和记录
1认识开关电路,掌握按键状态判别、开关电路中逻辑电平测量、逻辑值和逻辑函数电路
实验步骤:1. 万用表蜂鸣档判断按键开关好坏,何处端子间接触与断开状态。
2. 搭建两种【按键开关电路】,万用表DC电压档测量并记录按键开和关状态测量点电压值,同时以“高电平为1,低电平为0”规则指出各自电路中开关什么时候输入逻辑1或0。
实验结果:1.所有的开关均可以正常运行。开关在按下时接通,松开时断开。
2.经过测量,在按下开关时产生高电平,松开时为低电平
2.掌握按键信号抖动简单处理方法
实验步骤:
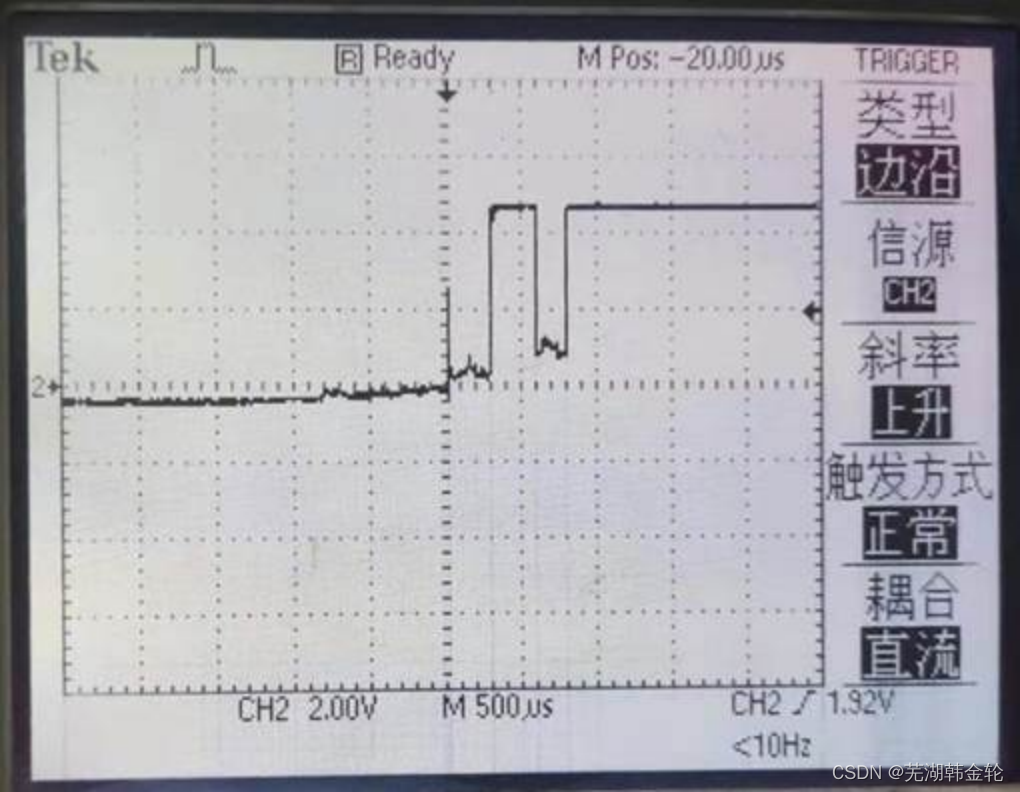
依照要求设置示波器,并依照下面的电路图连接电路左图,示波器设定为单通道捕获,正常模式,下降沿触发。多次按键按下动作记录信号下降沿抖动现象出现次数和时间长度。
右图,示波器设定为单通道捕获,正常模式,下降沿触发。多次按键释放动作记录信号上升沿抖动现象出现次数和时间长度。
- 触发开关,观察观察示波器显示的波形图
- 右图上按键两端子间依次单独并联0.01uf、0.1uf 和0.47uf电容后,分别统计10次中未出现抖动次数并记录处理后波形,简述按键开关信号处理前后变化和电容值影响。
实验结果:
- 在未进行消抖处理之前,触发后存在较为明显的跳变:
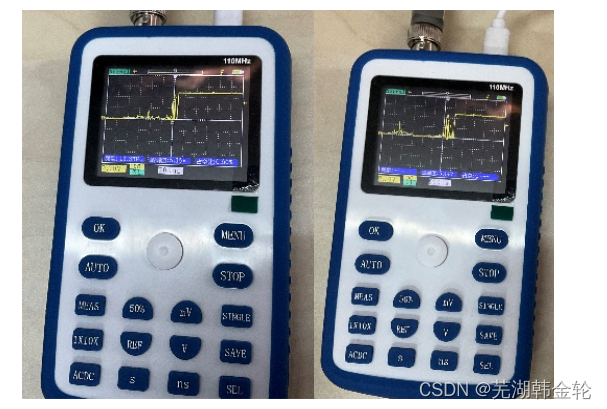
- 在并联电容后,波形图变化变得更加平滑

实验分析:在未进行防抖处理之前,会出现比较明显的跳变现象;在进行处理之后,存在明显的改善
3.实现按键计数电路
实验内容:如图,选择合适的C1电容,按键开关消抖后信号能通过计数器检验电路,说明检验步骤。

实验步骤:
- 依照上图连接电路
- 依次按下开关,观察显示效果
实验结果:

结果分析:
由于设备精密度不足,并不能完全显示每个数字,但基本可以看出计数结果,说明电路基本无误。