南宁高端网站wordpress 主机要求
介绍
基于mybatis-plus代码生成工具
后续会不断完善
规划
后续会基于此功能搞低代码平台,会有前端VUE
mybatis-plus介绍&特性
• 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
• 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
• 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
• 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
• 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
• 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
• 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
• 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
• 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
• 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
• 内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
• 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
代码生成
- 自定义模版
- 生成内容
controller/entity/dto/vo/convertor/service/serviceImpl/dao/mapper
功能说明
基于模版生成,模版在templates下
restful接口和基础功能实现
service服务实现和基础功能实现
entity/dto/vo/convertor,不同传输对象和转化
使用分页插件
使用逻辑删除标识
使用说明
CodeGeneration,直接执行即可
如需要做个性化配置,则自己改即可
测试类
测试sql在resources/sql/test.sql
查看TestGeneration.http实现
模块结构
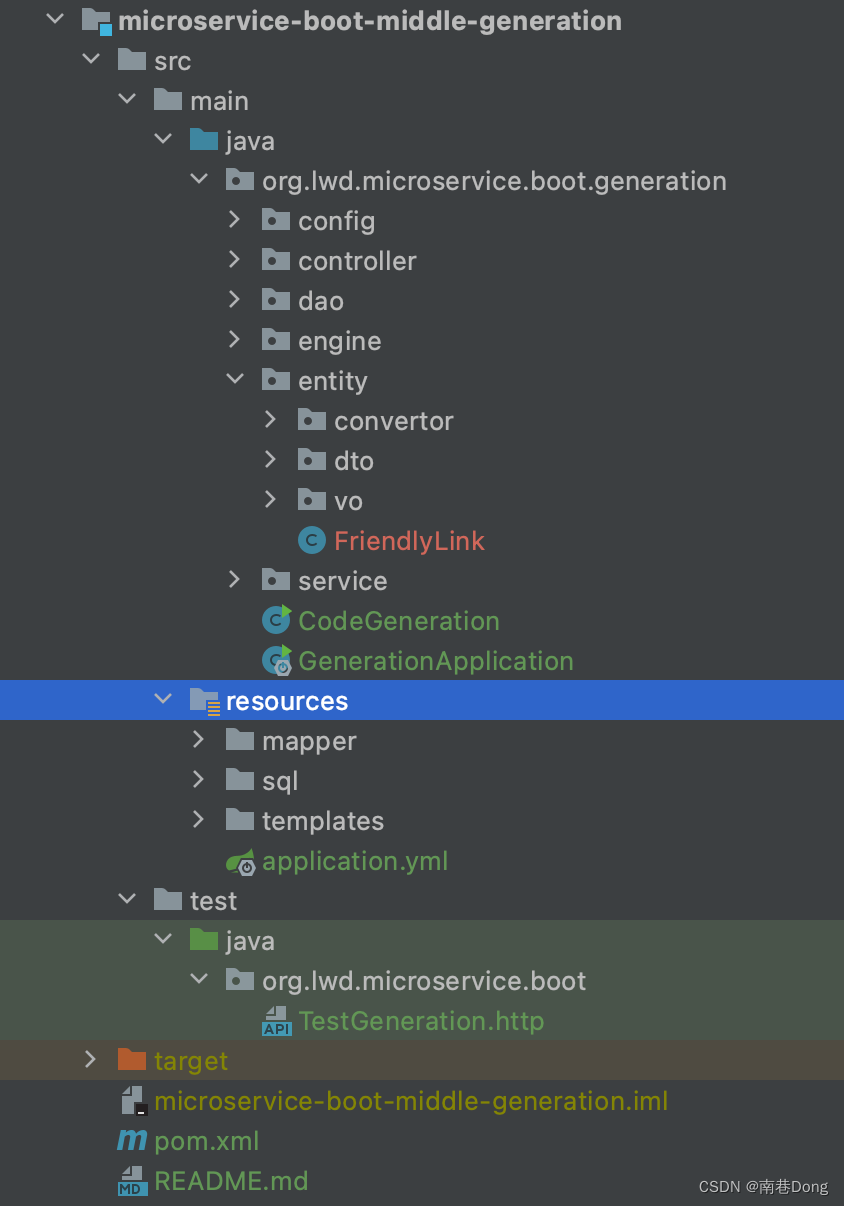
CodeGeneration 代码
package org.lwd.microservice.boot.generation;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.generator.FastAutoGenerator;
import com.baomidou.mybatisplus.generator.config.*;
import com.baomidou.mybatisplus.generator.config.converts.MySqlTypeConvert;
import com.baomidou.mybatisplus.generator.config.querys.MySqlQuery;
import com.baomidou.mybatisplus.generator.config.rules.DateType;
import com.baomidou.mybatisplus.generator.config.rules.IColumnType;
import com.baomidou.mybatisplus.generator.config.rules.NamingStrategy;
import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
import com.baomidou.mybatisplus.generator.keywords.MySqlKeyWordsHandler;
import org.lwd.microservice.boot.generation.engine.EnhanceFreemarkerTemplateEngine;import java.util.Collections;
import java.util.HashMap;
import java.util.Map;import static com.baomidou.mybatisplus.generator.config.rules.DbColumnType.INTEGER;/*** @author weidong* @version V1.0.0* @description* @since 2023/5/26*/
public class CodeGeneration {public static void main(String[] args) {String projectPath = System.getProperty("user.dir")+"/microservice-boot-middle/microservice-boot-middle-generation"; //获取项目路径String outerFilePath = projectPath + "/src/main/java"; //java下的文件路径String tempFilePath = projectPath + "/src/main/resources";String packageName = "org.lwd.microservice.boot.generation";System.out.println(projectPath);FastAutoGenerator.create(new DataSourceConfig.Builder("jdbc:mysql://" + "127.0.0.1:3306/test", "root", "123456").dbQuery(new MySqlQuery()).typeConvert(new MySqlTypeConvert() {@Overridepublic IColumnType processTypeConvert(GlobalConfig config, String fieldType) {if (fieldType.toLowerCase().contains("tinyint")) {return INTEGER;}return super.processTypeConvert(config, fieldType);}}).keyWordsHandler(new MySqlKeyWordsHandler()))//全局配置.globalConfig(builder -> {builder.outputDir(outerFilePath)//生成的输出路径.author("lwd")//生成的作者名字//.enableSwagger()开启swagger,需要添加swagger依赖并配置.dateType(DateType.ONLY_DATE)//时间策略.commentDate("yyyy-MM-dd")//格式化时间格式.disableOpenDir();//禁止打开输出目录,默认false})//包配置.packageConfig(builder -> {builder.entity("entity")//实体类包名.parent(packageName)//父包名。如果为空,将下面子包名必须写全部, 否则就只需写子包名.controller("controller")//控制层包名.mapper("dao")//mapper层包名.xml("mapper.xml")//数据访问层xml包名.service("service")//service层包名.serviceImpl("service.impl")//service实现类包名.pathInfo(Collections.singletonMap(OutputFile.mapperXml, projectPath + "/src/main/resources/mapper")); //路径配置信息,就是配置各个文件模板的路径信息,这里以mapper.xml为例})//模版配置.templateConfig(builder -> {
// builder.disable()//禁用所有模板
// builder.disable(TemplateType.ENTITY)builder.service("templates/service.java")//service模板路径.serviceImpl("templates/serviceImpl.java")//实现类模板路径
// .mapper("templates/mapper.java")//mapper模板路径
// .mapperXml("/templates/mapper.xml")//xml文件模板路路径.controller("templates/controller.java"); //controller层模板路径}).templateEngine(new FreemarkerTemplateEngine()).injectionConfig(consumer -> {Map<String, String> customFile = new HashMap<>();// DTO 下面的key会作为类名后缀,进而生成新类customFile.put("DTO.java", "templates/other/dto.java.ftl");customFile.put("VO.java", "templates/other/vo.java.ftl");customFile.put("Convertor.java", "templates/other/convertor.java.ftl");consumer.customFile(customFile);}).templateEngine(new EnhanceFreemarkerTemplateEngine())// EnhanceFreemarkerTemplateEngine 里主要重写对自定义类的处理 如vo dto convert等//策略配置开始.strategyConfig(builder -> {builder.enableCapitalMode()//开启全局大写命名//.likeTable()模糊表匹配.addInclude("t_friendly_link")//添加表匹配,指定要生成的数据表名,不写默认选定数据库所有表//.disableSqlFilter()禁用sql过滤:默认(不使用该方法)true//.enableSchema()启用schema:默认false.addTablePrefix("t_")//增加过滤表前缀.entityBuilder() //实体策略配置//.disableSerialVersionUID()禁用生成SerialVersionUID:默认true.enableChainModel()//开启链式模型.enableLombok()//开启lombok.enableRemoveIsPrefix()//开启 Boolean 类型字段移除 is 前缀.enableTableFieldAnnotation()//开启生成实体时生成字段注解//.addTableFills()添加表字段填充.naming(NamingStrategy.underline_to_camel)//数据表映射实体命名策略:默认下划线转驼峰underline_to_camel.columnNaming(NamingStrategy.underline_to_camel)//表字段映射实体属性命名规则:默认null,不指定按照naming执行.idType(IdType.AUTO)//添加全局主键类型.formatFileName("%s")//格式化实体名称,%s取消首字母I.logicDeleteColumnName("deleted_tag")//逻辑删除标识.mapperBuilder()//mapper文件策略.enableMapperAnnotation()//开启mapper注解.enableBaseResultMap()//启用xml文件中的BaseResultMap 生成.enableBaseColumnList()//启用xml文件中的BaseColumnList//.cache(缓存类.class)设置缓存实现类.formatMapperFileName("%sMapper")//格式化Dao类名称.formatXmlFileName("%sMapper")//格式化xml文件名称.serviceBuilder()//service文件策略.formatServiceFileName("%sService")//格式化 service 接口文件名称.formatServiceImplFileName("%sServiceImpl")//格式化 service 接口文件名称.controllerBuilder()//控制层策略//.enableHyphenStyle()开启驼峰转连字符,默认:false.enableRestStyle()//开启生成@RestController.formatFileName("%sController");//格式化文件名称}).execute();}}
代码地址
https://github.com/OrderDong/microservice-boot
分支:microservice-boot-1.0.1-generator
模块:microservice-boot-middle-generation
外传
😜 原创不易,如若本文能够帮助到您的同学
🎉 支持我:关注我+点赞👍+收藏⭐️
📝 留言:探讨问题,看到立马回复
💬 格言:己所不欲勿施于人 扬帆起航、游历人生、永不言弃!🔥