郴州网站建设企业淄博建企业网站
建设背景
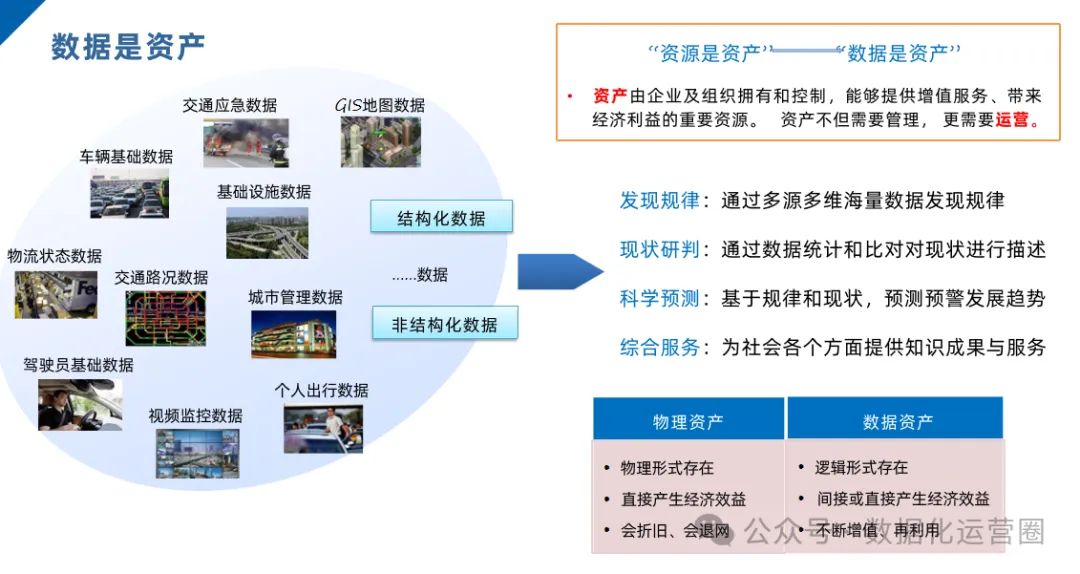
(1)什么是数据资产
资产由企业及组织拥有和控制,能够提供增值服务、带来经济利益的重要资源。 资产不但需要管理, 更需要运营。
(2)数据资产运营中的问题
数据资产运营中存在的问题主要包括以下几个方面:
分散管理:传统的烟囱式建设模式导致系统林立,数据分散并且封闭,缺乏集中的数据管理和共享机制。
数据重复存放:为了支撑应用,相同的数据在不同系统之间重复存放,造成资源的浪费。
数据共享困难:系统间接口繁多,实现复杂度高,且可靠性难以保证,导致数据共享难以实现。
数据质量不高:数据整体质量不高,监管机制不健全,缺乏面向数据质量的评估机制和数据质量的服务。
数据安全难以控制:缺乏有效的数据安全管理机制,对敏感信息、隐私信息、保密信息的访问缺乏有效控制。
数据标准不统一:缺乏统一的数据标准,无法有效避免数据混乱冲突,导致一数多源、多样多类等问题。
数据开放共享的价值未充分利用:数据开放共享能够打破厂商垄断数据的局面,形成开放的生态格局,但目前尚未充分发挥其价值。
数据资产管理与企业IT信息化过程脱节:对数据资产的管理不仅仅是建设一套IT系统,更需要相应管理手段的跟进,以确保数据资产的好用、实用,真正体现数据作为资产的价值。
大数据治理平台业务需求
大数据治理平台方案是一个综合性的解决方案,旨在通过平台加服务的模式,支持不同行业的用户构建一个全面且高效的数据资产管控环境。通过统一数据标准、数据整合与治理,确保数据安全,实现跨系统、跨部门、跨层级和跨地区的数据共享与开放。
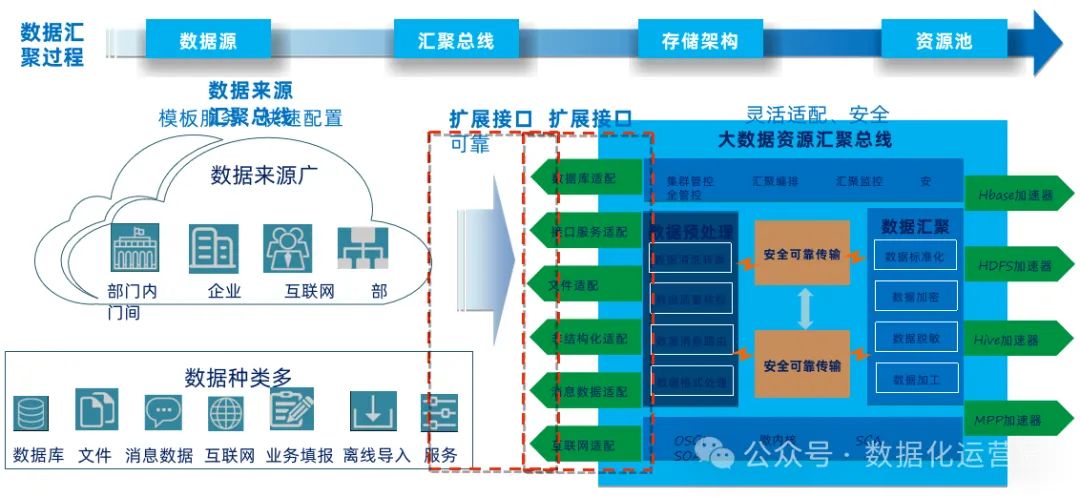
其涵盖了数据资产全生命周期管理的各个方面,包括数据采集、清洗加工、质量管理、开放共享等环节,并提供了数据共享交换平台、主数据管理、数据质量管理和数据安全管控等核心功能。此外,该方案还包括了数据资源目录管理、数据交换传输系统、数据资产管理、数据建模、数据整合、数据维护等一系列工具和功能,以促进数据资源的高效利用和价值最大化。
核心功能需求
大数据治理平台应当具备一套全面的功能,以确保数据的有效管理和利用。其需要实现数据的集中管理,通过统一的数据标准和架构来整合分散的数据资源。平台应提供数据质量管理工具,以评估、监控和提升数据的准确性、完整性和一致性。同时,数据共享交换功能也是必不可少的,它允许跨系统和组织的数据流通和共享,同时确保数据的安全性和合规性。
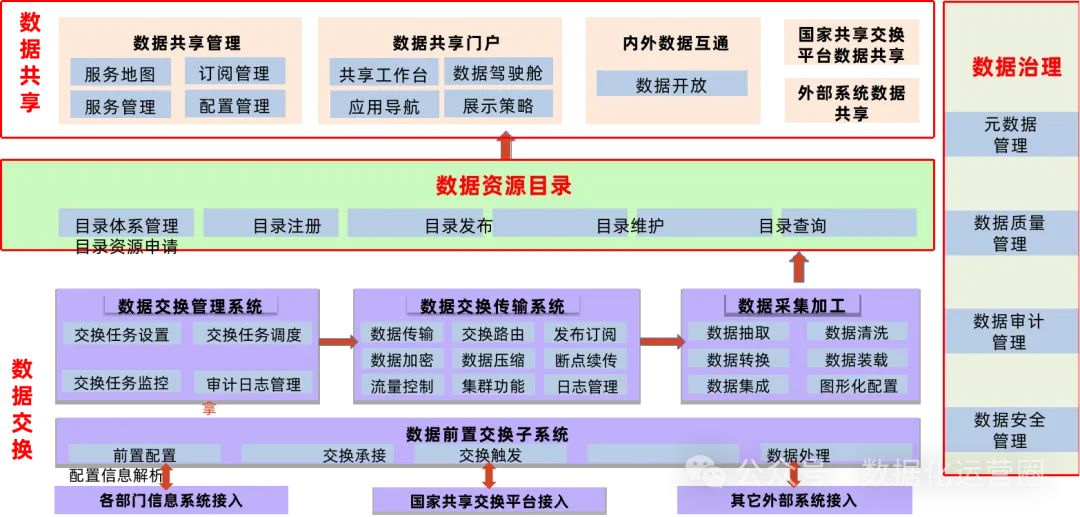
大数据治理平台应该包含强大的数据安全管控措施,如数据加密、脱敏、访问控制和审计追踪,以防止数据泄露和滥用。应该支持数据的全生命周期管理,从数据的采集、清洗、转换到存储、分析和最终的退役处理。数据建模和元数据管理也是关键组成部分,它们帮助用户理解和利用数据资产的结构和关系。
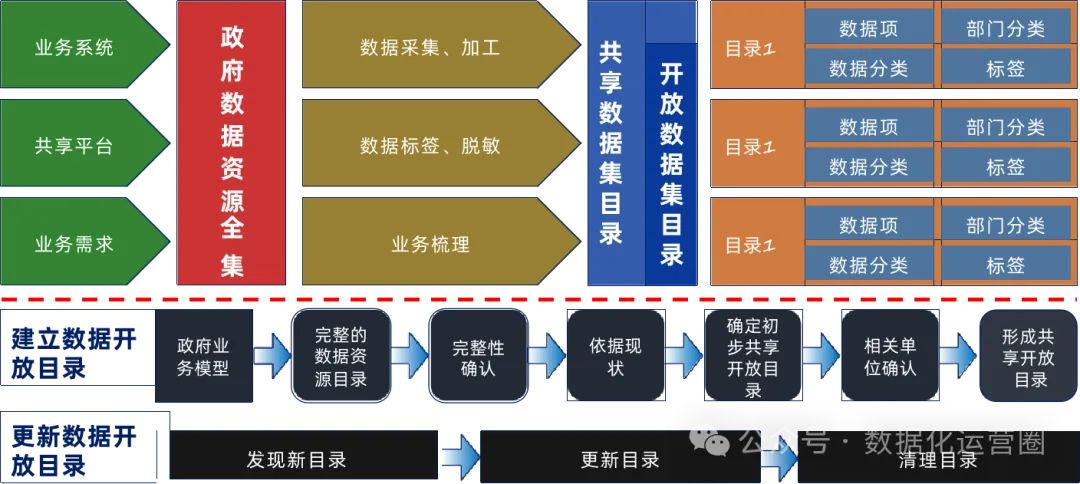
平台应该提供数据资产目录,使得数据资源的发现和访问变得更加容易。数据服务层的构建可以促进数据API的创建和数据产品的开发,从而支持业务创新和决策制定。最后,大数据治理平台还应该具备高度的可扩展性和灵活性,以适应不断变化的业务需求和技术环境,确保长期的可持续发展。
平台的价值
大数据治理平台是企业数字化战略的基石,其通过一系列综合功能,可以确保数据在整个生命周期中的质量和安全,从而提升数据的准确性、完整性和一致性。平台能够促进数据的共享与交换,打破信息孤岛,实现数据的集中管理和高效利用,通过自动化的流程提高运营效率,降低成本。通过大数据治理平台,可以使数据支持业务决策,为业务提供数据支持,帮助企业快速适应市场变化,做出更加明智的决策。
大数据治理平台强化了合规性和风险管理,确保数据治理遵循法律法规,及时识别和应对数据安全风险。通过建立数据信任,它增强了利益相关者对企业数据管理能力的信心,为数字化转型提供了坚实的数据基础,推动企业在数据驱动的商业环境中保持竞争优势。