自己做的网站怎么添加文档创网站
有时候忘记了网站的密码,又不想“忘记密码”去一番折腾。如果你正好用的是 chrome 浏览器。
那么根本就没必要折腾,直接就能看到网站密码。
操作如下
1.在浏览器右上角点击三个小点:
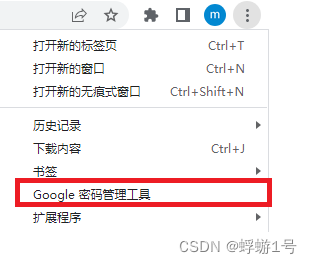
2.点这三个点:

3.选择“显示密码”,左侧的密码就可以看到了。
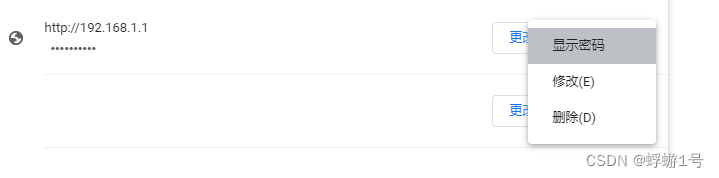
输入电脑密码就可以看了,我的密码就不给大家看了。
如果你的浏览器不是 chrome ,不一定有这个选项,只能选择重新设置密码了。
隐患
chrome 之所以提供这个功能,和 chrome 的网站密码被破解有关。早期可以用 python 脚本,写代码直接获取 chrome 的网站密码。
但是,密码获取存在巨大隐患。
普通人在不之情的情况下,直接复制粘贴 python 脚本运行。虽然可以获取密码,但更可能是把代码发给了黑客。因为只要在脚本里夹杂几行代码,就可以轻松将密码通过网络发出去。
这种获取密码的方式太容易了。你的淘宝,京东,亚马逊,支付宝,只要你登录过的网站,甚至你自己都不记得猴年马月在浏览器上输入过的支付密码,通通都会一次性全部发送给黑客。
危险的邮件
举个例子,我(黑客)通过邮件的方式,将脚本隐藏,发送邮件,比如生日祝福,或者 offer ,总之用户可能感兴趣的东西。
用户看到邮件里有个链接,用户出于好奇,点击图片放大看一下(图片就是链接),python 脚本就被下载安装到电脑上了。可能会在桌面显示一个好看的美女图,或者可爱的小狗图像。
用户习惯性双击一下桌面图像。这下好了,脚本运行,将 chrome 的密码通过网络发送出去(当然就是发给黑客邮箱或者电脑了)。所以,这种脚本及其危险。
后来浏览器更新到 80 版本以后,限制了这个功能。但又被破解了,网上还是可以找到破解方式。
如何避免自己的密码泄露?
- 不要乱点未知链接。链接就是入口,没有入口,黑客也要头疼。图片,文字都可能是链接。
- 不要在浏览器设置“下载后自动安装”。自动安装常常会给你安装一堆流氓软件。运气好的话,流氓软件可能没毒,但是软件里面的链接就不能确定了。运气不好,流氓软件直接就让你电脑崩溃了。
- 定期清理浏览器网站密码。这提高了一点技术含量,简单来说就是清空网站密码。只有记在脑子里的密码才是密码。
- 换掉 chrome。也是个办法,毕竟其它浏览器密码获取没有披露出来。但根本上还是要提高自我安全意识。