什么叫H5网站开发天津网络推广公司
一 外设封装结构
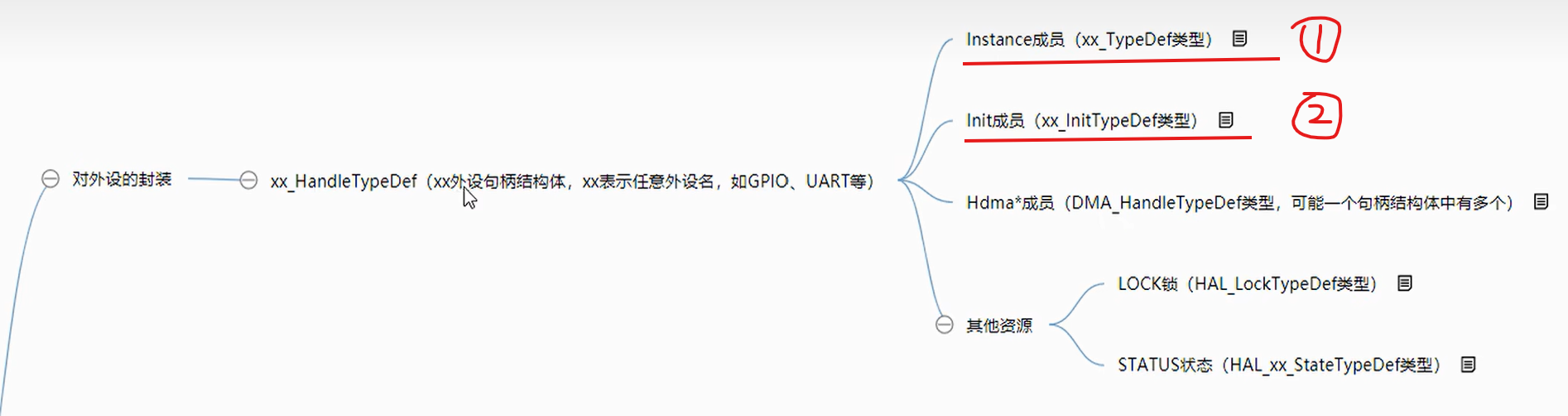
HAL库对外设的封装使用了xx_HandleTypeDef类型的外设句柄结构体,这个句柄结构体的第一个成员Instance(xx_TypeDef类型)一般为该外设的所有寄存器的起始基地址,第二个成员Init(xx_InitTypeDef类型)一般为该外设的设置的需要设置的参数,以CAN 模块举例说明:
typedef struct
{
CAN_TypeDef *Instance; /*!< Register base address */
① 第一个变量是一个指针*Instance,类型为CAN_TypeDef,如下,其实是所有CAN外设的寄存器的集合:
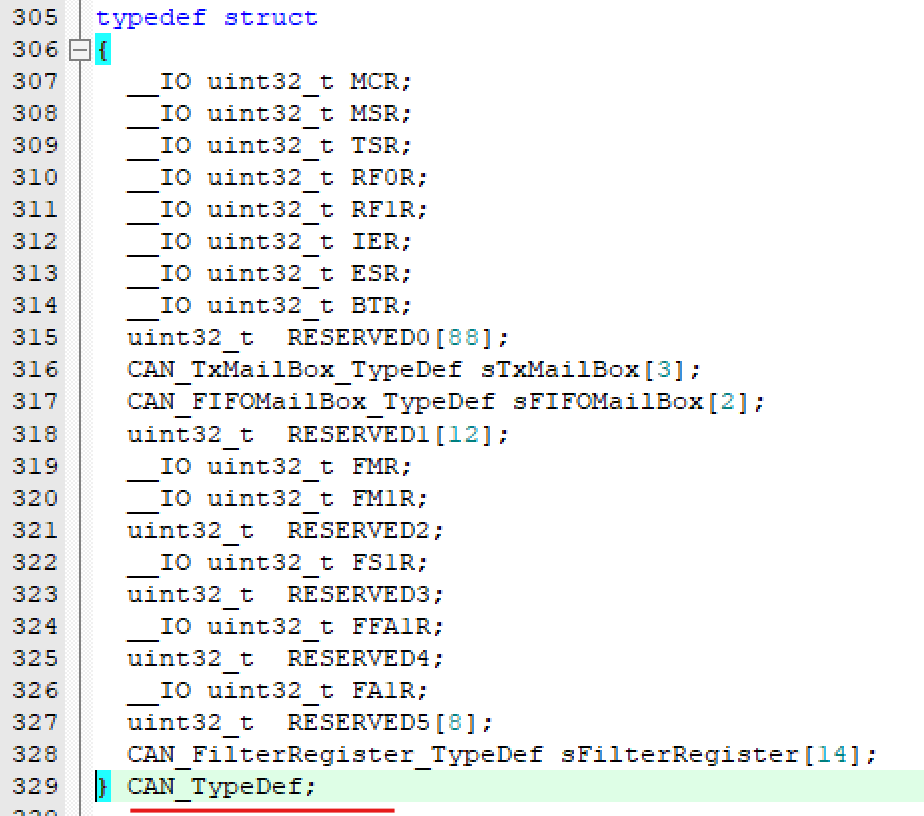
在初始化外设函数HAL_xx_INIT()执行之前时,HAL将这个变量(指针)赋值为该外设的基地址

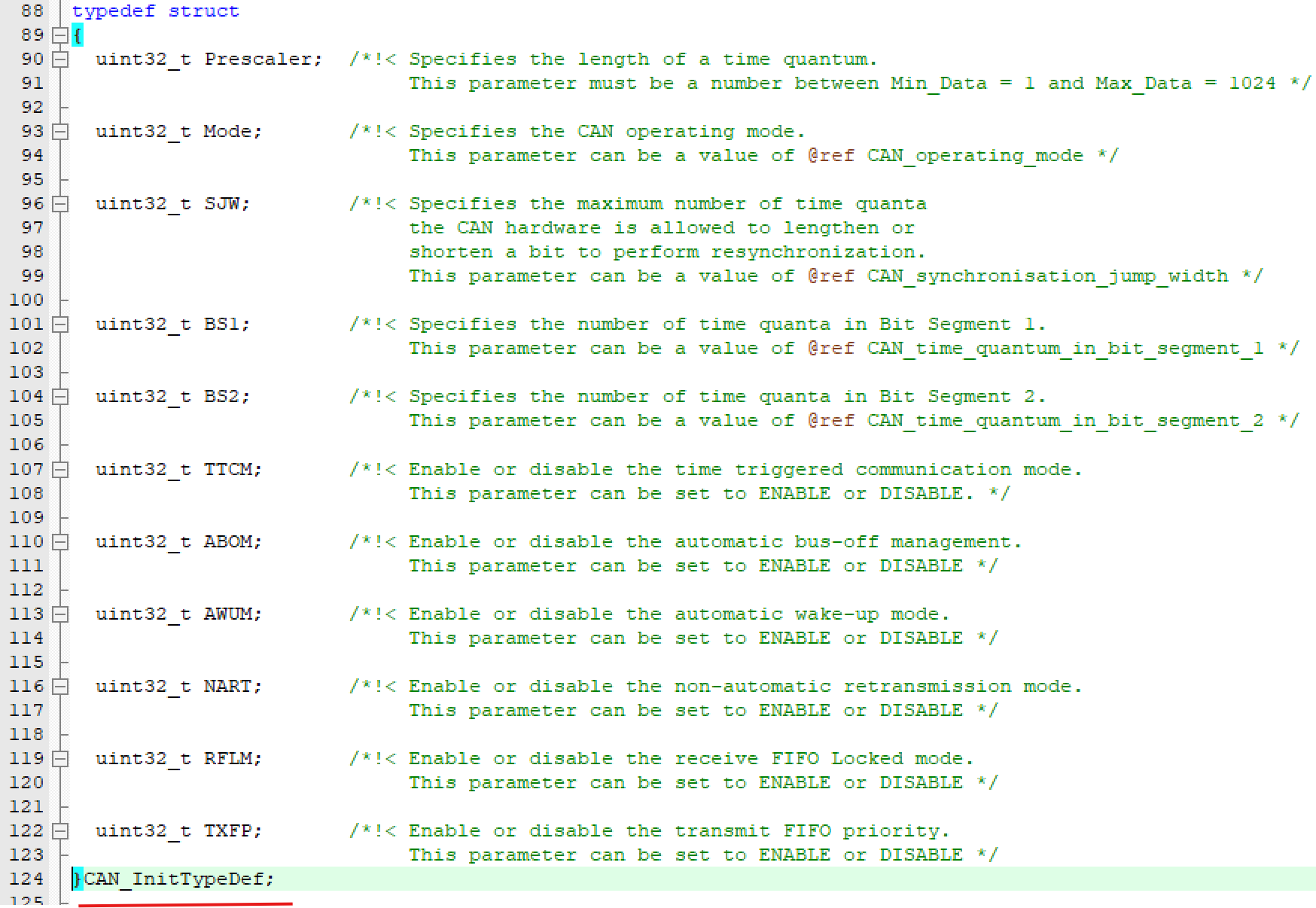
CAN_InitTypeDef Init; /*!< CAN required parameters */
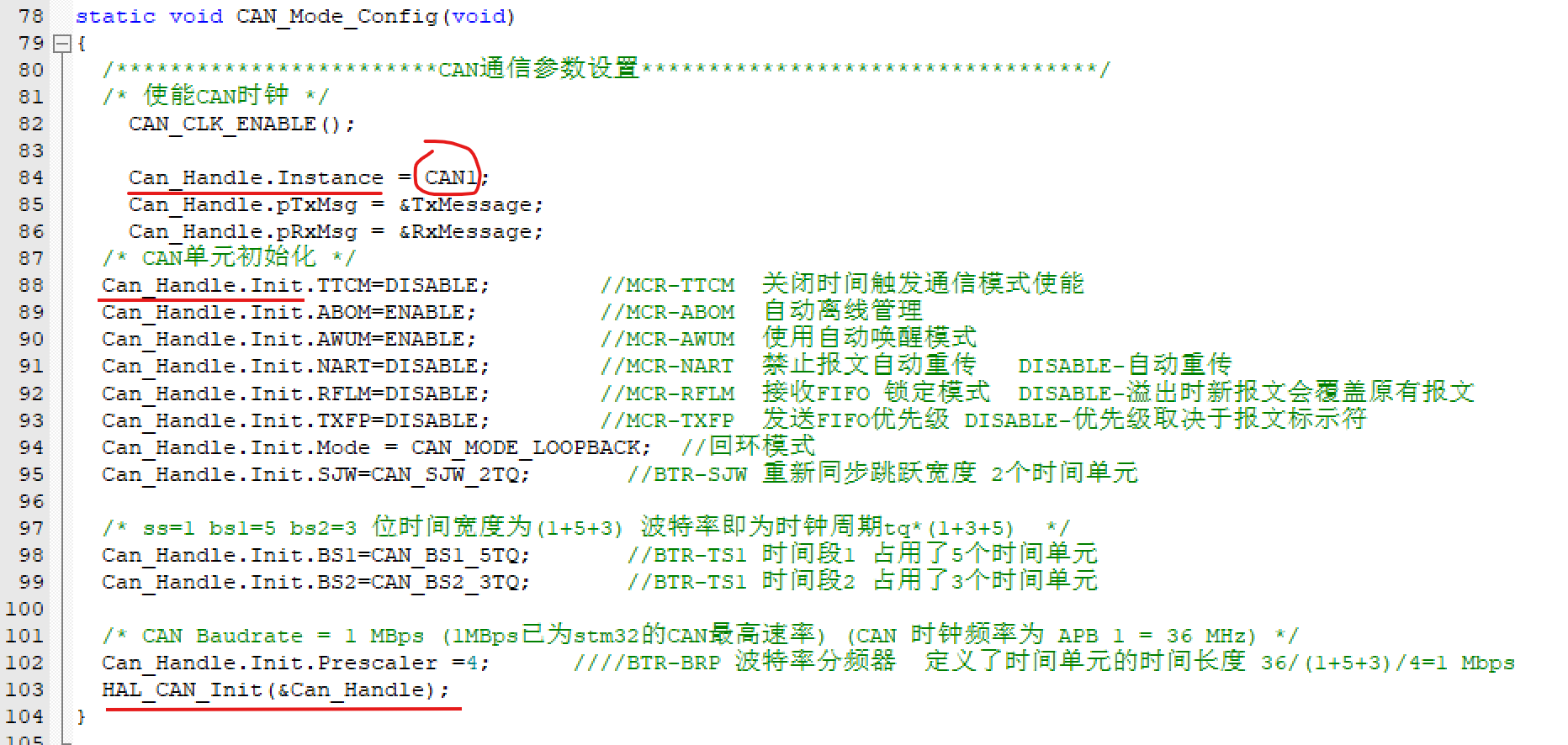
② 第二个变量一般为结构体Init,这个结构体是一个很多参数的集合如下图,在初始化外设函数HAL_xx_INIT()执行之前时,HAL会将外设结构体句斌的Init成员的这些参数赋值,
最终HAL会在HAL_xx_INIT()执行时把这些参数赋值到第一个变量代表的地址中
CanTxMsgTypeDef* pTxMsg; /*!< Pointer to transmit structure */
CanRxMsgTypeDef* pRxMsg; /*!< Pointer to reception structure for RX FIFO0 msg */
CanRxMsgTypeDef* pRx1Msg; /*!< Pointer to reception structure for RX FIFO1 msg */
__IO HAL_CAN_StateTypeDef State; /*!< CAN communication state */
HAL_LockTypeDef Lock; /*!< CAN locking object */
__IO uint32_t ErrorCode; /*!< CAN Error code */
}CAN_HandleTypeDef;
二 如果该外设有其他的附加功能参数
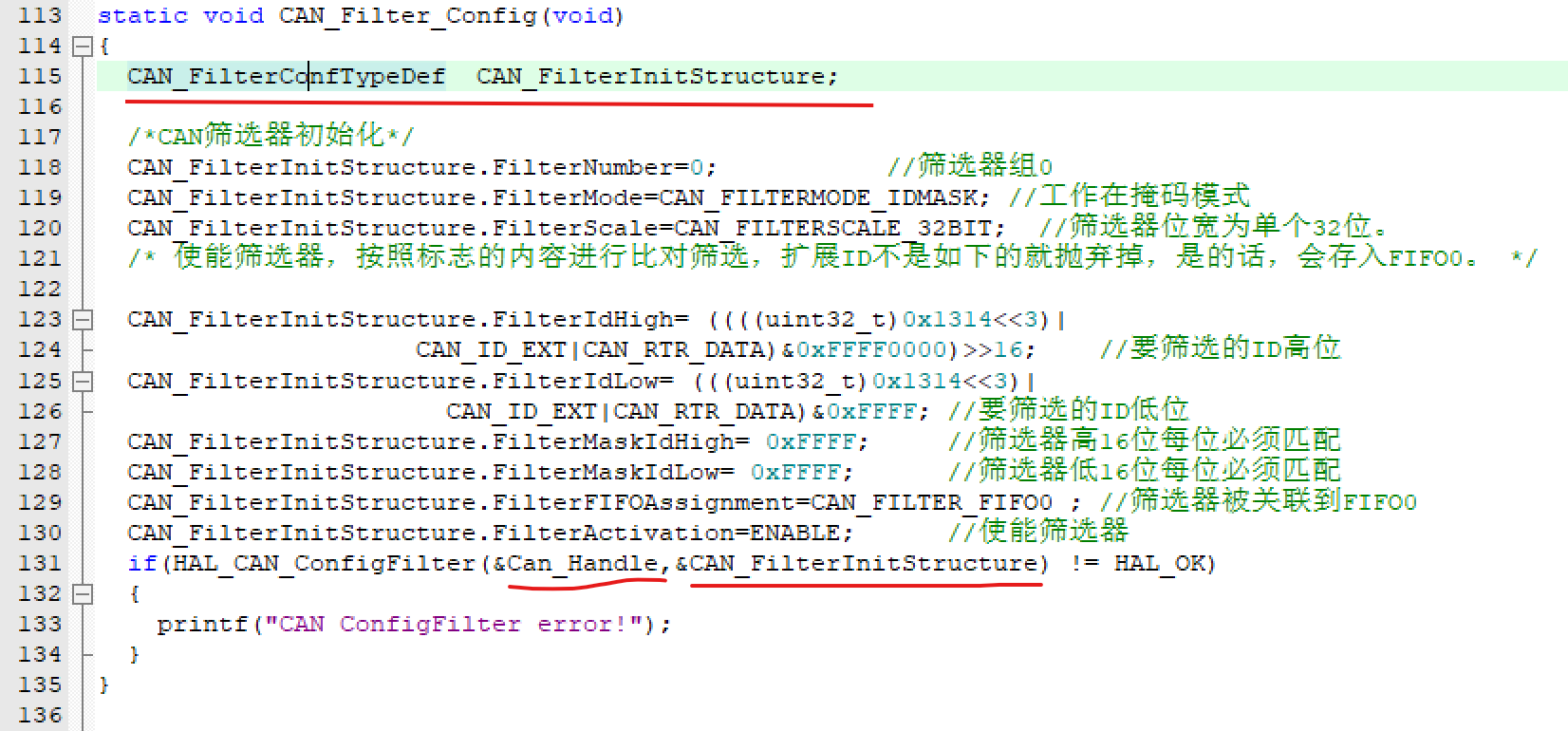
比如CAN外设有过滤器,并有相应的过滤器寄存器参数,也是以同样的方式将这个过滤器的相关参数赋值到第一个变量代表的基地址的寄存器里,如下图:
CAN外设过滤器结构体参数:

将过滤器参数赋值到CAN外设句柄的第一个变量指示的地址