网站建设哪里最好接单子做网站办公室图片
🚀简介
组合模式又名部分整体模式,是一种 结构型设计模式 ,是用于把一组相似的对象当作一个 单一的对象 。组合模式 依据树形结构来组合对象 ,用来表示部分以及整体层,它可以让你将对象组合成树形结构,并且能 像使用独立对象一样使用它们 。这种模式定义了包含人和组的类,每个组都可以包含人或者是其他的组。这样的结构可以有效地代表大的和复杂的层次结构。
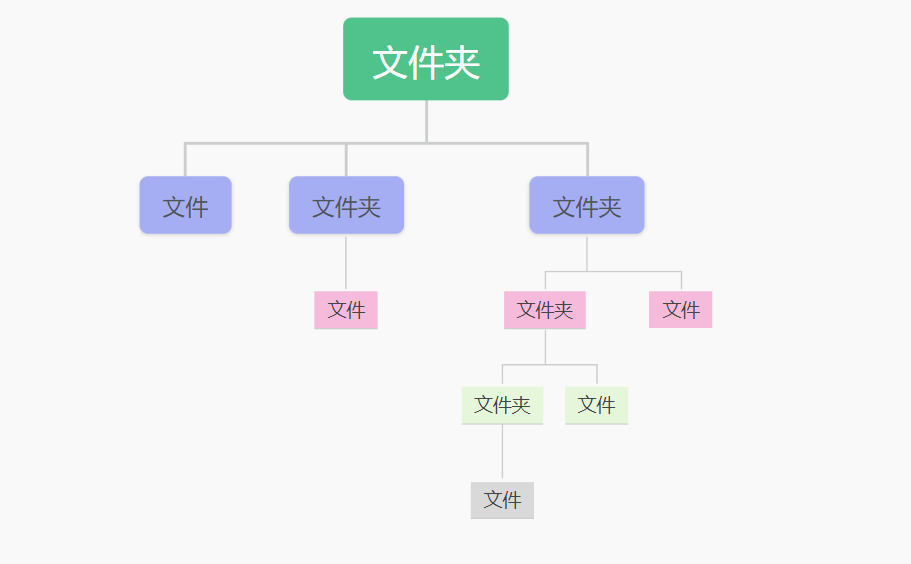
🐤如上图,是我们常见的 文件系统 ,对于这样的结构我们称之为 树形结构 。在树形结构中可以通过调用某个方法来遍历整个树,当我们找到某个叶子节点后,就可以对叶子节点进行相关的操作。可以将这颗树理解成一个大的容器, 容器 里面 包含很多的成员对象 ,这些成员对象即可是容器对象也可以是叶子对象。但是由于容器对象和叶子对象在功能上面的区别,使得我们在使用的过程中必须要区分容器对象和叶子对象,但是这样就会给客户带来不必要的麻烦,作为客户而已,它始终希望能够一 致的对待容器对象和叶子对象 。
👻角色
组合模式主要包含三种角色:
- 抽象根节点(Component):定义系统各层次对象的共有方法和属性,可以预先定义一些默认行为和属性。
- 树枝节点(Composite):定义树枝节点的行为,存储子节点,组合树枝节点和叶子节点形成一个树形结构。
- 叶子节点(Leaf):叶子节点对象,其下再无分支,是系统层次遍历的最小单位。
🐳与我们上图中文件系统图例对应
- 抽象根节点 = 最顶部的文件夹
- 树枝节点 = 文件夹
- 叶子节点 = 文件
🚀案例
不管是菜单还是菜单项,都应该继承自统一的接口,这里我们创建一个抽象组件,定义一些通用的方法,如添加,删除,打印。
public abstract class Component
{protected string _name;public Component(string name){_name = name;}public abstract void Add(Component c);public abstract void Remove(Component c);public abstract void Display(int depth);
}🚀树枝节点Composite
定义一个名为children的List类型的列表,用于存储Component类型的子元素,Add方法和Remove方法分别用于向children列表中添加和移除Component类型的对象。Display方法用于显示Composite对象的信息。这个方法首先打印出当前Composite对象的深度和名称,然后遍历children列表,对每个子元素调用Display方法。这样就形成了一种递归的结构,可以用来表示树形结构。
public class Composite : Component
{private List<Component> children = new List<Component>();public Composite(string name): base(name){}public override void Add(Component component){children.Add(component);}public override void Remove(Component component){children.Remove(component);}public override void Display(int depth){Console.WriteLine(new String('-', depth) + _name);foreach (Component component in children){component.Display(depth + 2);}}
}🚀叶子节点Leaf
因为叶子节点已经是最下级了,因此我们只需要在Display直接重写打印方法,并且不需要再进行遍历了
public class Leaf : Component
{public Leaf(string name): base(name){}public override void Add(Component c){Console.WriteLine("Cannot add to a leaf");}public override void Remove(Component c){Console.WriteLine("Cannot remove from a leaf");}public override void Display(int depth){Console.WriteLine(new String('-', depth) + _name);}
}🐳测试
class MyClass
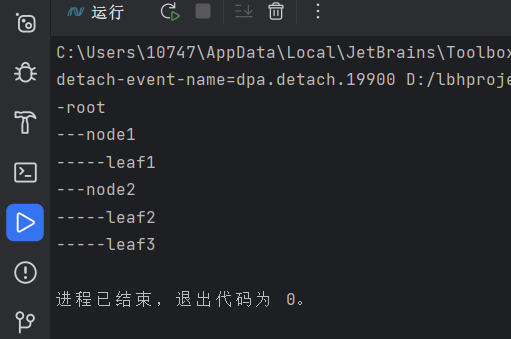
{public static void Main(string[] args){// 创建一个根节点Component root = new Composite("root");// 创建两个节点Component node1 = new Composite("node1");Component node2 = new Composite("node2");// 创建叶子节点Component leaf1 = new Leaf("leaf1");Component leaf2 = new Leaf("leaf2");Component leaf3 = new Leaf("leaf3");// 构建树形结构root.Add(node1);root.Add(node2);node1.Add(leaf1);node2.Add(leaf2);node2.Add(leaf3);// 显示树形结构root.Display(1);}
}运行结果!在这个例子中,我们首先创建了一个根节点root,然后创建了两个节点node1和node2,以及三个叶子节点leaf1,leaf2和leaf3。然后我们将node1和node2添加到root下,将leaf1添加到node1下,将leaf2和leaf3添加到node2下,从而构建了一个树形结构。
🚀总结
👻优点
- 组合模式可以清楚地定义分层次的复杂对象,表示对象的全部或部分层次,它让客户端忽略了层次的差异,方便对整个层次结构进行控制。
- 客户端可以一致地使用一个组合结构或其中单个对象,不必关心处理的是单个对象还是整个组合结构,简化了客户端代码。
- 在组合模式中增加新的树枝节点和叶子节点都很方便,无须对现有类库进行任何修改,符合“开闭原则”。
- 组合模式为树形结构的面向对象实现提供了一种灵活的解决方案,通过叶子节点和树枝节点的递归组合,可以形成复杂的树形结构,但对树形结构的控制却非常简单。
👻缺点
在使用组合模式时,其叶子和树枝的声明都是实现类,而不是接口,违反了依赖倒置原则。
👻使用场景
组合模式正是应树形结构而生,所以组合模式的使用场景就是出现树形结构的地方。比如:文件目录显示,多级目录呈现等树形结构数据的操作。