建筑师网站有哪些excel做网站链接
预制体作用: 更改预制体,则更改全部的以预制体复制出的模型。
生成预制体: 当你建立好了一个模型,从层级拖动到项目中即可生成预制体。
预制体复制模型: 将项目中的预制体拖动到层级中即可复制。或者选择物体复制粘贴。
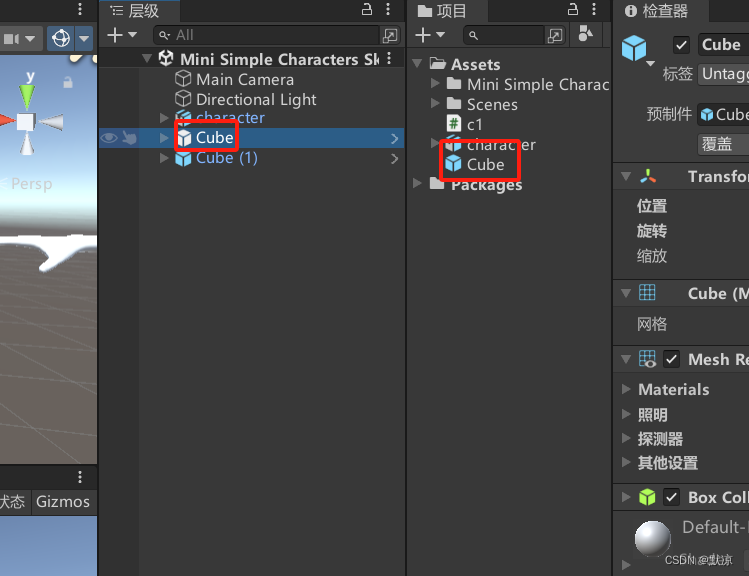
变体:根据预制体调整后的一种预制体。
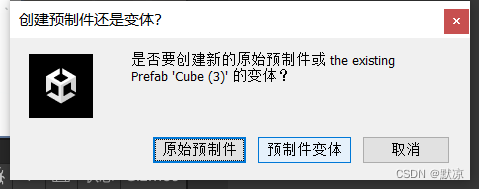
选择预制件变体
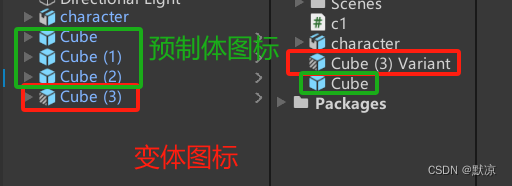
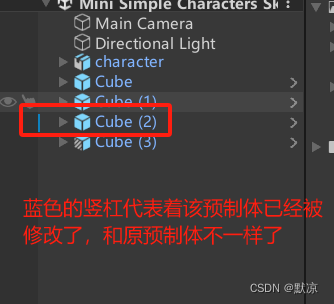
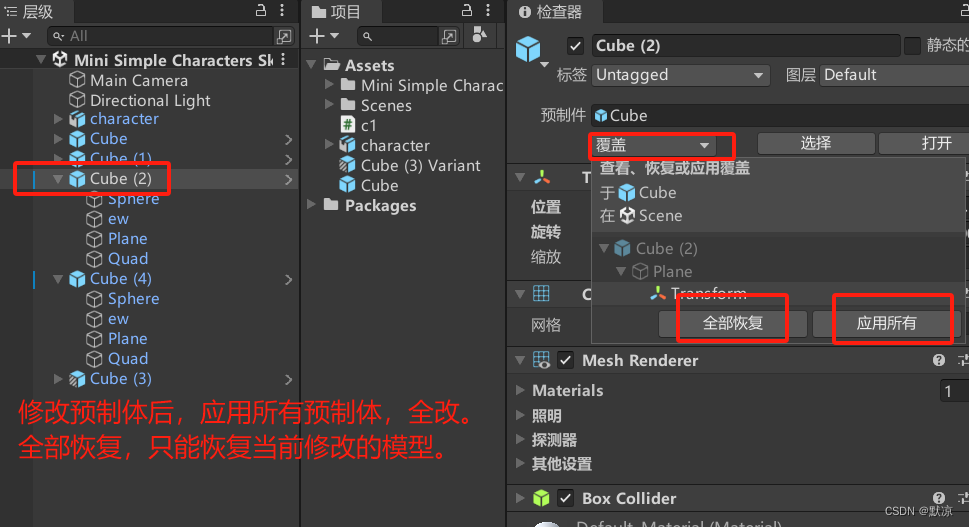
更改场景中所有已经放置好的预制体模型
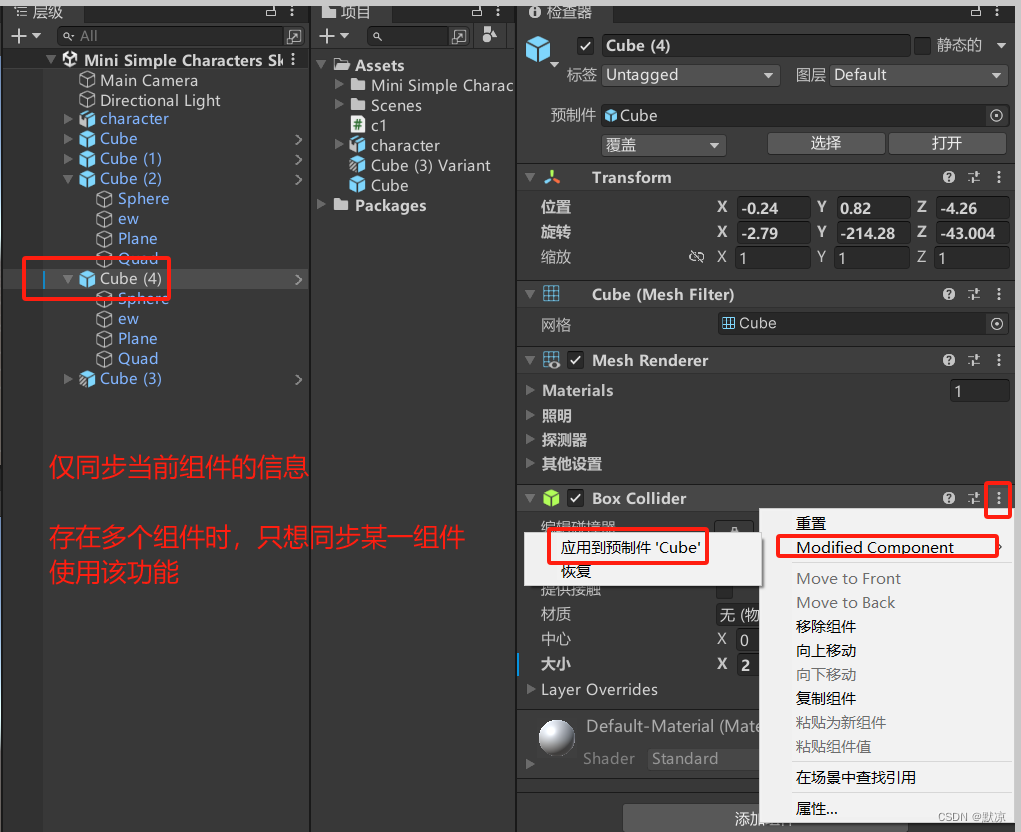
仅同步某几个组件的方法
预制体作用: 更改预制体,则更改全部的以预制体复制出的模型。
生成预制体: 当你建立好了一个模型,从层级拖动到项目中即可生成预制体。
预制体复制模型: 将项目中的预制体拖动到层级中即可复制。或者选择物体复制粘贴。
变体:根据预制体调整后的一种预制体。
选择预制件变体
更改场景中所有已经放置好的预制体模型
仅同步某几个组件的方法